Proximal Methods
Proximal operators, the Moreau envelope, forward-backward splitting, ISTA/FISTA for composite objectives, Douglas–Rachford splitting, and ADMM — the algorithmic toolkit for non-smooth and constrained optimization
Overview & Motivation
In Gradient Descent & Convergence we built a complete convergence theory for smooth optimization: given an -smooth convex function , gradient descent with step size achieves an rate, and Nesterov acceleration pushes this to the optimal . But smoothness is a luxury that many real problems don’t enjoy.
Consider the Lasso — the workhorse of sparse regression:
The first term is smooth (its gradient is ), but the penalty is not differentiable at zero, which is precisely where sparsity lives. We can’t just compute and step in the negative gradient direction, because doesn’t exist everywhere.
Proximal methods resolve this tension by splitting the problem into pieces we know how to handle. The key insight: even though isn’t smooth, we can evaluate its proximal operator — a generalization of the gradient step that replaces “move in the direction that decreases fastest” with “find the point that best balances minimizing and staying close to where you are.” For the norm, this proximal operator turns out to be soft-thresholding: shrink each coordinate toward zero by , and set it exactly to zero if it’s smaller than .
What We Cover
- The Proximal Operator — definition, geometric interpretation, and the fixed-point characterization of minimizers.
- Proximal Operator Catalog — closed-form solutions for the norm (soft-thresholding), indicator functions (projection), the squared norm (shrinkage), and group norms.
- The Moreau Envelope — the smooth approximation that connects proximal operators to gradient-based reasoning, with the gradient identity .
- Proximal Gradient Descent — forward-backward splitting for composite objectives (smooth + non-smooth), with convergence.
- ISTA — proximal gradient applied to the Lasso, with soft-thresholding as the key subroutine.
- FISTA — Nesterov-style acceleration from to the optimal .
- Douglas–Rachford Splitting — handling problems where both terms are non-smooth.
- ADMM — the consensus formulation with three-variable updates and primal-dual residuals.
- Convergence Analysis — the rate landscape across algorithms and the role of strong convexity.
- Computational Notes — backtracking step size selection, convergence diagnostics, and stopping criteria.
The Proximal Operator
The proximal operator is the fundamental building block. Where gradient descent asks “which direction decreases fastest?”, the proximal operator asks a different question: “which point best balances minimizing and staying close to where I am?”
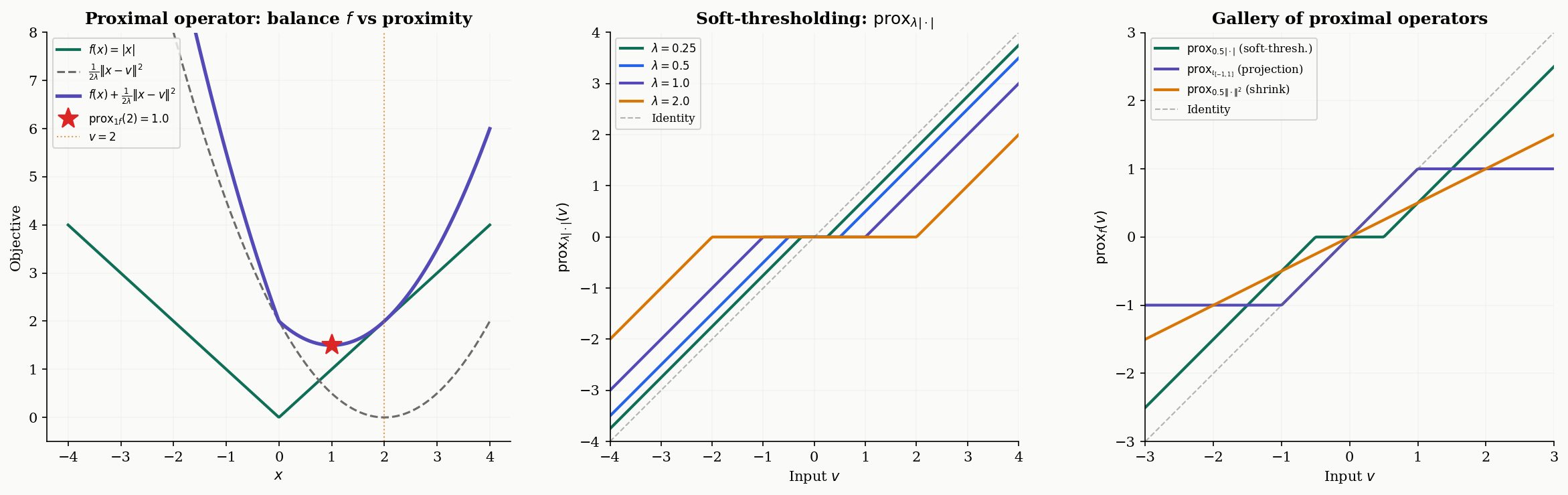
Definition 1 (The Proximal Operator).
Let be a proper, closed, convex function, and let . The proximal operator of with parameter is the map defined by
The minimizer exists and is unique because the objective is -strongly convex (the quadratic penalty dominates at large , and the sum of a convex and a strongly convex function is strongly convex).
The parameter controls the tradeoff between the two competing objectives. When is small, the quadratic penalty dominates — the proximal operator stays close to , barely moving. When is large, the function dominates — the proximal operator moves toward the minimizer of itself. In the limit , (don’t move); in the limit , (jump to the global minimizer).
The proximal operator has an elegant characterization in terms of fixed points that connects it directly to the optimality conditions from Convex Analysis.
Proposition 1 (Fixed-Point Characterization).
A point minimizes if and only if is a fixed point of the proximal operator:
This holds for any . That is, the fixed points of are exactly the minimizers of , regardless of the choice of .
Proof.
() If , then minimizes . The optimality condition for this minimization is , which gives .
