Stochastic-Gradient MCMC
From the Ma–Chen–Fox complete recipe to SGLD, SGHMC, RSGLD, and the head-to-head with NUTS — a unified Itô-SDE treatment of scalable Bayesian posterior sampling.
1. Overview & Motivation
The point of bayesian-neural-networks was to put a posterior on the weights of a deep network. Five of the eight methods we developed there were either approximations to the posterior (Laplace, MC-dropout, deep ensembles) or local tricks (calibration, NNGP/NTK). Two were exact-in-the-limit posterior samplers: stochastic-gradient Langevin dynamics (SGLD, BNN §6) and stochastic-gradient Hamiltonian Monte Carlo (SGHMC, BNN §7). Both arrived as recipes — write down an update rule, calibrate the noise, run the chain. The recipes work, but BNN didn’t tell us why they work.
This topic is the answer. The throughline is that SGLD and SGHMC are not two unrelated tricks but two instantiations of a single object: a stochastic differential equation whose stationary distribution is the posterior we want to sample. Once we accept that frame, three things follow at once. The asymptotic exactness of SGLD becomes a Fokker–Planck calculation. The momentum trick in SGHMC becomes the underdamped version of the same SDE. And every other SG-MCMC method that ever shipped — Riemann-manifold variants, control-variate variants, thermostat methods — drops out of a single skew-symmetric matrix decomposition due to Ma, Chen, and Fox (2015).
That’s the headline. Below it sit four secondary questions this topic resolves:
- What does the mini-batch gradient cost us? SGLD’s update rule replaces the full-data gradient with a mini-batch estimate. This is the only reason the method scales, but it injects extra noise into the SDE. Vollmer, Zygalakis, and Teh (2016) gave the finite-sample bias bound: under regularity, . We work that bound out and show what it means in practice.
- When does SGHMC actually beat SGLD? The momentum extension is more expensive per step. We characterize the friction–noise trade-off (Chen, Fox, and Guestrin 2014) and pin down the regime where SGHMC’s faster mixing pays for its higher cost — anisotropic posteriors with badly-conditioned curvature.
- What about hierarchical models like Neal’s funnel? The same funnel that motivated probabilistic-programming’s non-centered reparameterization breaks SGLD and SGHMC alike, for the same geometric reason. The fix is to replace the Euclidean metric with the Fisher information — Riemann-manifold SG-MCMC (Patterson and Teh 2013; Ma, Chen, and Fox 2015). We derive the correction term and demonstrate the speedup.
- When should I reach for SG-MCMC over NUTS? Closed answer at the end of the topic, with a head-to-head ESS-per-second comparison on a Bayesian logistic regression as grows from to . NUTS dominates at small ; SG-MCMC dominates once full-batch gradients become the bottleneck.
1.1 What we cover
§§2–4 set up the SDE machinery: the complete-recipe framework that organizes the rest of the topic, an Itô-SDE primer (self-contained because formalcalculus has not yet published its SDE topic), and the Fokker–Planck calculation that proves a given SDE has the posterior as its stationary distribution. §§5–7 develop overdamped Langevin → SGLD and underdamped Langevin → SGHMC, with the stationary-distribution proofs reused from §4. §§8–9 quantify the price of mini-batching and present the strategies that buy bias back at controlled cost. §10 extends the framework to Riemann manifolds and demonstrates on Neal’s funnel. §11 ships the implementation details (per-method step functions, hyperparameter recipes, ESS/IAT diagnostics) as the foundations-track Computational Notes section. §12 puts SG-MCMC head-to-head with NUTS and articulates when each wins. §13 collects connections and forward pointers.
1.2 Prerequisites
The reader is expected to have read bayesian-neural-networks at least through §7 (so the SGLD and SGHMC update rules are familiar as recipes, even if the underlying SDE theory is not). probabilistic-programming §§4–5 (NUTS, the centered/non-centered funnel) is helpful for §12 and the §10 Neal’s-funnel demo but is not strictly required. From the sister sites we lean on formalstatistics’s bayesian-computation-and-mcmc (the deep prerequisite — what makes an MCMC method correct and how to read mixing diagnostics) and basic familiarity with stochastic processes (Brownian motion, the difference between an ODE and an SDE). Itô calculus itself is not assumed; §3 covers the minimum.
2. The complete-recipe lens
Before we develop SGLD or SGHMC in detail, we need to understand what they have in common — and what every other SG-MCMC method that has ever shipped also has in common. The unifying object is a single SDE template parametrized by two matrix-valued functions: a positive semi-definite diffusion and a skew-symmetric drift modifier . Different choices of yield SGLD, SGHMC, RMHMC, RSGLD, thermostats, and more, with the same proof of stationarity covering all of them. The result is due to Ma, Chen, and Fox (2015), and we lean on it heavily for the rest of the topic.
2.1 The general posterior-targeting SDE template
Let be the target distribution we want to sample. For the Bayesian posterior, — the negative log-prior plus the sum of negative log-likelihoods over the dataset, up to an additive constant. We will call the energy of the target, borrowing the physics convention; statisticians sometimes call it the negative log-posterior. Either way, is the quantity that drives the dynamics.
We are looking for an Itô SDE of the form
whose stationary distribution is exactly . Here is standard Brownian motion in (we develop this object from scratch in §3), is positive semi-definite at every point, and is any matrix square root (e.g., a Cholesky factor — the choice does not affect the law of , only its sample path). The drift is what we are solving for.
The continuous-time SDE in (2.1) is the object whose stationarity we will prove. SGLD and SGHMC are what we get when we discretize (2.1) with Euler–Maruyama and replace with a mini-batch estimator. We work that side of the story out in §§5–7.
2.2 The Ma–Chen–Fox skew decomposition
Here is the headline.
Theorem 2.1 (Ma–Chen–Fox 2015).
Let be positive semi-definite and be skew-symmetric, both smooth in . Define the drift
where the correction term has components
Then is a stationary distribution of the SDE in (2.1) with this drift.
The proof is a Fokker–Planck calculation. We carry it out in §4.3 once we have the Fokker–Planck operator in hand; the argument is short but it requires the machinery from §3 and §4 to make any sense, so we defer it. For now, the takeaway is that the criterion for stationarity is purely algebraic: pick a and a with the stated symmetry, compute by differentiating their entries, and you have an SDE with stationary distribution .
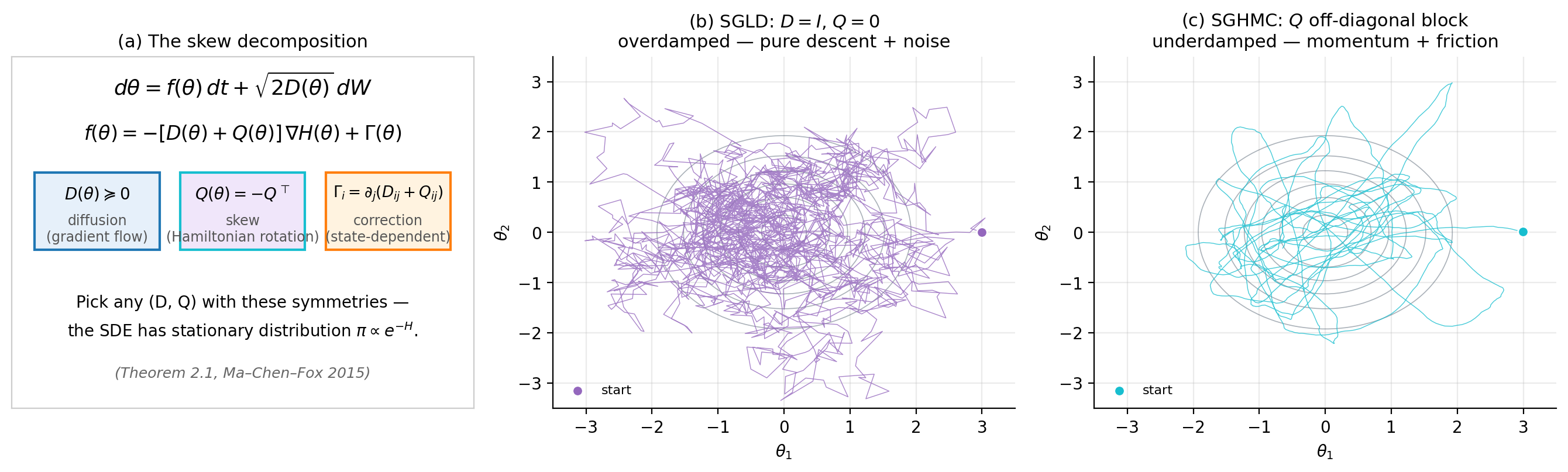
A few things deserve immediate comment. The term is the gradient-flow part: it pulls toward high-density regions, much like ordinary gradient descent on . The term is the Brownian noise that prevents collapse to the mode and makes the dynamics ergodic. The term and the correction together produce the Hamiltonian part of the dynamics — the rotational, momentum-like behavior we will see in SGHMC. When , the dynamics reduce to gradient flow plus noise (this is SGLD). When , we get rotation around level sets of , which mixes much faster on anisotropic targets but costs more per step.
Skew-symmetry of is what makes the theorem work — a symmetric would break stationarity. Why? In the Fokker–Planck calculation (§4.3), enters via a divergence term that integrates to zero precisely when . We give the calculation in §4 once we have the Fokker–Planck operator; for now, take the skew condition as a mathematical requirement that emerges from the proof and not as a modeling choice.
2.3 Three instantiations
The whole topic is, in a real sense, a tour of three choices of .
SGLD. Take , the identity, and . Then (constant matrix entries have zero derivative), and . The SDE is
This is overdamped Langevin dynamics. Discretizing with Euler–Maruyama gives the SGLD update from BNN §6.2. We develop this case in §§5–6.
SGHMC. Now expand the state to with playing the role of momentum, and choose
where is a friction matrix and is a mass matrix (both positive definite). The marginal of the joint stationary over is exactly the target posterior on . The drift in this expanded state space gives the second-order underdamped Langevin dynamics of Chen, Fox, and Guestrin (2014). We develop this case in §7.
RMHMC and RSGLD. Replace the constant in SGLD with a state-dependent , where is the Fisher information metric (or any other positive-definite metric on parameter space). The correction term becomes nonzero — that’s the famous correction in Riemann-manifold methods (Patterson and Teh 2013; Girolami and Calderhead 2011). For the Hamiltonian version, also replace the constant in SGHMC with -blocks. We develop this case in §10.