() If , then for any , convexity gives for some . Taking , we get for all , so , and is the minimizer.
∎proxλf(v) = prox1.0·|x|(1.5) = 0.500
Proximal Operator Catalog
The utility of proximal methods depends on having cheap, closed-form proximal operators for the functions we care about. Here are the most important ones.
Definition 2 (Soft-Thresholding Operator).
The proximal operator of (the scaled absolute value in 1D, or the scaled norm componentwise in ) is the soft-thresholding operator:
In , soft-thresholding acts componentwise: .
Soft-thresholding is the engine behind every -regularized method in this topic. It does two things simultaneously: it shrinks each coordinate toward zero by (the “shrinkage” part), and it sets coordinates smaller than exactly to zero (the “thresholding” part). This is why regularization produces sparse solutions — the proximal operator itself enforces sparsity.
def soft_threshold(x, lam):
"""Proximal operator of lambda * |.|: soft-thresholding."""
return np.sign(x) * np.maximum(np.abs(x) - lam, 0.0)Proposition 2 (Proximal Operator of an Indicator Function).
Let be a nonempty closed convex set, and let be its indicator function ( if , otherwise). Then
is the Euclidean projection onto , for any .
This is immediate from the definition: the term forces the minimizer to lie in , and the quadratic penalty selects the closest point in to . The indicator function effectively encodes a hard constraint, and its proximal operator is the classical projection. This means constrained optimization can be cast as unconstrained proximal operations.
Proposition 3 (Proximal Operator of the Squared Norm).
For (the squared Euclidean norm), the proximal operator is a shrinkage toward the origin:
This follows by setting the gradient of to zero: , giving .
Two more proximal operators appear frequently in applications:
Group soft-thresholding. For the group Lasso with (the norm of a group of coordinates), the proximal operator is:
This zeroes out entire groups, rather than individual coordinates.
Simplex projection. The proximal operator of the indicator of the probability simplex is the Euclidean projection onto . This can be computed in time by sorting and thresholding (Duchi et al., 2008):
def proj_simplex(x):
"""Projection onto the probability simplex."""
n = len(x)
u = np.sort(x)[::-1]
cssv = np.cumsum(u) - 1.0
rho = np.nonzero(u * np.arange(1, n + 1) > cssv)[0][-1]
theta = cssv[rho] / (rho + 1.0)
return np.maximum(x - theta, 0.0)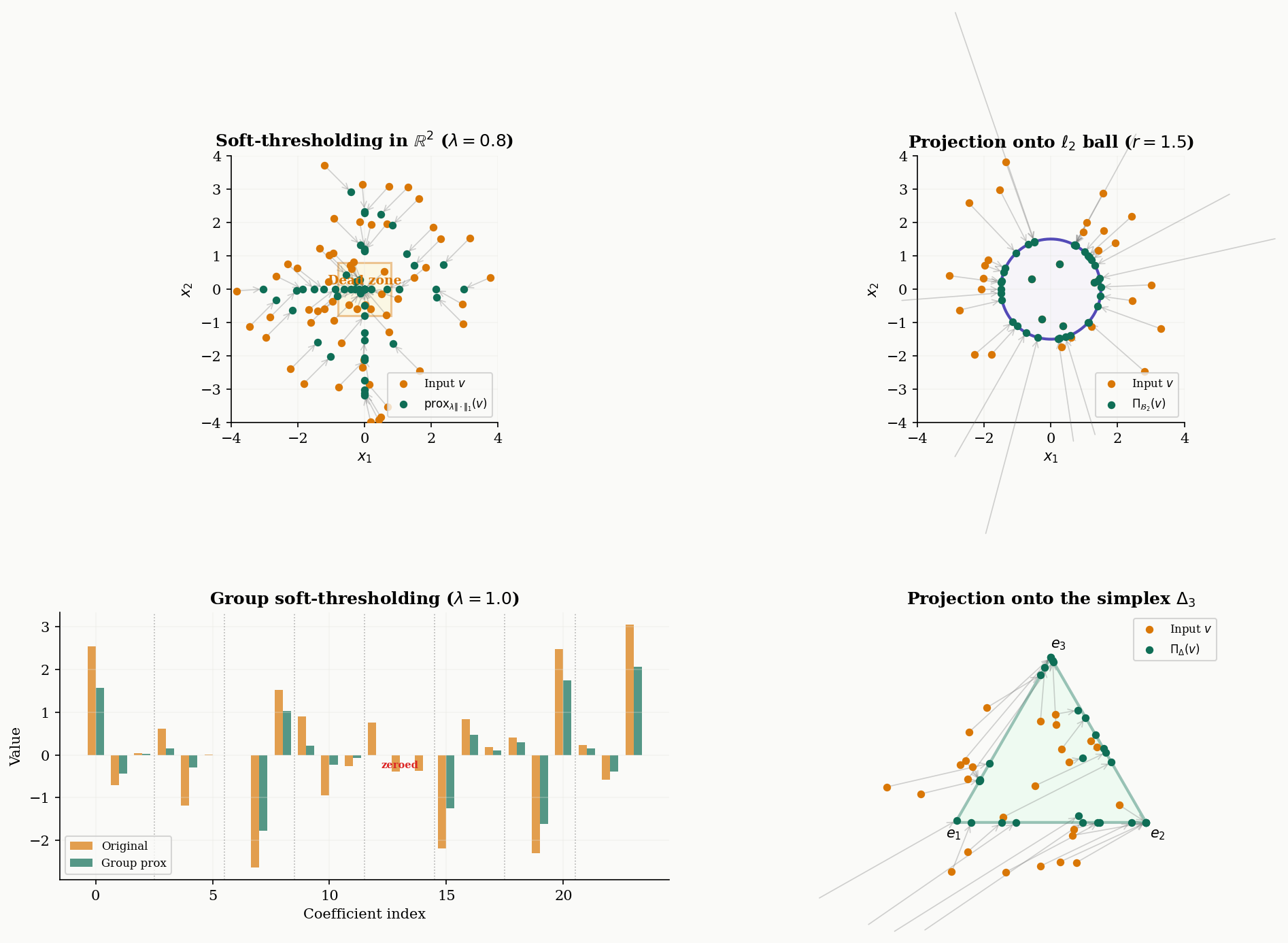
The Moreau Envelope
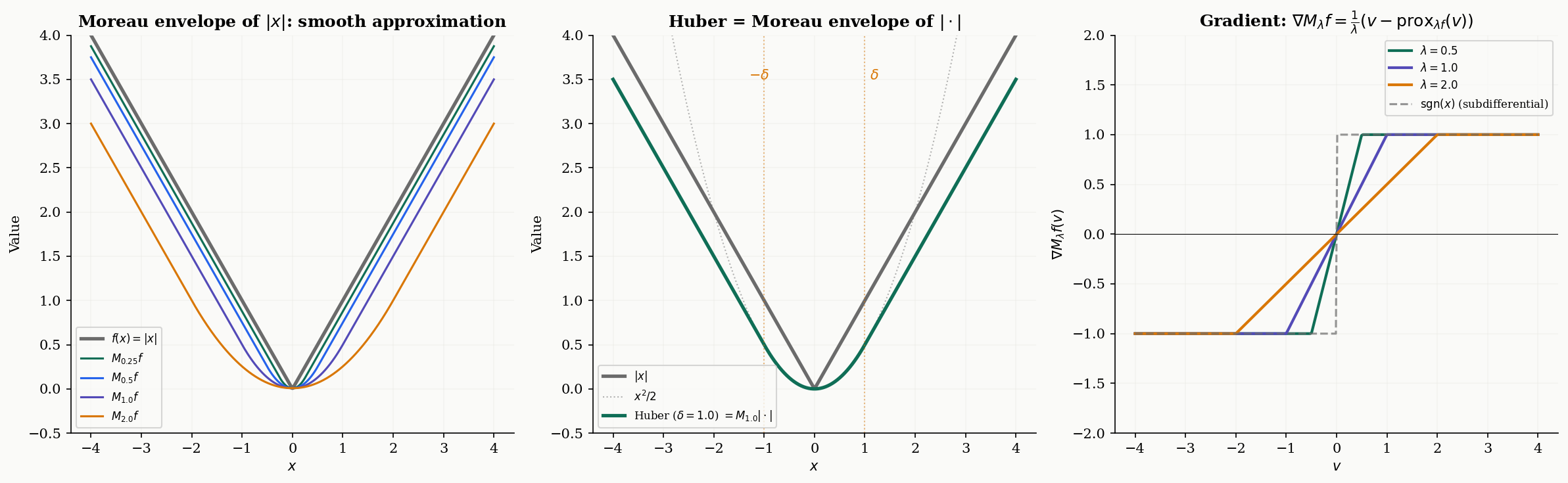
The proximal operator finds the minimizer of . But what is the value of that minimum? This is the Moreau envelope — a smooth version of that serves as a theoretical bridge between non-smooth analysis and gradient-based reasoning.
Definition 3 (The Moreau Envelope).
Let be proper, closed, and convex. The Moreau envelope of with parameter is
The Moreau envelope is always finite, continuous, and — crucially — differentiable, even when is not.
The parameter controls the smoothing strength. When is small, closely approximates (but with corners rounded off). When is large, is a very smooth, gentle version of . The infimal values are preserved: , and the minimizers are the same.
A beautiful special case: when , the Moreau envelope is exactly the Huber function with parameter :
The Huber function is the standard “smooth ” used in robust regression — it’s quadratic near zero and linear in the tails, and we now see that this arises naturally as the Moreau envelope.
Theorem 1 (Gradient of the Moreau Envelope).
For any proper, closed, convex function and , the Moreau envelope is differentiable everywhere, with gradient
Moreover, is Lipschitz continuous with constant , so is -smooth.
Proof.
Let . By definition, minimizes over . The envelope is .
By the envelope theorem (or direct computation), we differentiate with respect to , using the fact that is the minimizer (so the term vanishes at ):
For Lipschitz continuity: the proximal operator is firmly nonexpansive (a classical result), meaning . Therefore
A tighter analysis using firm nonexpansiveness gives the constant.
∎This identity is remarkable: the gradient of the smooth envelope equals the proximal residual , scaled by . When is a minimizer, the proximal operator is the identity (), and the gradient is zero — exactly what we expect.
Proximal Gradient Descent
Now we assemble the proximal operator into an optimization algorithm. The setting is composite minimization — the most important problem structure in modern convex optimization.
Definition 4 (Composite Minimization).
The composite minimization problem is
where:
- is convex and -smooth (i.e., is Lipschitz with constant : for all ),
- is convex but possibly non-smooth, with a cheaply computable proximal operator.
The canonical example is the Lasso: is smooth with , and has the soft-thresholding proximal operator. But the framework covers much more — any problem where we can split the objective into a smooth part we can take gradients of and a structured part we can “prox.”