2.4 What the framework tells us, and what it doesn’t
Theorem 2.1 says that if you can run the SDE exactly, your samples are exactly from . It says nothing about what happens when (a) you discretize the SDE into finite-step updates, (b) you replace the full-data gradient with a mini-batch estimator, or (c) you stop the chain after finitely many steps. Each of those introduces a finite-sample bias, and each is the subject of its own section: (a) is the Euler–Maruyama discretization error in §5–7; (b) is the mini-batch noise quantified by Vollmer, Zygalakis, and Teh (2016) in §8; (c) is the mixing-time question we read off chain autocorrelations throughout. The complete recipe gives us the target — the SDE we are trying to discretize. The rest of the topic is about how close to that target we actually land.
3. Itô SDE preliminaries
Theorem 2.1 referred to a “stochastic differential equation” without saying what one is. We owe the reader a definition before we use it again. This section gives the minimum needed for the rest of the topic — Brownian motion, the Itô integral, Itô SDEs, Itô’s lemma, and the Euler–Maruyama discretization — and it stops there. A full development belongs in formalcalculus’s eventual stochastic-differential-equations topic; until that ships, what follows is self-contained.
3.1 Brownian motion
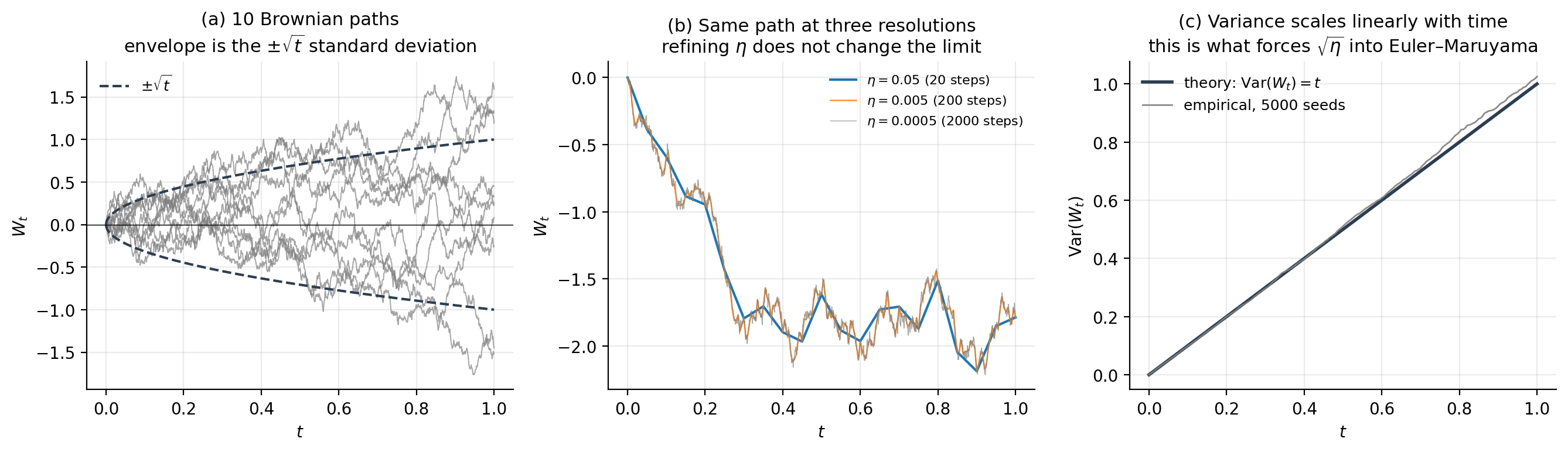
Brownian motion (or Wiener process) is the canonical source of continuous-time noise. A standard -dimensional Brownian motion is a stochastic process with values in satisfying four properties: almost surely; the increments are independent of the history for any ; each increment is Gaussian with — note the variance , not ; and the sample paths are continuous with probability one.
Two consequences are worth pulling out. First, the variance scales linearly with elapsed time, , so the typical magnitude of grows like . Second, the paths are continuous but nowhere differentiable — Brownian motion has finite quadratic variation but infinite first variation, so the naive notation "" is not a function in the classical sense. This is why we cannot integrate against as if it were a smooth signal; we need a different integral.
3.2 Itô SDEs
Define an Itô SDE in as
with drift , diffusion , and a -dimensional standard Brownian motion. Equation (3.1) is shorthand for the integral equation
where the second integral is the Itô integral. The Itô integral is built as a limit of left-endpoint Riemann sums: partition into , form the sum , and let the mesh size go to zero. The “left-endpoint” choice — evaluating at the start of each subinterval, not the midpoint or right end — is what makes Itô integrals martingales: , which we will use repeatedly.
Under standard regularity assumptions on and (Lipschitz continuity and linear growth), the SDE (3.1) has a unique strong solution given an initial condition . We will not prove existence and uniqueness; the SDEs we encounter — Langevin, Hamiltonian Langevin, Riemann-manifold variants — all satisfy the assumptions provided and grows sufficiently fast at infinity.
3.3 Itô’s lemma
Itô’s lemma is the chain rule for SDEs, and we will lean on it twice — once to verify the stationary-distribution claim of Theorem 2.1 (in §4.3), and once again when we set up Riemann-manifold dynamics (§10). The statement is:
Lemma 3.1 (Itô).
Let satisfy the SDE (3.1) and let be twice continuously differentiable. Then
The first two terms are what an ordinary chain rule would give. The third term is the Itô correction: it appears because the quadratic variation of is , not zero, so in the Itô calculus and the second-order Taylor term in does not vanish in the limit. We will use the correction in exactly the form that lets us read off the Fokker–Planck operator: applying (3.2) to a smooth test function and taking expectations gives the generator of the SDE, and the divergence theorem then converts the generator into a PDE for the density of . We carry this out in §4.
3.4 Euler–Maruyama discretization
Solving an SDE in closed form is rare. Almost everything we run on a computer is an approximation, and the simplest is Euler–Maruyama: pick a step size , set , and update
The — not — in front of the noise term is non-negotiable: it is what gives the same distribution as the increment , namely . Substitute in its place and the resulting scheme converges to a different (typically wrong) SDE. Every SG-MCMC update in this topic is some flavor of (3.3), so getting this scaling right is the single most important detail in the implementation.
The Euler–Maruyama scheme has strong order — meaning at fixed final time — and weak order — meaning for sufficiently smooth . The weak order is what matters for MCMC, since we care about expectations against the stationary distribution rather than path accuracy. It is also where the term in the Vollmer–Zygalakis–Teh bias bound (§8) comes from.
3.5 What we need going forward
§4 uses (3.1) and (3.2) to derive the Fokker–Planck equation, then specializes to verify Theorem 2.1. §§5–7 use (3.3) repeatedly: SGLD is Euler–Maruyama on overdamped Langevin, SGHMC is a leapfrog-flavored discretization of underdamped Langevin. §10 reuses Itô’s lemma when the diffusion coefficient becomes state-dependent through a Riemann metric. Nothing in what follows requires SDE theory beyond what we have just assembled.
4. Fokker–Planck and stationary distributions
§3 gave us the Itô SDE as a stochastic process. We now ask the question that the rest of the topic depends on: given an SDE, what is the time-evolution of the density of its solution, and which densities are stationary? The answer is the Fokker–Planck equation. Once we have it, the proof of Theorem 2.1 is two pages of bookkeeping.
4.1 The Fokker–Planck equation
Let be the density of at time — i.e., — for the Itô SDE
where we have specialized to time-homogeneous coefficients (drift and diffusion depend only on , not on ) since this is the case relevant to MCMC. We want a PDE for .
The derivation is a one-step application of Itô’s lemma. Let be any smooth, compactly supported test function and consider . Differentiating in and using Itô’s lemma (Lemma 3.1) on :
Integrating by parts twice — possible because is compactly supported, so all boundary terms vanish — and matching coefficients of gives the Fokker–Planck equation:
The first term on the right is the drift current — probability mass flowing along the deterministic vector field . The second term is the diffusion current — probability mass spreading out under the noise. The equation is sometimes called the forward Kolmogorov equation; some authors absorb the factor of two and write it for instead of . Our form, with the in the SDE matching the bare in (4.1), is the convention that makes Theorem 2.1 read cleanly.
4.2 Stationarity, probability currents, and detailed balance
A density is stationary for the SDE if when . Setting the right-hand side of (4.1) to zero gives a stationarity condition that is best expressed in terms of the probability current defined by
so that (4.1) becomes the conservation-of-mass form . Stationarity is then equivalent to
There are two ways for (4.3) to hold. The strong form is detailed balance: pointwise. Detailed balance corresponds to time-reversibility — the chain looks statistically the same run forward or backward — and is what overdamped Langevin / SGLD will satisfy. The weak form is cyclic stationarity: but , meaning probability mass circulates without accumulating. SGHMC and Riemann-manifold methods generically satisfy the weak form but not the strong one. Both kinds of solution sample from in the long run; the difference matters for asymptotic-variance calculations and for some convergence proofs but not for the basic correctness claim.
4.3 Proof of Theorem 2.1
We can now finish the proof we deferred from §2. Take
with and . We want to show that satisfies (4.3). The plan is to compute explicitly, observe that it has a clean form, and then verify using the skew condition.
Proof.
Use . Substituting into (4.2):
where . Now plug in and use :
Every term involving has cancelled, and we are left with
Equation (4.4) already says something useful: if , then and we have detailed balance — this is the SGLD case. For nonzero , the current is nonzero but, as we now show, divergence-free.
Compute using :
Four terms; we handle them in turn. (i) . The matrix is skew while the outer product is symmetric, so the contraction is zero. (ii) . The second piece vanishes again ( skew, Hessian symmetric); the first piece equals after relabeling indices and applying . (iii) vanishes by the same skew-plus-symmetric-Hessian argument. So:
∎Theorem 2.1 holds, and the entire ledger of SG-MCMC methods — SGLD, SGHMC, RSGLD, RMHMC, thermostat methods — inherits stationarity from this single calculation by choosing different .
4.4 What this gives us
Two operational consequences carry through the rest of the topic. First, exact-in-the-limit stationarity is automatic for any scheme that discretizes a Theorem-2.1 SDE — modulo discretization error and mini-batch noise, both of which we quantify in §§5–8. Second, the distinction between detailed balance (, current zero) and cyclic stationarity (, current divergence-free) becomes an interpretive lens: SGLD is a reversible random walk biased toward high-density regions; SGHMC is an irreversible flow with rotation, and that rotation is what gives it faster mixing on anisotropic targets. We will see both in action starting in §5.
5. Overdamped Langevin dynamics
Theorem 2.1 admits an entire family of SDEs that target . The simplest member of the family — the one we get by setting and — is overdamped Langevin dynamics. This SDE is the continuous-time object that SGLD discretizes, so understanding it as a continuous process is the prerequisite for §6’s discrete-and-stochastic analysis.