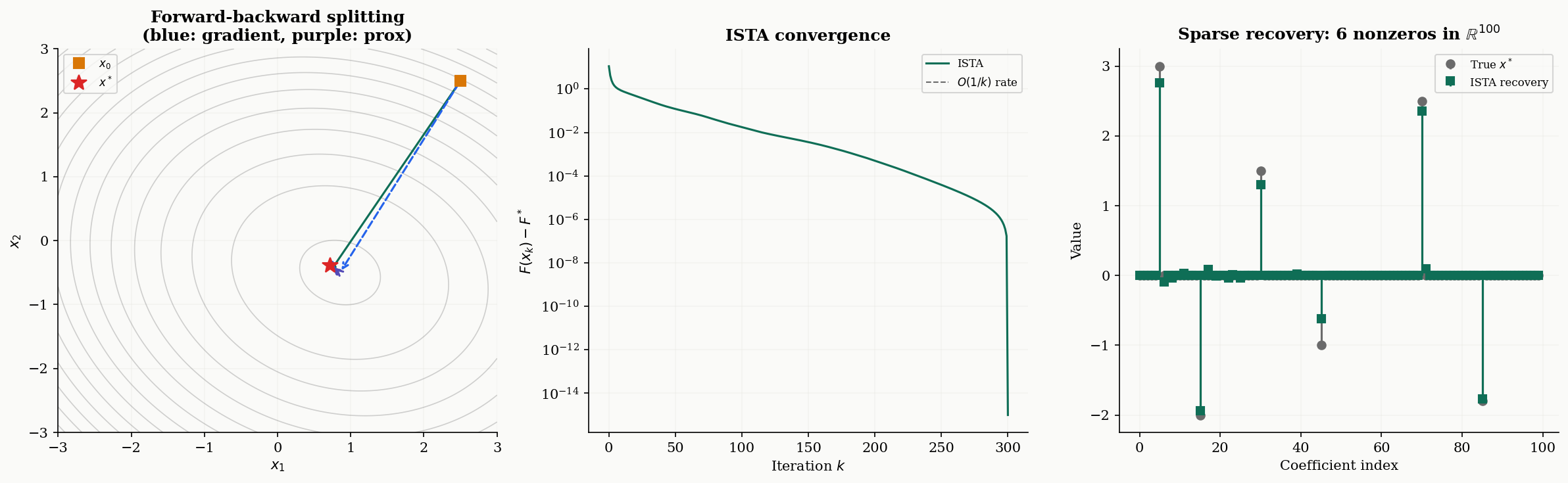
The forward-backward splitting algorithm alternates between a gradient step on (the “forward” step) and a proximal step on (the “backward” step):
where is the step size. Intuitively: first move in the negative gradient direction of (the smooth part), then apply the proximal operator of to “clean up” — projecting, thresholding, or whatever demands.
When , the proximal step is the identity and we recover vanilla gradient descent. When , the gradient step is trivial and we get the proximal point algorithm. Forward-backward splitting is the natural hybrid.
Theorem 2 (Convergence of Proximal Gradient Descent).
Let where is convex and -smooth, and is convex with a computable proximal operator. Let be the iterates of proximal gradient descent with step size . Then:
-
Convex case: , giving a rate of .
-
Strongly convex case: If is additionally -strongly convex (with ), then
giving linear convergence with rate governed by the condition number .
Proof.
The proof extends the Descent Lemma from Gradient Descent & Convergence. By -smoothness of :
Setting and with , and using the optimality condition for the proximal step (which says ), we obtain the sufficient decrease condition:
for any . Setting and summing from to :
Since is non-increasing, , giving the rate.
For the strongly convex case, the additional quadratic lower bound gives a contraction factor of per step, yielding linear convergence.
∎
ISTA & Soft-Thresholding
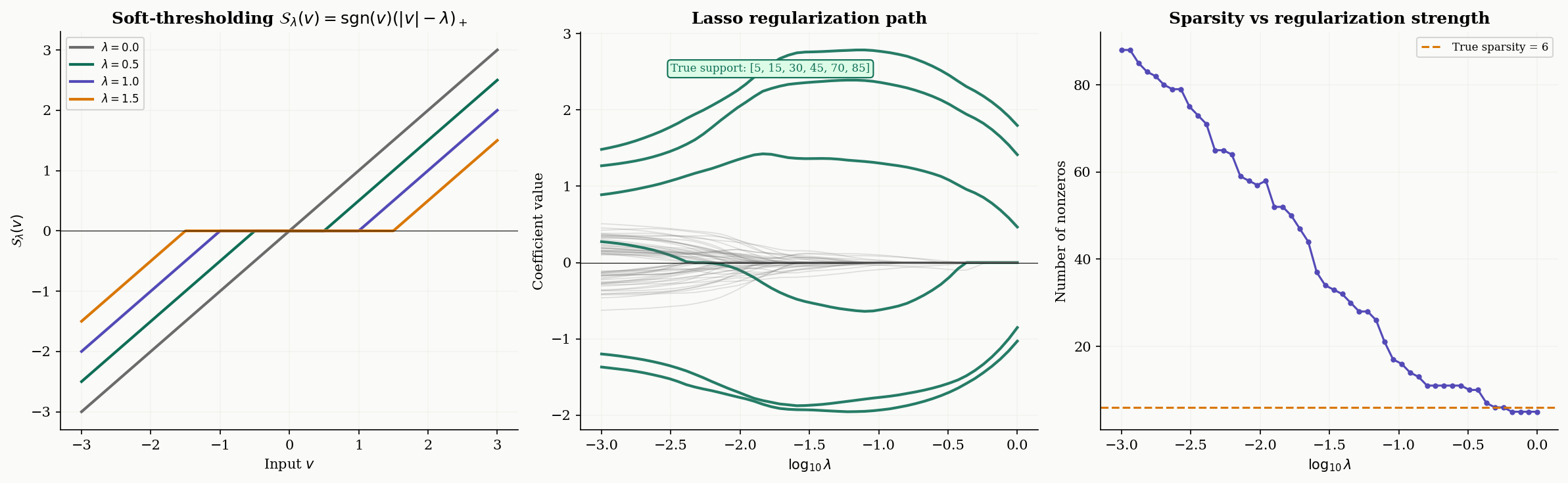
The Iterative Shrinkage-Thresholding Algorithm (ISTA) is proximal gradient descent applied to the Lasso. The name comes from the fact that the proximal step reduces to componentwise soft-thresholding — a “shrink and threshold” operation.
Proposition 4 (ISTA for the Lasso).
For the Lasso problem , proximal gradient descent with step size (where ) reduces to:
That is: take a gradient step on the smooth quadratic loss, then apply componentwise soft-thresholding with threshold . The algorithm converges at rate for the objective gap.
The two-step structure is transparent. The gradient step moves toward fitting the data (minimizing ), and the soft-thresholding step promotes sparsity by shrinking small coefficients to zero. The threshold balances the two goals: larger means more thresholding and sparser solutions.
# ISTA for Lasso
L = np.linalg.eigvalsh(A.T @ A)[-1] # Lipschitz constant
eta = 1.0 / L
x = np.zeros(p)
for k in range(max_iter):
x_half = x - eta * A.T @ (A @ x - b) # gradient step on g
x = soft_threshold(x_half, eta * lam_lasso) # prox step on hThe regularization path. As varies from large to small, the ISTA solution traces a path from zero (complete sparsity) to the least-squares solution (no regularization). This path reveals which features enter the model first — the most important predictors appear at larger values. Computing the full regularization path is a standard diagnostic for choosing in practice.
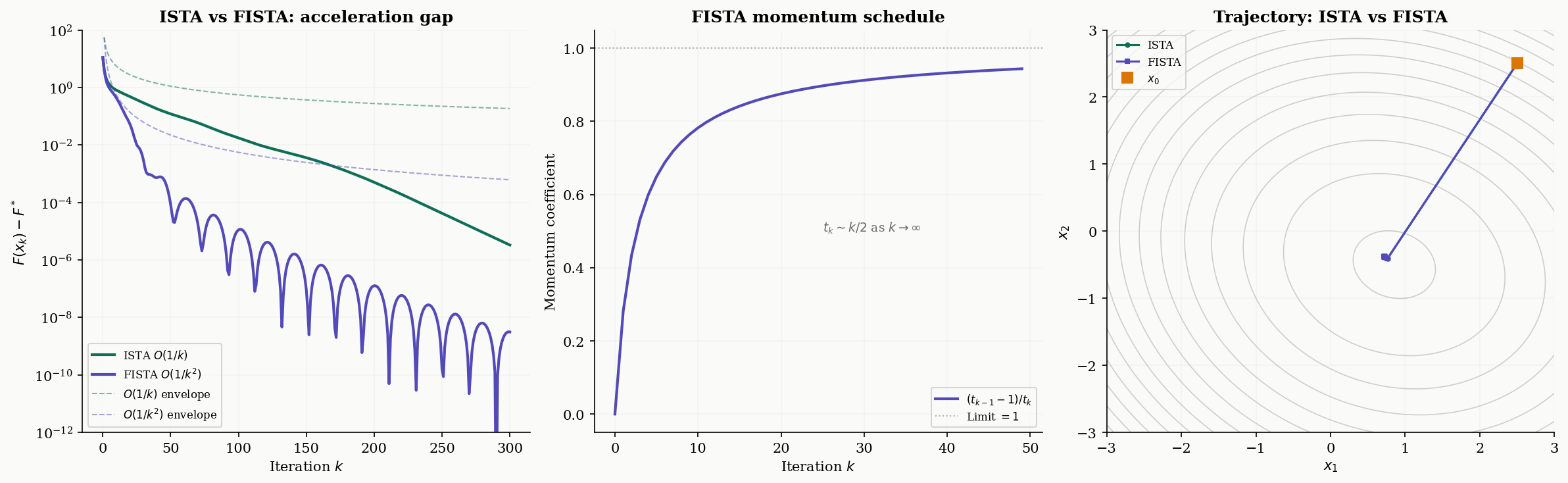
FISTA: Accelerated Proximal Gradient
ISTA’s rate is the same as vanilla gradient descent on smooth problems. Can we accelerate it, the way Nesterov acceleration improves gradient descent from to ? The answer is yes, and the result is FISTA — the Fast Iterative Shrinkage-Thresholding Algorithm of Beck & Teboulle (2009).
Theorem 3 (FISTA Convergence Rate).
The FISTA algorithm, defined by the updates
with , converges at rate
This is — optimal for first-order methods on the composite class.
Proof.
The proof follows Nesterov’s estimation sequence technique, adapted to the composite setting. The key is the momentum schedule satisfying , which ensures the sequence grows as for large .
Define the Lyapunov function , where . Using the sufficient decrease property from the proximal gradient step and the momentum relation, one shows . Since , we get
and since , the bound follows.
∎The momentum schedule is the signature feature. As , the momentum coefficient , meaning the extrapolation step becomes increasingly aggressive. This is why FISTA trajectories can overshoot — the momentum pushes past the current iterate, trading local stability for faster global convergence.