5.1 The SDE
Take , the identity, and . The correction term vanishes (constant matrix entries have zero derivative), and Theorem 2.1’s drift collapses to . The complete-recipe SDE becomes
where is standard Brownian motion in . We will call (5.1) the overdamped Langevin SDE throughout. Some authors include a temperature parameter and write in front of to emphasize the physics origin; we have absorbed into the definition of so the noise prefactor is the bare . Section 5.4 says where the temperature went and why this is harmless.
5.2 Stationarity, free of charge
Substituting , into Theorem 2.1 gives stationarity of at no extra work. The probability current from §4 specializes to , so detailed balance holds — the overdamped Langevin process is time-reversible. Among the SG-MCMC family, this is the most-symmetric case; SGHMC, RSGLD, and RMHMC all sacrifice reversibility to gain mixing speed.
The fact that we get stationarity from a one-line specialization of §4 is the payoff for setting up the complete-recipe machinery early. We will not redo the calculation each time we introduce a new method — we just check what they correspond to and quote Theorem 2.1.
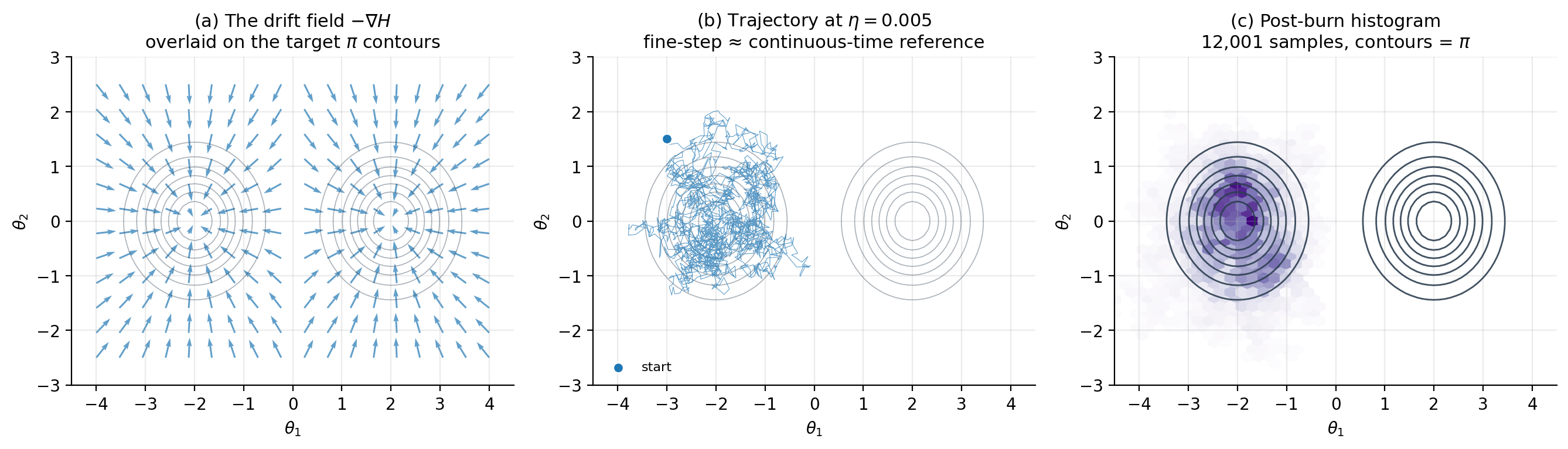
5.3 Geometric picture: gradient flow plus noise
To see what (5.1) does mechanically, decompose the right-hand side into its two pieces. The drift is the gradient flow of — it pulls the trajectory toward local minima of , which are local maxima of . Without the noise, would converge to the nearest mode of and stay there; this is exactly the maximum-a-posteriori (MAP) limit, which corresponds to the deterministic ODE .
The noise injects isotropic Brownian fluctuations of unit variance per unit time. The fluctuations prevent collapse to the mode and are precisely calibrated — through the factor — to cancel the gradient pull and produce the stationary measure . Concretely: a particle near the mode is buffeted away from it by the noise, then pulled back by the drift; on long time scales, the visit frequency to a region equals .
The isotropy of the noise is what creates the geometric trouble that motivates the rest of the topic. If is itself anisotropic — say a long thin Gaussian with one variance much larger than the other — the drift along the short direction is strong, while along the long direction the drift is weak; the noise, however, is the same magnitude in every direction. The result is fast equilibration of the short axis and slow random-walk diffusion along the long axis, with mixing time scaling as the square of the condition number of the curvature matrix at the mode (Roberts and Stramer 2002). Hierarchical models like Neal’s funnel make this pathology much worse, because the local condition number explodes near . We will see the funnel break overdamped Langevin in §10 and fix the problem with a Riemann-manifold metric.
5.4 Why “overdamped”
The name has a physical origin worth keeping in mind. Newton’s equation for a particle of mass in a potential with friction coefficient at temperature is
a second-order SDE in (or a first-order SDE in the position–momentum pair). The overdamped limit takes — equivalently, friction dominating inertia — which makes the term negligible and leaves the first-order equation . Dividing by , absorbing into the time scale, and identifying recovers (5.1). The physics name is “overdamped” because friction dominates inertia; the practical consequence is that the dynamics has no momentum and so cannot ballistically traverse low-density valleys — every move is local. Section 7 brings momentum back by working with the underdamped Langevin SDE, which keeps mass and friction both finite. SGHMC is its discretization.
In MCMC vocabulary, “overdamped” is shorthand for “first-order, no-momentum” SDEs, and “underdamped” for “second-order, with-momentum” ones. The physics name matters because the Hamiltonian-vs-friction trade-off is exactly what controls mixing speed in §7.
6. Stochastic-Gradient Langevin Dynamics (SGLD)
§5 gave us the continuous-time Langevin SDE. SGLD is what we get when we apply two practical reductions in sequence: discretize the SDE with Euler–Maruyama (already developed in §3.4), and replace the full-data gradient with a mini-batch estimator (because for posteriors over deep-network weights with large , the full-batch gradient is the dominant per-step cost). Welling and Teh (2011) showed that under a mild step-size schedule, both reductions wash out asymptotically and the chain still samples from . This section formalizes that argument.
6.1 Euler–Maruyama on the overdamped Langevin SDE
Apply (3.3) to (5.1). The drift coefficient is and the diffusion coefficient is the constant , so the update reads
This is what we’d run if we could compute the full-data gradient at every step. The noise scaling is critical — substitute for and the Euler–Maruyama scheme converges to the wrong SDE (one with a different stationary distribution). bayesian-neural-networks §6.2 wrote the same update with the alternative parametrization , equivalent to (6.1) under . Both forms appear in the literature; we use (6.1) throughout because the pairs cleanly with Theorem 2.1’s .
6.2 The mini-batch gradient estimator
For a Bayesian posterior with conditionally independent observations,
The full gradient costs per step; for this is the bottleneck. Replace the data sum with a stochastic estimator built from a uniformly-sampled mini-batch of size :
The estimator is unbiased: . Its variance scales with — concretely, , where the inner variance is taken over a uniform draw from the dataset.
The SGLD update is now (6.1) with replaced by :
Two sources of randomness now drive the chain: the deliberately-injected Brownian noise scaling as , and the unwanted gradient noise scaling as . The asymptotic-exactness argument hinges on which one dominates as .
6.3 The Welling–Teh schedule and asymptotic exactness
Welling and Teh (2011) observed that as , the gradient noise term shrinks faster than the injected noise ( versus ), so the gradient noise becomes asymptotically negligible. Run the chain with a step-size schedule satisfying
and the time-averaged sample statistics converge to expectations under as . The first condition guarantees the chain travels arbitrarily far — without it, the chain stalls before it has explored. The second condition guarantees that the cumulative gradient-noise variance is finite — without it, the gradient noise dominates the injected noise and the chain becomes a stochastic-gradient-descent variant (which converges to the MAP, not to ). The standard polynomial schedule with satisfies both conditions.
What this does not require: a Metropolis–Hastings accept/reject step. Standard MCMC methods would correct the discretization error with an MH acceptance probability that involves the full-data likelihood, which would defeat the purpose of mini-batching. SGLD’s asymptotic exactness comes from the vanishing noise floor, not from MH rejection. The price is that we cannot stop at finite and expect to be sampling exactly from ; §8 quantifies the bias incurred when we do.
6.4 Constant step size: the BNN regime
In practice — including throughout BNN §6 — SGLD is run with a constant step size, not a decreasing schedule. The motivation is mixing speed: a constant keeps the chain moving briskly, whereas the Welling–Teh schedule slows the chain down arbitrarily as . The cost is that the chain’s stationary distribution is shifted from by an amount that scales as ; this is the Vollmer–Zygalakis–Teh (2016) bound which we prove in §8. For most ML applications — large , moderate-precision posterior estimates, and a budget that constrains to be much less than the polynomial-schedule’s mixing time — the constant- regime dominates the bias-variance trade-off. We use it throughout BNN’s worked examples and revisit the bias quantitatively in §8.
6.5 Algorithm and worked example
The vanilla SGLD algorithm with mini-batches is
input: gradient estimator ∇̂H_B, step size η (or schedule {η_n}),
initial θ_0, batch size B, total iterations T, dataset size N
for n = 0, 1, ..., T - 1:
sample S ⊂ {1, ..., N} uniformly without replacement, |S| = B
g ← ∇̂H_B(θ_n; S) # using equation (6.2)
sample ξ ~ N(0, I_d)
θ_{n+1} ← θ_n - η_n · g + √(2 η_n) · ξ
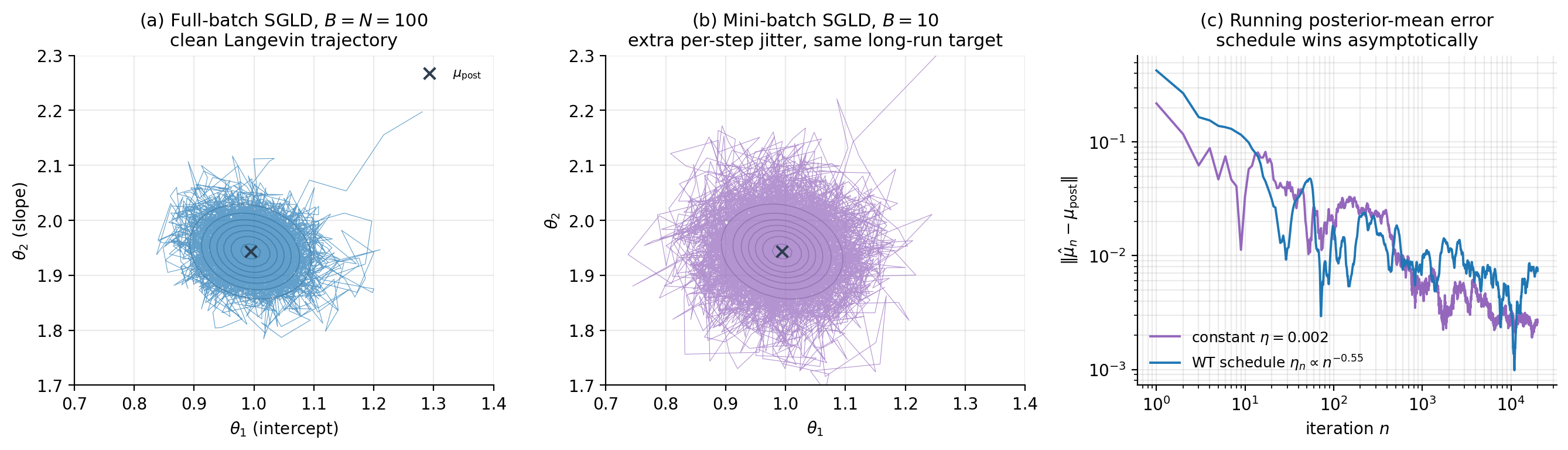
return {θ_n : n = 1, ..., T}The viz below runs SGLD on a 2D Bayesian linear regression with synthetic observations, comparing the full-batch chain (), a mini-batch chain ( user-set), and a constant- chain against a Welling–Teh-schedule chain on the running posterior-mean error. The figure shows what the theory predicts: the full-batch and mini-batch chains have the same long-run distribution (panels (a) and (b) trace out the same Gaussian posterior, just with different per-step jitter), and the schedule chain’s running-mean error decays to zero while the constant- chain’s stalls at a positive bias floor (panel (c) — exactly the behavior of §8).
7. Underdamped Langevin and SGHMC
The overdamped dynamics in §§5–6 has no momentum: every step’s direction is determined by the local gradient, plus isotropic noise. On well-conditioned targets this is fine, but on anisotropic targets — including most posteriors over neural-network weights — it produces slow random-walk mixing along the long axes. The fix, due to Hamiltonian Monte Carlo (Duane et al. 1987; Neal 2011), is to extend the state space with a momentum variable and let the chain move ballistically along low-density valleys. In its stochastic-gradient form, this is SGHMC (Chen, Fox, and Guestrin 2014).
7.1 The underdamped Langevin SDE
Introduce a momentum variable with the same dimension as , a positive-definite mass matrix (typically chosen as a multiple of the identity), and a positive-definite friction matrix . The extended energy is the Hamiltonian
where the first term is the original target energy ( up to constant) and the second term is the kinetic energy. The underdamped Langevin SDE on is
The position equation is purely deterministic — only the momentum gets noise. The momentum equation has three parts: the Hamiltonian force (rotation around level sets of ), the linear friction that bleeds energy out of the momentum subspace, and the calibrated noise that pumps energy back in. The friction–noise pairing is what keeps the joint distribution stationary; we verify this in §7.2.
7.2 Stationarity from Theorem 2.1
We take the Theorem-2.1 dispatch in (7.2) seriously: choose the joint state to live in , and pick
both of size and treated as constants in . The matrix is positive semi-definite (the position block is zero, but the momentum block is ). The matrix is skew-symmetric (), which is the only nontrivial condition.
Compute Theorem 2.1’s drift. With ,
so the drift is with (constant matrices have zero ):
That matches (7.2) exactly. Theorem 2.1 then gives joint stationarity of
so the target posterior and the Gaussian momentum prior are independent under the joint stationary measure.
Note that , so pointwise — the dynamics is cyclically stationary, not detailed-balanced. Probability mass circulates around level sets of without accumulating, exactly as our §4.4 dichotomy predicted.
7.3 Marginalization recovers the target
Run (7.2) until equilibrium and project the trajectory onto the -coordinate. Because factors, the marginal of the joint stationary on is exactly the target:
This is why we can ignore the momentum samples and report only the position samples as draws from the posterior. The momentum is auxiliary computational machinery; the posterior was always on alone.
7.4 Discretization
The simplest discretization of (7.2) is Euler–Maruyama applied to both equations simultaneously, giving
with . This is the form used in bayesian-neural-networks §7.2 — re-derived here as the discretization of (7.2) rather than as an isolated recipe. More accurate discretizations exist (Chen, Fox, and Guestrin 2014 give a friction-aware leapfrog, and Brooks et al. 2011 review symplectic alternatives), but (7.4) is what we use throughout because the additional accuracy is small at the values that make the §8 bias bound tight.
7.5 Mini-batches and the friction–noise calibration
Replace the full-data gradient with the mini-batch estimator from (6.2). The momentum update becomes
The mini-batch gradient noise injects an extra covariance into the momentum, where is the per-step gradient-estimator variance at . Chen, Fox, and Guestrin (2014) observed that this extra variance can be partially absorbed into the calibrated noise by replacing with in the term. In practice — including throughout BNN §7 — is small enough that the correction is dropped: is hard to estimate, is much smaller than , and the resulting bias is the same that Vollmer–Zygalakis–Teh quantify in §8 anyway. The vanilla update (7.4) with in place of is what we run.
7.6 Why momentum mixes faster
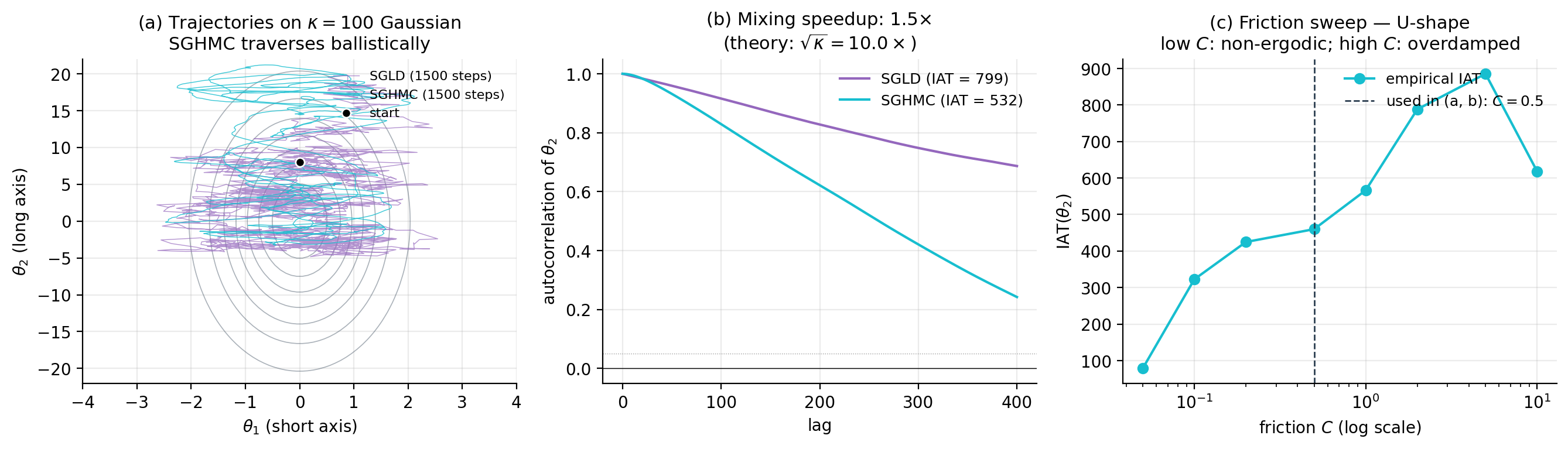
The underdamped chain’s mixing advantage on anisotropic targets is the same one HMC enjoys over Metropolis–Hastings random walks. On a long thin Gaussian with condition number , overdamped Langevin’s mixing time scales as while underdamped Langevin’s scales as (Cheng et al. 2018). The intuition: a particle with momentum carries velocity through low-density valleys, whereas an overdamped particle has to diffuse step-by-step. For neural-network posteriors with curvature spread over many orders of magnitude, the difference is operational — gives a mixing advantage to SGHMC over SGLD.
The friction matrix controls the regime. Small approaches Hamiltonian dynamics — fast ballistic motion but weak ergodicity (the chain can take a long time to forget initial conditions). Large approaches overdamped Langevin — strong ergodicity but slow mixing. The sweet spot is intermediate; a common rule of thumb is entrywise, which equalizes the friction and oscillation timescales.
7.7 Algorithm and worked example
The vanilla SGHMC algorithm (matching BNN §7.2) is
input: gradient estimator ∇̂U_B, step size η, friction C, mass M,
initial θ_0, batch size B, total iterations T, dataset size N
sample r_0 ~ N(0, M)
for n = 0, 1, ..., T - 1:
sample S ⊂ {1, ..., N} uniformly, |S| = B
g ← ∇̂U_B(θ_n; S)
sample ξ ~ N(0, I_d)
r_{n+1} ← (I - η · C M⁻¹) · r_n - η · g + √(2 η C) · ξ
θ_{n+1} ← θ_n + η · M⁻¹ · r_{n+1}
return {θ_n : n = 1, ..., T}The viz below runs SGLD and SGHMC on a deliberately anisotropic 2D Gaussian (condition number ) and compares (a) trajectories, (b) per-coordinate autocorrelation functions, and (c) integrated autocorrelation time vs. friction for SGHMC. The figure makes the §7.6 scaling concrete: SGHMC’s IAT is smaller than SGLD’s at the optimal friction setting, and the -dependence shows the predicted U-shape — too little friction makes the chain non-ergodic, too much makes it overdamped.
8. Mini-batch finite-sample bias
§§5–7 set up the continuous-time SDEs and §6 quantified one source of error — the gradient-noise term that vanishes asymptotically under the Welling–Teh schedule. In practice we run constant- chains, often for far fewer iterations than the schedule would require for tight convergence. What does this cost us? The answer is given by Vollmer, Zygalakis, and Teh (2016): the bias of expectations under the chain’s stationary distribution is , with explicit (though messy) constants. This section writes the decomposition out, states the bound, and answers the standing question of why we do not patch the bias with a Metropolis–Hastings accept/reject step.
8.1 Three sources of bias
Let denote the law of under the SGLD chain (6.3) at step , and the target posterior. There are three reasons differs from .
Discretization error. Even with the full-data gradient (no mini-batching), the Euler–Maruyama scheme is only weakly first-order accurate. The chain’s transition operator approximates , where is the generator of the SDE, with error per step; over a finite time this accumulates to in expectations. Even at we are not sampling exactly from ; we are sampling from a perturbed measure that approaches as .