# FISTA for Lasso
x = np.zeros(p)
x_prev = x.copy()
t_k = 1.0
for k in range(max_iter):
t_next = (1 + np.sqrt(1 + 4 * t_k**2)) / 2
y = x + ((t_k - 1) / t_next) * (x - x_prev) # momentum extrapolation
x_prev = x.copy()
x_half = y - eta * A.T @ (A @ y - b) # gradient step on g (at y)
x = soft_threshold(x_half, eta * lam_lasso) # prox step on h
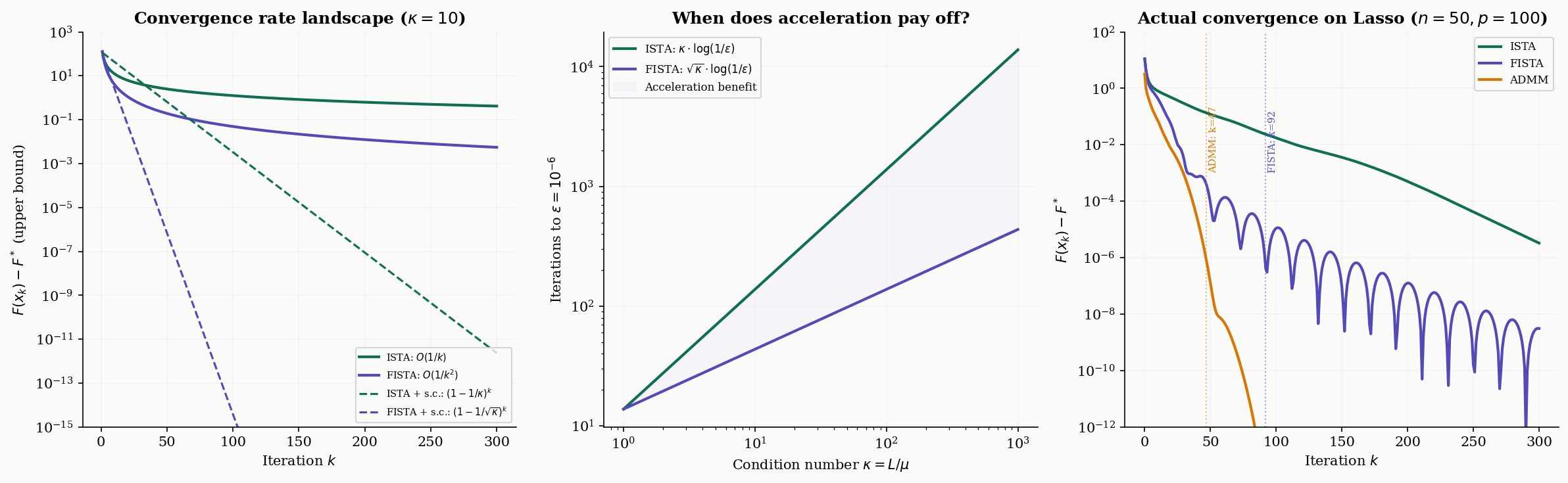
t_k = t_nextWhen does acceleration matter? The gap between and is most dramatic when high accuracy is needed — to reach , ISTA needs iterations while FISTA needs . For well-conditioned problems or moderate accuracy, ISTA may suffice. For ill-conditioned sparse recovery or high-precision scientific computing, FISTA’s speedup is substantial.
Douglas–Rachford Splitting
Forward-backward splitting requires one term to be smooth (so we can compute its gradient). What if both terms are non-smooth? This is the setting for Douglas–Rachford splitting.
Definition 5 (Douglas–Rachford Splitting).
To minimize where both and are proper, closed, convex (but possibly non-smooth) with computable proximal operators, the Douglas–Rachford (DR) update is:
where is a step-size parameter. The iterates converge to a minimizer of .
The variable is an auxiliary “shadow” variable — it doesn’t converge to the solution itself, but the iterates do. The second update can be rewritten as where is the reflected proximal operator (or “reflection”). Douglas–Rachford is thus an averaged iteration of composed reflections — a deeply geometric operation.
The canonical application is basis pursuit: minimize subject to (exact sparse recovery). Setting and , both are non-smooth, but both have cheap proximal operators — soft-thresholding for and projection onto the affine subspace for .
Theorem 4 (Convergence of Douglas–Rachford Splitting).
Let be proper, closed, convex functions with . Then for any and , the Douglas–Rachford iterates satisfy:
- converges to a minimizer of .
- The convergence rate for the objective gap is .
# Douglas-Rachford for basis pursuit: min ||x||_1 s.t. Ax = b
AAt_inv = np.linalg.inv(A @ A.T)
def proj_affine(x):
return x + A.T @ AAt_inv @ (b - A @ x)
gamma = 1.0
z = np.zeros(p)
for k in range(max_iter):
y = soft_threshold(z, gamma) # prox_f
r = proj_affine(2 * y - z) # prox_g(reflected)
z = z + r - y # shadow update
# y is the solution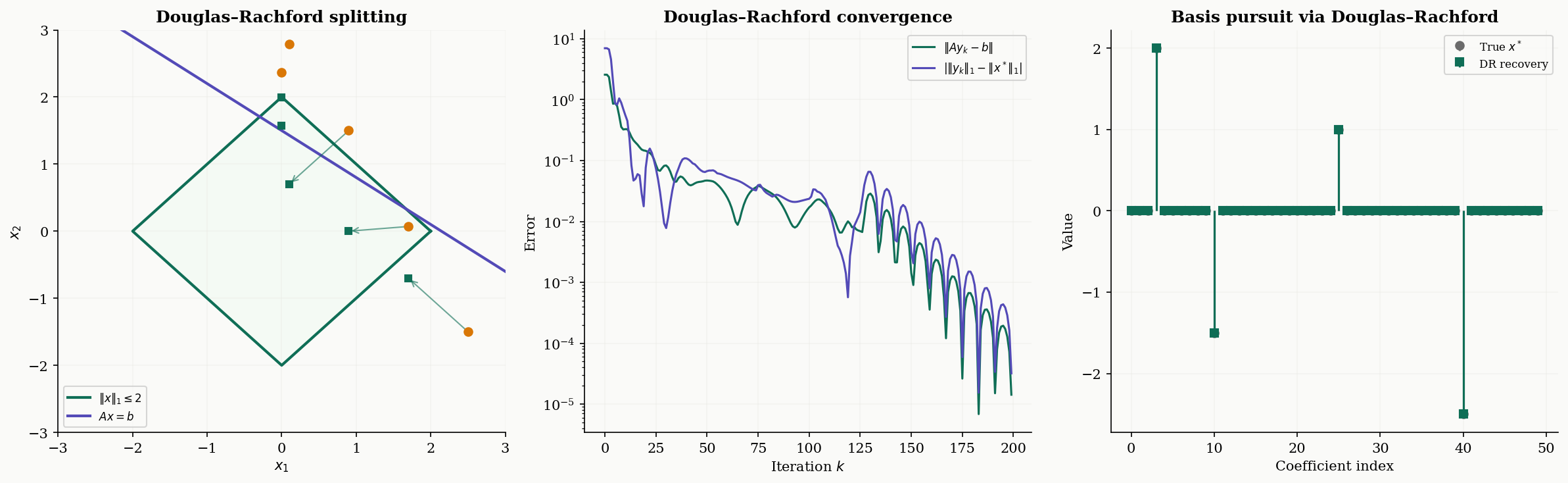
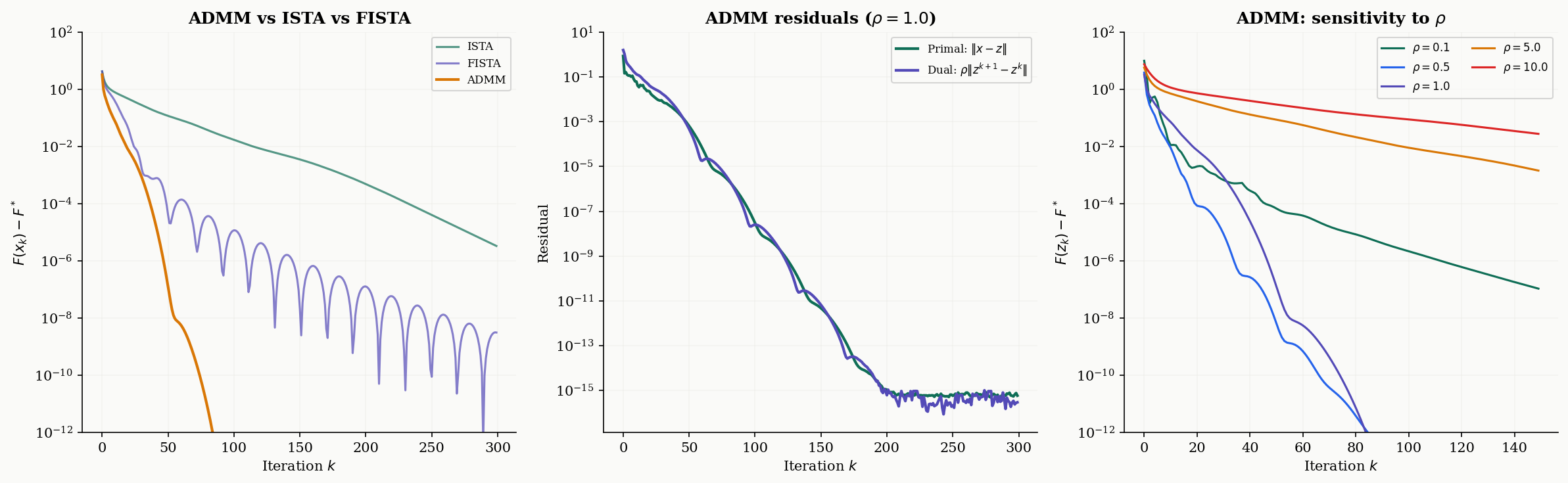
ADMM
The Alternating Direction Method of Multipliers (ADMM) is the most widely used splitting method in practice. It handles the general constrained formulation by augmenting the Lagrangian with a quadratic penalty.
Definition 6 (ADMM Update).