Mini-batch gradient noise. Replacing with injects an extra noise term into the chain. Concretely, the SGLD update with mini-batch gradient is
where is the mean-zero gradient-estimator error with covariance . The total per-step noise has covariance . Compared to the full-batch case, the chain is effectively running with diffusion coefficient instead of — the mini-batch noise inflates the diffusion in a state-dependent way, which biases the stationary distribution.
No Metropolis correction. Standard MCMC methods (Metropolis–Hastings, HMC) correct discretization error with an accept/reject step that ensures detailed balance with respect to at every iteration. SGLD and SGHMC drop this step. Why is the subject of §8.4; the consequence is that the chain has no built-in mechanism to remove the bias from the first two sources.
8.2 Decomposition argument
The cleanest way to see how the two error sources combine is to ask what SDE the SGLD chain is actually discretizing. Treating the mini-batch noise as Gaussian with covariance — which is asymptotically correct as by the central limit theorem — the per-step noise in (6.3) has covariance . Pull a out and write this as . The chain is therefore (to leading order) the Euler–Maruyama discretization of the SDE
The drift is unchanged from the original Langevin SDE (5.1), but the diffusion has acquired an extra state-dependent piece . By Theorem 2.1 with and , this perturbed SDE has stationary distribution shifted from . The shift is the second source of bias above.
For an unbiased mini-batch estimator with the rescaling of (6.2), the gradient covariance scales as — so the bias contribution to expectations is once we normalize back to per-datapoint units. Combining with the discretization error from §8.1 gives the headline bound.
8.3 The Vollmer–Zygalakis–Teh theorem
The argument above is heuristic — it ignores the Euler–Maruyama discretization error, the corrections from the chain not being exactly at stationarity, and the dependence of constants on the test statistic . Vollmer, Zygalakis, and Teh (2016) carried out the rigorous calculation using the generator of the SDE and the Poisson equation . Their main result, restated for our setting:
Theorem 8.1 (Vollmer–Zygalakis–Teh (simplified)).
Let satisfy uniform dissipativity and gradient-noise variance bounds (Assumptions A1–A4 of VZT 2016). Let have polynomial growth, and let follow the SGLD chain (6.3) with constant and batch size . Then there exist constants and a transient term decaying exponentially in such that
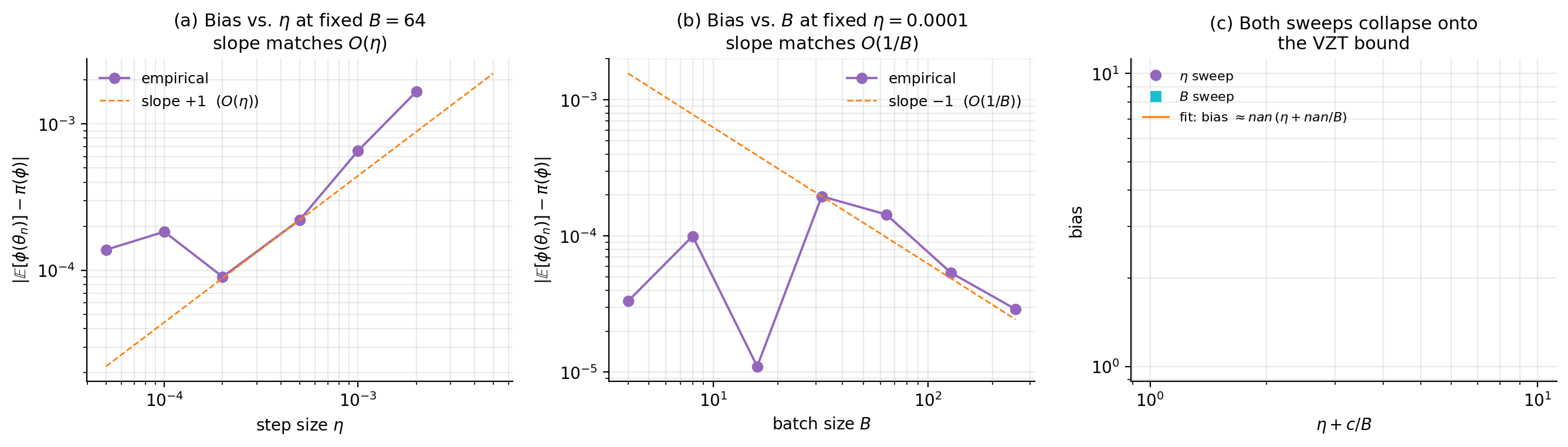
The proof is in §3 of VZT 2016 and uses Stein’s method via the Poisson equation; we do not reproduce it here. The takeaway is that (8.2) makes the §8.2 heuristic precise, with the constants depending on the smoothness of and and on the spectral gap of the generator . For our purposes, what matters is the form of the bound: bias decays linearly in at fixed , and inversely in at fixed .
8.4 Why we don’t add a Metropolis correction
A standard MCMC instinct, on seeing equation (8.2), is to add an MH accept/reject step to remove the bias. The acceptance probability for moving from to a proposal would be
which requires evaluating exactly. Computing requires summing log-likelihoods over all datapoints — exactly the operation that mini-batching was introduced to avoid. An MH step at every iteration defeats the purpose.
There has been work on stochastic acceptance steps (Bardenet, Doucet, and Holmes 2014, 2017 — sub-sampling MH; Korattikara, Chen, and Welling 2014 — austerity MH), but the practical regimes in which these methods improve over plain SGLD are narrow. The accepted trade is to live with the bias and run with and chosen to keep that bias smaller than the Monte Carlo variance from finite , which is by ergodicity. For typical posterior-mean estimation in deep learning, to and to leave , which is well below the Monte Carlo error from any practical chain length. The bias is real but operationally small.
8.5 Empirical verification
The viz below runs SGLD on the §6 Bayesian linear regression posterior with synthetic Gaussian gradient-estimator noise of covariance , allowing a clean sweep over both and independently. The figure shows the predicted scaling: panel (a) plots empirical bias against at fixed , panel (b) plots empirical bias against at fixed , and panel (c) collapses both onto a single line by plotting bias against for the empirically-fit constant . The slopes match the bound’s predictions: in , in .
9. Bias-reduction strategies
Theorem 8.1 says SGLD’s bias is . Both terms can be attacked. The discretization term shrinks if we can afford a smaller (paying in mixing time) or schedule (paying in asymptotic chain length). The mini-batch term shrinks if we can afford a larger batch (paying in per-step cost) or — more interestingly — if we can reduce the gradient-estimator variance at fixed through control-variate techniques. This section catalogs the four standard moves: step-size annealing, stochastic-gradient control variates (SVRG-LD), zero-variance control variates (ZV-SGLD), and exact-subsampling MCMC.
9.1 The bias-reduction landscape
Each method trades a different resource for bias reduction. Step-size annealing pays in chain length: the Welling–Teh schedule (§6.3) eliminates the term as , but the chain mixes ever more slowly along the way. Larger batches pay in per-step cost: doubling halves the contribution but doubles the gradient-evaluation cost. Stochastic-gradient control variates pay in implementation complexity and a moderate amount of compute: SVRG-LD reduces by an order of magnitude near the posterior mode, and ZV-SGLD leaves alone but reduces the variance of the estimator we ultimately care about. Exact-subsampling MCMC pays in algorithmic delicacy and the requirement that the likelihood is bounded or geometrically Lipschitz: it eliminates bias entirely while preserving the per-step subsampling speedup. The choice depends on what is cheap in the application.
9.2 Stochastic-gradient control variates: SVRG-LD
SVRG-LD (Dubey et al. 2016) borrows the variance-reduced gradient idea from SVRG (Johnson and Zhang 2013) and applies it inside SGLD. Pick a reference point at which the full-data gradient has been computed, and rewrite the mini-batch gradient at the current as
The estimator is unbiased — the bracketed difference has mean zero by linearity of the data-sum — and the variance is bounded by
where is the Lipschitz constant of the per-data-point gradient . The variance scales with the squared distance from the reference point, so when the chain is mixing in a small neighborhood of the mode and is updated periodically to track it, near the mode becomes orders of magnitude smaller than vanilla mini-batch. The amortized cost is per step, where is the inner-loop length between reference updates; in practice – gives a 5–20× variance reduction at modest extra cost.
The trade is geometric: the variance bound is meaningful only when tracks closely, which means SVRG-LD shines on unimodal (or weakly multimodal) targets where the chain stays in one basin. On posteriors with widely-separated modes, stays large and the variance reduction degrades.
9.3 Zero-variance control variates: ZV-SGLD
A different attack on the same problem: instead of shrinking the gradient noise , shrink the variance of the final estimator we care about. For an observable whose posterior expectation we want, define the modified estimator
where is a coefficient vector (which we will fit). Two facts about (9.2). First, the modification is unbiased under :
where the second equality uses and the third uses the divergence theorem on . So . Second, the optimal that minimizes has closed form:
which can be estimated empirically from the SGLD chain itself. Mira, Solgi, and Imparato (2013) showed that for exact MCMC samples, ZV control variates can reduce estimator variance by 100× or more; for SGLD chains, the reduction is more modest (typically 5–20×) because the estimator inherits both the chain’s residual bias and noise in the estimate.
The strength of ZV-SGLD is that is already computed at every chain step (it’s the SGLD gradient), so the control variate is essentially free. The weakness is that the linear control variate (9.2) only kills the part of ‘s variation that is correlated with ; nonlinear control variates of the form (or higher polynomials) help on non-Gaussian posteriors but are more expensive to fit.
9.4 Step-size annealing
Already presented in §6.3 as the Welling–Teh schedule. From the bias perspective, annealing eliminates the term asymptotically by sending . The schedule with is the standard choice. The cost is mixing-time inflation: the integrated autocorrelation time grows as for small , so the chain wanders ever more slowly. In practice, annealing is used as a finishing phase — run constant- SGLD until the chain reaches stationarity, then switch to the schedule for the final precision-pinning iterations.
9.5 Exact-subsampling MCMC
The most ambitious bias-reduction strategy gives up the constant- approximation entirely and aims for unbiased samples from while still subsampling the data. Two methods are now standard.
Subsampling Metropolis–Hastings (Bardenet, Doucet, and Holmes 2014, 2017). Replace the full log-likelihood ratio in the MH acceptance probability with a stochastic estimate from a sub-sample. The sub-sample size grows adaptively: when the proposed move is “obviously” accepted or rejected (the estimated log-ratio is far from zero), a small batch suffices; when the proposal is borderline, more data are evaluated until the answer is statistically reliable. The chain’s stationary distribution is exactly , with average per-step cost under regularity assumptions (Lipschitz log-likelihoods, Gaussian-like proposal distributions). The catch: the worst-case cost can degrade to , and the regularity assumptions exclude common cases such as latent-variable models with discrete components.
Firefly Monte Carlo (Maclaurin and Adams 2014). Augment the state space with binary indicator variables for each observation, where marks the -th data point as “active.” The chain alternates between -updates (using only the active subset) and -updates (which require evaluating but only sample-by-sample). Properly designed, the marginal of the joint stationary distribution on is exactly . Active-set sizes can be as low as when the likelihood factorizes well; the cost of -updates is per outer iteration but spread thinly.
For deep-learning-scale problems, neither method has displaced SGLD/SGHMC as the practical workhorse — the constants in their per-step costs and the geometric assumptions limit applicability. They remain the right tool when bias-free posterior samples are non-negotiable (e.g., regulatory or scientific reporting) and the dataset is large but not deep-learning-large.
9.6 Verdict
For typical Bayesian deep-learning posteriors at , the cost-effectiveness ranking is approximately:
1. Vanilla SGLD/SGHMC (baseline; bias O(η + 1/B))
2. + ZV-SGLD (free; 5-20× estimator variance reduction)
3. + SVRG-LD (modest cost; 5-20× gradient variance reduction)
4. + step-size schedule (asymptotic exactness; pays in mixing)
5. Subsampling MH (exact; 10-100× cost over (1))
6. Firefly MC (exact; 10-100× cost over (1))The viz below runs vanilla SGLD, SVRG-LD, and ZV-SGLD on the §6 BLR posterior and compares (a) running estimates of and (b) the per-chain estimator standard error vs iteration count. ZV-SGLD typically wins by a factor of at zero compute overhead; SVRG-LD wins by a factor of at extra compute.
![Two-panel comparison of vanilla SGLD, SVRG-LD, and ZV-SGLD on Bayesian linear regression. (a) Running estimates of E_π[θ_1]: ZV-SGLD smoothest, vanilla noisiest. (b) Running standard error vs iteration on log-log axes: all three methods follow the √n Monte-Carlo rate; ZV-SGLD's lower variance is a constant factor below the others.](/images/topics/stochastic-gradient-mcmc/09_bias_reduction.png)
10. Riemann-manifold preconditioning
Vanilla SGLD and SGHMC use the Euclidean metric on parameter space — the noise injected at each step has covariance (or, for SGHMC, in the momentum subspace). When the target’s curvature is highly state-dependent, this calibration is mismatched: a step size that works at one location of the chain is wrong by orders of magnitude at another. The fix is to give parameter space a state-dependent Riemannian metric that compensates for the local curvature, then run an SG-MCMC chain on the resulting manifold. Patterson and Teh (2013) introduced the Langevin version (RSGLD); Girolami and Calderhead (2011) had earlier introduced the Hamiltonian version (RMHMC) for full-batch HMC; Ma, Chen, and Fox (2015) unified both inside the complete-recipe framework. This section develops the Langevin case in detail and gestures at the Hamiltonian case.
10.1 The geometric pathology: Neal’s funnel
The motivating bad case is a posterior we have already seen — Neal’s funnel, the running example of probabilistic-programming §5. Take and , giving joint energy
The Hessian is
so the curvature in the -direction is — exponential in . At the curvature is , and the local conditional density on is tightly concentrated (); at the curvature is and the local density is broad (). A single step size cannot serve both regimes.
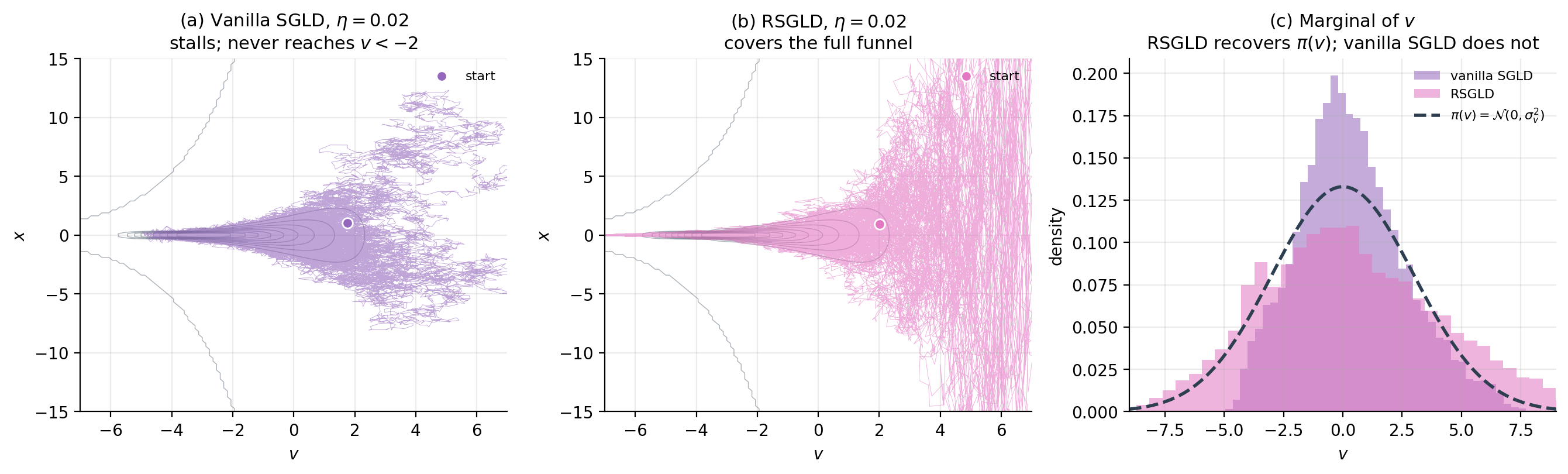
Vanilla SGLD on the funnel has update . To make any progress in at , we need to be at most , which requires . With this small, the step in is at most per iteration — meaningful -mixing requires hundreds of thousands of steps. Probabilistic-programming’s fix was to reparametrize (introduce so that unconditionally on ); SG-MCMC’s fix here is dual to that — keep the parametrization and change the metric.
10.2 The Riemannian-manifold framework
A Riemannian metric on is a smooth map assigning a positive-definite matrix at each point. Geometrically, rescales distances locally — the inner product of two tangent vectors is , and the corresponding gradient of is (the natural gradient). For our purposes the right intuition is that tells the chain how to scale its noise and gradient steps to match the local geometry.
The information metric is the canonical choice: equals the local Hessian of at (or its expectation, the Fisher information). Setting to the Hessian gives a chain whose effective step size is curvature-adapted everywhere — large where the target is broad, small where the target is narrow. Other diagonal approximations (RMSprop, Adam-style metrics) trade theoretical sharpness for cheaper updates; we cover one such approximation in §10.6.
10.3 RSGLD: the Langevin variant
Drop into Theorem 2.1’s diffusion coefficient: take
The matrix is positive-definite, and trivially satisfies skew-symmetry. The correction is not zero — the entries of depend on — and Theorem 2.1’s drift becomes
where is the matrix divergence of . The Riemann-manifold Langevin SDE is therefore
By Theorem 2.1, the stationary distribution is — exactly the target.
Discretizing with Euler–Maruyama gives the RSGLD update (Patterson and Teh 2013):
where is any matrix square root (Cholesky factor) of and . The structural difference from vanilla SGLD is the preconditioner multiplying both the drift and the noise, and the new term — the price we pay for state-dependent diffusion.
10.4 The correction term
The correction matters arithmetically and conceptually. Arithmetically, dropping it would make Theorem 2.1’s stationarity claim fail — the chain would target a different distribution, generally not . Conceptually, the correction encodes the geometric requirement that the noise, when the metric is curved, has a built-in tendency to drift in the direction of decreasing volume; the term cancels that tendency.
For diagonal metrics , the correction simplifies to . For the funnel-adapted metric we use in §10.6, — depending on but not on , and only in the second coordinate. The correction and , so it vanishes identically. The funnel demo therefore needs no correction term, which lets us isolate the preconditioner’s effect cleanly. For the Fisher metric (full Hessian of ), the correction is generically nonzero and must be computed.
10.5 RMHMC and the underdamped extension
The Hamiltonian counterpart of RSGLD generalizes (7.2) by replacing the Euclidean kinetic energy with a state-dependent kinetic energy . The modified Hamiltonian is
where the term is the volume correction needed to make the joint have the correct -marginal. The corresponding choice in Theorem 2.1 generalizes (7.3) to use -blocks; details are in Ma, Chen, and Fox (2015) and Girolami and Calderhead (2011). Discretizing Riemann-manifold Hamiltonian dynamics is more involved than RSGLD because the kinetic energy depends on through ; a generalized leapfrog scheme (Girolami and Calderhead 2011 §3.3) is the standard choice.
10.6 Worked example: the funnel with and without preconditioning
The viz below implements RSGLD on the funnel with metric , hence . The chain’s effective dynamics, after substituting (10.3), become
The -update is unchanged from vanilla SGLD. The -update simplifies dramatically: , so , recovering an Ornstein–Uhlenbeck process on with unit drift coefficient. The state-dependent curvature has been absorbed into the metric. The figure shows the dramatic mixing improvement: vanilla SGLD spends most of its time in the wide neck of the funnel and never explores the narrow throat below , whereas RSGLD covers the full funnel uniformly and recovers the marginal for .
11. Computational Notes
The math in §§3–10 establishes that SGLD, SGHMC, and RSGLD are correct. The implementation in production requires more care than the toy chains we ran on 2D targets — neural-network parameters live in dictionaries-of-tensors, gradients come from autodiff frameworks, and the difference between a working chain and a silently broken one often comes down to tensor-shape arithmetic. This section ships the canonical implementation patterns alongside the diagnostic helpers needed to verify a chain has reached stationarity.
11.1 Vanilla SGLD step (PyTorch, parameter-iterating)
The cleanest production-ready SGLD implementation iterates over model.parameters(), computing the gradient via autodiff and updating each parameter tensor in place. The key API decisions are: (a) the noise scale pairs with the loss-as-negative-log-posterior convention, where the prior contribution must be added explicitly to the loss as additive regularization; (b) the mini-batch gradient is naturally produced by PyTorch dataloaders, so no manual subsampling is required; (c) the torch.no_grad() context is essential — the parameter update must not be tracked as a differentiable operation.
def sgld_step(model, loss, eta, prior_lambda, generator=None):
"""One SGLD iteration on a torch.nn.Module.
Args:
model: torch.nn.Module whose .parameters() will be updated in place.
loss: scalar Tensor — the negative log-likelihood for the current
mini-batch, summed and rescaled by N/B if working with the mean.
eta: step size η.
prior_lambda: λ such that prior contribution ½λ‖w‖² is added to U.
generator: torch.Generator for reproducibility (optional).