For the consensus problem , the ADMM updates (in scaled form) are:
where is the penalty parameter and is the scaled dual variable (the Lagrange multiplier divided by ).
For the Lasso via ADMM, we set and with the constraint . The -update requires solving a linear system , the -update is soft-thresholding, and the -update is a simple addition.
# ADMM for Lasso
rho = 1.0
AtA_rho_inv = np.linalg.inv(A.T @ A + rho * np.eye(p))
Atb = A.T @ b
x, z, u = np.zeros(p), np.zeros(p), np.zeros(p)
for k in range(max_iter):
x = AtA_rho_inv @ (Atb + rho * (z - u)) # x-update
z_old = z.copy()
z = soft_threshold(x + u, lam_lasso / rho) # z-update
u = u + x - z # dual update
primal_res = np.linalg.norm(x - z) # primal residual
dual_res = rho * np.linalg.norm(z - z_old) # dual residualConvergence monitoring. ADMM convergence is tracked via two residuals:
- Primal residual — measures constraint violation (how far and are from consensus).
- Dual residual — measures dual variable change (stationarity of the Lagrangian).
The algorithm converges when both residuals are small. The standard stopping criterion is and .
Sensitivity to . The penalty parameter has a significant effect on convergence speed but does not affect the final solution. Small favors fast primal convergence (the and updates are more independent), while large favors fast dual convergence (the constraint is enforced more aggressively). In practice, adaptive schemes that increase when the primal residual is large and decrease it when the dual residual is large can dramatically improve convergence.
Remark.
ADMM as Douglas–Rachford on the dual. ADMM applied to the consensus problem s.t. is equivalent to applying Douglas–Rachford splitting to the dual problem. This explains why both methods achieve an convergence rate and why the penalty parameter in ADMM plays the same role as the step-size parameter in DR. The primal-dual structure of ADMM provides richer convergence diagnostics (two residuals instead of one), which is a practical advantage.
Convergence Analysis
We now have four splitting algorithms — ISTA, FISTA, Douglas–Rachford, and ADMM — each designed for a different problem structure. The following table summarizes the convergence landscape:
| Algorithm | Setting | Rate (convex) | Rate (strongly convex, ) |
|---|---|---|---|
| ISTA (Proximal Gradient) | smooth + prox-friendly | (linear) | |
| FISTA (Accelerated) | smooth + prox-friendly | (optimal) | (linear, faster) |
| Douglas–Rachford | both non-smooth, both prox-friendly | — | |
| ADMM | consensus/splitting form | — |
Here is the smoothness constant of , is the initial distance, is the strong convexity parameter, and is the condition number.