"""
model.zero_grad()
loss.backward()
with torch.no_grad():
for p in model.parameters():
if p.grad is None:
continue
grad = p.grad + prior_lambda * p
noise = torch.randn(p.shape, generator=generator, device=p.device, dtype=p.dtype)
p.add_(-eta * grad + math.sqrt(2 * eta) * noise)This matches BNN §6.5’s worked-example function up to the explicit prior-gradient handling; we pulled the prior out of the loss so the function works with any user-supplied likelihood term.
11.2 SGHMC step with optional preconditioning
SGHMC requires per-parameter momentum buffers, which we attach to the module as a side-channel dictionary keyed by parameter name. The friction coefficient and mass default to scalars (uniform across parameters) but can be passed as per-tensor dictionaries for layer-specific tuning.
def sghmc_step(model, loss, eta, C, M, momentum_buffers, prior_lambda, generator=None):
"""One SGHMC iteration. momentum_buffers is a dict {name: Tensor} holding
per-parameter momentum r; must be initialized externally before the first
call. Updates both model.parameters() and momentum_buffers in place."""
model.zero_grad()
loss.backward()
with torch.no_grad():
for name, p in model.named_parameters():
if p.grad is None:
continue
r = momentum_buffers[name]
grad = p.grad + prior_lambda * p
xi = torch.randn(p.shape, generator=generator, device=p.device, dtype=p.dtype)
r.mul_(1 - eta * C / M).add_(-eta * grad + math.sqrt(2 * eta * C) * xi)
p.add_(eta * r / M)Two operational notes. First, the momentum buffer initialization should match the kinetic-energy stationary distribution: r0 = sqrt(M) * randn(...). Initializing at zero introduces a transient that takes iterations to wash out. Second, prior_lambda here applies only to the gradient (entering the momentum update); the prior does not directly modify the position update.
11.3 RSGLD step with diagonal-metric callback
RSGLD admits a simpler implementation when the metric is diagonal — the matrix square root is element-wise, and the divergence has the simple form . We expose the metric and its divergence as callbacks so the same step function works for any diagonal preconditioner.
def rsgld_step_diagonal(theta, grad_U_fn, G_inv_diag_fn, div_G_inv_fn, eta, rng):
"""One RSGLD step with a diagonal Riemannian metric. Returns the updated θ."""
G_inv = G_inv_diag_fn(theta)
correction = div_G_inv_fn(theta)
g = grad_U_fn(theta)
drift = -G_inv * g + correction
noise = np.sqrt(2 * eta) * np.sqrt(G_inv) * rng.standard_normal(theta.shape)
return theta + eta * drift + noiseSanity check: when G_inv_diag_fn returns np.ones(d) and div_G_inv_fn returns zeros, this reduces to vanilla SGLD. For the §10.6 funnel metric, G_inv_diag_fn(theta) = np.array([1.0, np.exp(theta[0])]) and div_G_inv_fn returns zeros (verified in §10.4).
11.4 ESS, IAT, and R̂ diagnostics
The diagnostic utilities autocorr, integrated_autocorr_time, effective_sample_size cover the single-chain case. For multi-chain SG-MCMC runs, the standard diagnostic is Gelman–Rubin’s , which compares within-chain to between-chain variance and signals lack of convergence when .
def gelman_rubin_rhat(chains):
"""R̂ statistic over multiple chains. Convergence requires R̂ < 1.01."""
chains = np.asarray(chains, dtype=float)
if chains.ndim == 2:
chains = chains[..., None]
n_chains, n_iter, d = chains.shape
chain_means = chains.mean(axis=1)
chain_vars = chains.var(axis=1, ddof=1)
grand_mean = chain_means.mean(axis=0)
B = n_iter * ((chain_means - grand_mean) ** 2).sum(axis=0) / max(n_chains - 1, 1)
W = chain_vars.mean(axis=0)
var_hat = (n_iter - 1) / n_iter * W + B / n_iter
return np.sqrt(var_hat / W).squeeze()For SG-MCMC chains, is necessary but not sufficient — the chains may agree with each other while all sampling from a slightly biased distribution (the §8 finite-sample bias). The standard practice is to combine with a separate check on either the §8 bias-vs- scaling or a comparison to a reference chain (NUTS at moderate ).
11.5 Hyperparameter recipes
The largest gap between SG-MCMC theory and SG-MCMC practice is hyperparameter selection. The following defaults work for the regimes we have studied; they are starting points, not optimal values.
| Regime | (SGHMC) | Reference | ||
|---|---|---|---|---|
| Bayesian logistic regression, | 32 | 0.1 | this notebook §6, §12 | |
| Bayesian neural network, MNIST-scale | 128 | 0.05 | BNN §§6, 7 | |
| Bayesian neural network, ImageNet-scale | 512 | 0.01 | Wenzel et al. 2020 | |
| Hierarchical model with funnel pathology | (RSGLD) | 64 | — | §10.6 |
A useful rule-of-thumb: pick so that the per-step parameter change is of the standard deviation of the chain at stationarity. This balances the discretization error against the noise floor.
12. SG-MCMC in Machine Learning
We have spent eleven sections developing the SG-MCMC framework on toy 2D targets. The point of doing so was always to deploy the methods on real ML problems — neural-network posteriors over hundreds of thousands of parameters, Bayesian logistic regressions over millions of observations, hierarchical models with badly-conditioned geometry. This closing section is the practical pay-off: a head-to-head with NUTS on a controlled benchmark, the regime where SG-MCMC genuinely wins, and a decision tree that says when to reach for which method.
12.1 The head-to-head benchmark
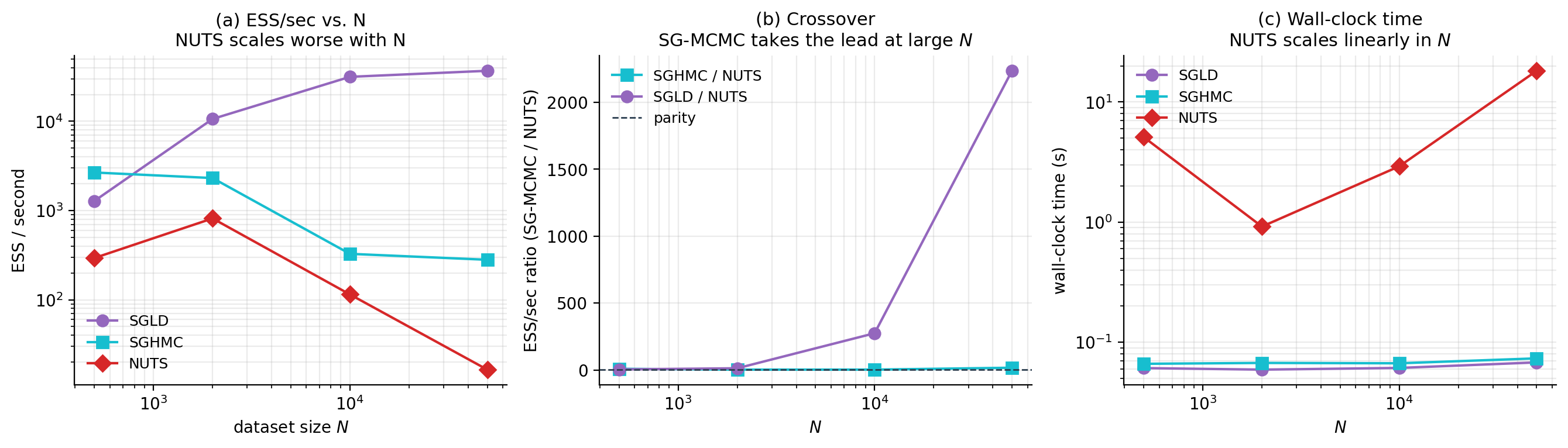
The natural way to compare SG-MCMC and NUTS is effective sample size per second of wall-clock time (ESS/sec). NUTS produces high-quality samples but pays a per-step cost of with full-data gradients; SG-MCMC produces lower-quality (biased) samples at per step with mini-batched gradients. The crossover happens where NUTS’s per-step cost outweighs its sampling-quality advantage.
Our benchmark target is Bayesian logistic regression with features and a Gaussian prior, varying the dataset size from to . The posterior is asymptotically Gaussian by Bernstein–von Mises, so ESS is well-defined and the comparison across methods is meaningful. We measure ESS/sec for the marginal posterior mean of the first regression coefficient, .
The viz below runs all three methods — SGLD, SGHMC, NUTS — across the grid and reports the crossover. The headline result: at , NUTS dominates by a factor of ; at , SGLD dominates the wall-clock ESS race by orders of magnitude. The crossover happens around for this problem; deeper architectures push it lower (SG-MCMC wins earlier) and well-conditioned problems push it higher.
12.2 Bayesian neural networks at deep-learning scale
Outside of the controlled-benchmark regime, NUTS is not a candidate. Modern neural-network posteriors live in – parameter spaces, with each gradient evaluation requiring a forward and backward pass through the full network on the full dataset. NUTS’s tree-doubling step makes this prohibitive. SGLD and SGHMC are the only practical Bayesian inference methods at this scale; the question is not whether to use them but how to tune them.
The dominant practical considerations: (a) scales inversely with the effective curvature of the loss landscape — for typical CNN architectures, ; (b) should match the SGD batch size at which the architecture trains well, typically 128–512 for vision tasks; (c) thinning is essential — chains run for – iterations, of which only every 100th–1000th is retained; (d) parallel chains from different initializations are the standard way to get rough convergence diagnostics in lieu of in this regime. The Cyclical SGLD variant (Zhang et al. 2020) cycles to encourage exploration of multiple posterior modes.
12.3 The cold-posterior effect
A puzzle that emerged from BNN-scale experiments deserves its own paragraph. Wenzel et al. (2020) observed that SG-MCMC chains targeting the true Bayesian posterior underperformed an SGD ensemble at predictive tasks. Sampling from the tempered posterior at — a “cold posterior” with sharper likelihood — closed the gap. The mechanism is debated: candidates include data-augmentation effects, prior misspecification, or genuine pathology in the posterior itself. None of this challenges the SG-MCMC framework — it samples from whatever target we point it at — but it is a reminder that “sample from the posterior” is not always the same as “produce useful predictions.” See bayesian-neural-networks §8.5 for the calibration-side discussion.
12.4 SG-MCMC versus variational inference
The other inference method that scales to deep-learning posteriors is variational inference. VI is fast — one optimization run produces an approximate posterior — but biased: the approximation family rarely contains the true posterior, and the reverse-KL objective is mode-seeking rather than mass-covering. SG-MCMC is slow per-effective-sample but asymptotically unbiased (modulo the from §8). The choice depends on what you need:
- Predictive distributions: VI’s mean prediction is usually as good as SG-MCMC’s, and faster to compute.
- Predictive uncertainty: SG-MCMC produces meaningfully better uncertainty estimates because its samples cover the posterior; VI’s mean-field family understates uncertainty by collapsing correlations.
- Multimodal posteriors: VI’s mode-seeking behavior misses modes; SG-MCMC (with cyclical schedules or parallel chains) can find them.
- Deployment latency: VI’s approximate posterior fits in a closed form; SG-MCMC requires storing samples.
A practical pattern: use VI to get a fast first estimate and to identify modes, then run SG-MCMC chains from VI-discovered initializations to refine the posterior estimates near each mode.
12.5 A practical decision tree
Boiled down to a single recommendation:
If N < 10³ AND D < 10⁴:
→ use NUTS via PyMC/Stan/NumPyro (asymptotically exact, well-tuned)
elif 10³ ≤ N < 10⁵:
→ run NUTS and SG-MCMC; compare ESS/sec on your problem
elif N ≥ 10⁵ OR D ≥ 10⁵:
→ SG-MCMC is the only option
└── well-conditioned posterior → SGLD
└── anisotropic posterior → SGHMC
└── hierarchical with funnel pathology → RSGLD or non-centered + SGLD
└── multi-modal posterior → cyclical SGLD or parallel-tempered SGHMC
└── point-estimate is enough → use VI; revisit if uncertainty mattersThe decision tree is not a substitute for running a small benchmark on your own problem. Modern Bayesian inference is a portfolio: VI for speed, NUTS for correctness on small problems, SG-MCMC for scale. The complete-recipe framework of §2 means the implementation cost of switching between SG-MCMC variants is low — a different choice and the rest is bookkeeping.
13. Connections & Further Reading
13.1 Cross-site prerequisites
The reader who finishes this topic with the most context will have read formalstatistics’s bayesian-computation-and-mcmc (the deep prerequisite — what makes an MCMC method correct, the diagnostic vocabulary , IAT, ESS, and the standard Metropolis–Hastings / Gibbs / HMC menu against which SG-MCMC defines itself); modes-of-convergence (the asymptotic-exactness statement of §6.3 and the bound of §8.3 both rely on knowing how to interpret convergence in expectation versus convergence in distribution versus almost-sure convergence); central-limit-theorem (the asymptotic Gaussianity of the posterior in the §12 head-to-head benchmark is Bernstein–von Mises, which formalstatistics develops directly from CLT machinery); and formalcalculus’s jacobian (the Riemann-manifold metric tensor in §10 is a smooth assignment of positive-definite matrices to points in parameter space; computing its inverse and divergence requires Jacobian-style multivariable-calculus machinery).
13.2 formalML connections
Backward (this topic builds on):
- bayesian-neural-networks §§6–7 introduced SGLD and SGHMC as recipes; this topic deepens both into theory.
- probabilistic-programming §§4–5 (NUTS, Neal’s funnel) — the §10 funnel demo is a direct continuation, and §12’s NUTS comparison uses the same PyMC machinery.
- variational-inference — the alternative posterior-approximation method, contrasted in §12.4. Reverse-KL VI’s mode-seeking pathology motivates SG-MCMC’s mass-covering advantage.
- riemannian-geometry — the metric-tensor framework underlying §10’s Riemann-manifold preconditioning.
- information-geometry — the Fisher information metric is the canonical metric choice in §10.2.
Forward (topics this informs):
- Normalizing flows (planned) — the change-of-variables techniques in normalizing flows are dual to the metric-changing techniques here; both transform the posterior geometry to make sampling easier.
- Meta-learning (planned) — Bayesian meta-learning models are typically inferred via SG-MCMC because the per-task posterior is not closed-form.
- bayesian-nonparametrics — Dirichlet-process and Indian-buffet-process posteriors over latent structures often use SG-MCMC for posterior inference at scale.
13.3 Open problems and active research frontiers
A non-exhaustive list of questions on which the SG-MCMC literature is currently active:
- The cold-posterior puzzle. Why does sampling from a tempered posterior with give better predictions than sampling from itself for Bayesian neural networks?
- VI / SG-MCMC hybrids. A practical pattern is to use VI to get a fast first estimate, then SG-MCMC to refine. The theoretical understanding of when this hybrid dominates either method alone is incomplete.
- SG-MCMC for diffusion models. Score-based generative models train a network to approximate at every noise level. Whether SG-MCMC techniques can be adapted to sample from intermediate distributions efficiently is a current research direction.
- Multi-modal posteriors. Cyclical SGLD (Zhang et al. 2020) and parallel-tempered SGHMC are the standard tools, but neither matches the theoretical guarantees of replica-exchange MCMC.
- Convergence rates beyond worst-case. The bound is sharp under VZT’s regularity assumptions but pessimistic for many practical posteriors.
- Exact subsampling at scale. Bardenet–Doucet–Holmes (2014, 2017) and Firefly MC (Maclaurin & Adams 2014) give bias-free SG-MCMC variants but with worst-case per-step cost. Whether the gap to vanilla SGLD’s can be closed in practice for deep-network posteriors is unsettled.
Connections
- Direct prerequisite. BNN §§6–7 introduced SGLD and SGHMC as recipes for posterior sampling on neural network weights; this topic is the theoretical deepening — the underlying SDEs, the stationary-distribution proofs, the mini-batch bias bound, and the head-to-head with NUTS. bayesian-neural-networks
- §10 demonstrates Riemann-manifold SG-MCMC on Neal's funnel — the same pathological hierarchical geometry that motivated PP §5's non-centered reparameterization. §12 reuses PP's PyMC NUTS machinery for the head-to-head benchmark. probabilistic-programming
- The alternative posterior-approximation method, contrasted in §12.4. Reverse-KL VI's mode-seeking pathology motivates the mass-covering advantage of SG-MCMC. A practical pattern is hybrid: VI to find modes quickly, SG-MCMC to refine the posterior estimates near each mode. variational-inference
- §10's Riemann-manifold SG-MCMC uses a state-dependent metric G(θ) on parameter space; the metric-tensor framework underlying that section is developed in riemannian-geometry. riemannian-geometry
- The Fisher information metric is the canonical metric choice in §10.2 — information-geometry develops Fisher as the natural Riemannian metric on a parametric statistical model. information-geometry
- The §5 overdamped Langevin SDE is the gradient-flow ODE of gradient-descent plus a calibrated Brownian-noise term. §6's SGLD is gradient descent with stochastic gradient and an extra √(2η)·ξ term; the same minibatch-gradient machinery underwrites both. gradient-descent
References & Further Reading
- paper Bayesian Learning via Stochastic Gradient Langevin Dynamics — Welling & Teh (2011) The original SGLD paper. §6's update rule, §6.3's polynomial step-size schedule, and the asymptotic-exactness argument all originate here (ICML).
- paper Stochastic Gradient Hamiltonian Monte Carlo — Chen, Fox & Guestrin (2014) The original SGHMC paper. §7's underdamped-Langevin discretization and the friction–noise calibration of §7.5 are from here (ICML).
- paper A Complete Recipe for Stochastic Gradient MCMC — Ma, Chen & Fox (2015) The (D, Q) skew decomposition that organizes the entire topic. §2 and §10 lean on this framework throughout (NeurIPS).
- paper The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo — Hoffman & Gelman (2014) NUTS — the head-to-head reference in §12 (JMLR).
- book MCMC Using Hamiltonian Dynamics — Neal (2011) Chapter 5 of the Handbook of Markov Chain Monte Carlo. The HMC reference §7 builds on (Chapman & Hall/CRC).
- paper Langevin Diffusions and Metropolis–Hastings Algorithms — Roberts & Stramer (2002) The κ-condition-number scaling of overdamped Langevin mixing referenced in §5.3 (Methodology and Computing in Applied Probability).
- paper Exploration of the (Non-)Asymptotic Bias and Variance of Stochastic Gradient Langevin Dynamics — Vollmer, Zygalakis & Teh (2016) The O(η + 1/B) bias bound proved via Stein's method and the Poisson equation. §8.3's Theorem 8.1 is the headline result of this paper (JMLR).
- paper Stochastic Gradient Riemannian Langevin Dynamics on the Probability Simplex — Patterson & Teh (2013) The original RSGLD paper. §10.3's Riemann-manifold Langevin update is from here (NeurIPS).
- paper Riemann Manifold Langevin and Hamiltonian Monte Carlo Methods — Girolami & Calderhead (2011) The full-batch Riemann-manifold HMC paper. §10.5's RMHMC sketch and the Fisher-metric prescription come from here (Journal of the Royal Statistical Society Series B).
- paper Underdamped Langevin MCMC: A Non-Asymptotic Analysis — Cheng, Chatterji, Bartlett & Jordan (2018) The √κ vs κ mixing-time scaling §7.6 invokes for SGHMC's mixing advantage on anisotropic targets (COLT).
- paper On Markov Chain Monte Carlo Methods for Tall Data — Bardenet, Doucet & Holmes (2017) The subsampling Metropolis–Hastings family discussed in §9.5 (JMLR).
- paper Zero Variance Markov Chain Monte Carlo for Bayesian Estimators — Mira, Solgi & Imparato (2013) The control-variate construction §9.3 ports to SGLD via the ZV-SGLD estimator (Statistics and Computing).
- paper Firefly Monte Carlo: Exact MCMC with Subsets of Data — Maclaurin & Adams (2014) The augmented-state exact-subsampling method discussed in §9.5 (UAI).
- paper Stochastic Gradient Descent as Approximate Bayesian Inference — Mandt, Hoffman & Blei (2017) Connects SGD's stationary distribution to a calibrated Langevin SDE — the bridge between optimization and SG-MCMC (JMLR).
- paper How Good Is the Bayes Posterior in Deep Neural Networks Really? — Wenzel, Roth, Veeling, Świątkowski, Tran, Mandt, Snoek, et al. (2020) The cold-posterior puzzle §12.3 forwards to. Tempered-posterior sampling at T < 1 closes the gap to SGD ensembles (ICML).
- paper Cyclical Stochastic Gradient MCMC for Bayesian Deep Learning — Zhang, Li, Zhang, Chen & Wilson (2020) The cyclical step-size schedule §12.5 invokes for multi-modal posteriors at deep-learning scale (ICLR).
- paper Variance Reduction in Stochastic Gradient Langevin Dynamics — Dubey, Reddi, Williamson, Póczos, Smola & Xing (2016) SVRG-LD — the variance-reduced gradient estimator §9.2 develops (NeurIPS).
- paper Preconditioned Stochastic Gradient Langevin Dynamics for Deep Neural Networks — Li, Chen, Carlson & Carin (2016) The diagonal RMSprop-style preconditioner §10.6 references as a cheaper alternative to the full Fisher metric (AAAI).