Key observations:
-
FISTA is always at least as fast as ISTA, and strictly faster when the target accuracy is small. The gap widens as grows: ISTA needs iterations while FISTA needs .
-
Strong convexity accelerates both ISTA and FISTA from sublinear to linear convergence. The practical message: if you know your problem is strongly convex, the convergence is exponentially faster.
-
ADMM and DR have the same theoretical rate (), but ADMM is often faster in practice because it exploits the structure of the consensus formulation and allows per-variable parallelism.
-
Condition number dependence is the bottleneck. For all these methods, ill-conditioned problems (large ) converge slowly. Preconditioning — transforming the problem to reduce — is often more effective than switching algorithms.
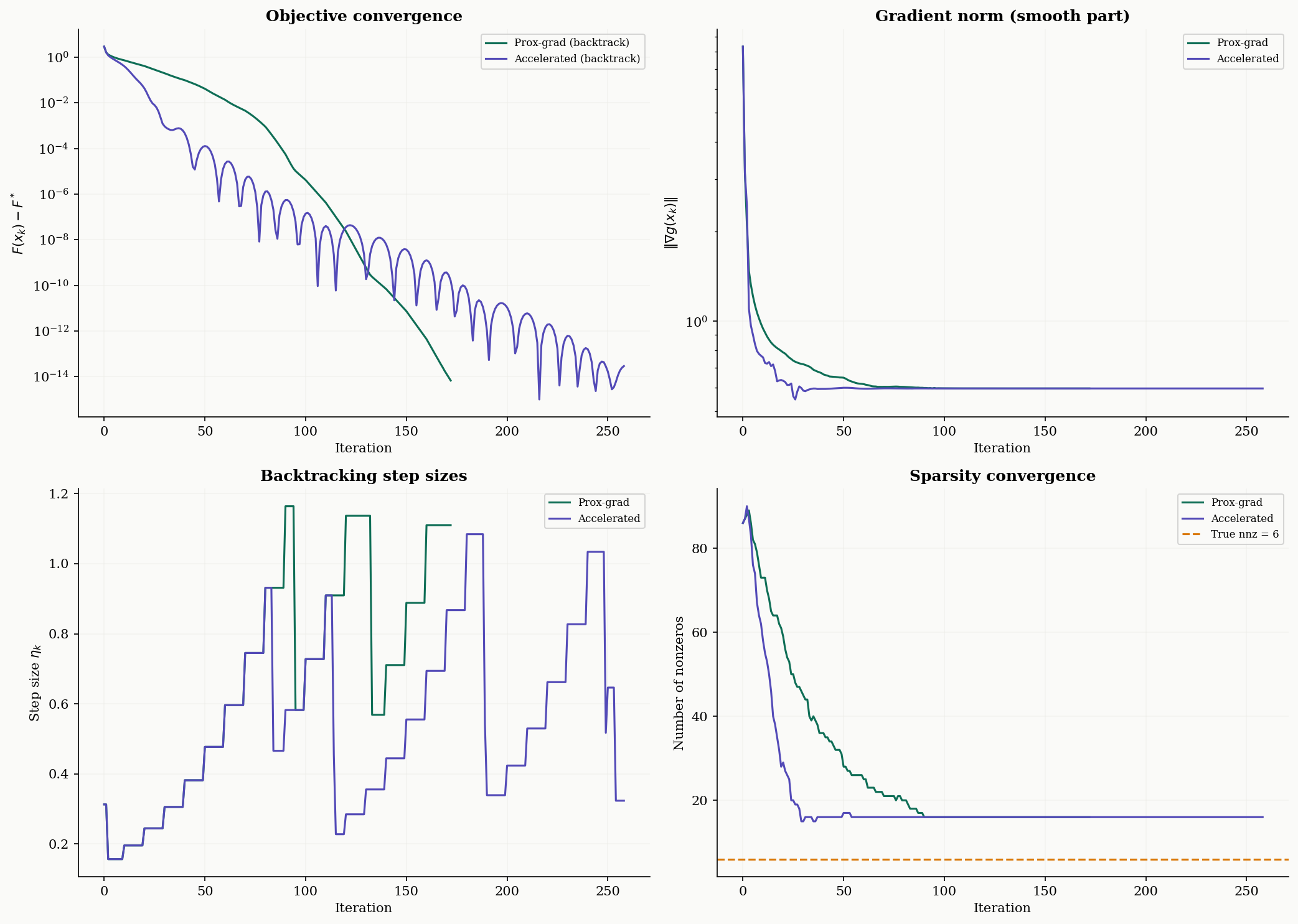
Computational Notes
We close with a full implementation of proximal gradient descent with Armijo backtracking — the version you’d actually use in practice, with convergence diagnostics.
Backtracking step size selection. Instead of computing exactly (which requires an eigendecomposition), backtracking finds a suitable step size adaptively. Starting from an initial estimate , it doubles until the sufficient decrease condition is satisfied:
This ensures the step size is never too large while allowing it to be larger than when the local curvature is smaller.
def proximal_gradient_bt(A, b, lam, x0=None, max_iter=500, tol=1e-8,
accelerated=False, verbose=False):
"""
Proximal gradient for Lasso: min (1/2)||Ax-b||^2 + lam*||x||_1
with Armijo backtracking for step size selection.
Parameters
----------
A : (n, p) array
b : (n,) array
lam : float, regularization parameter
x0 : initial point (default: zeros)
max_iter : max iterations
tol : stopping tolerance on relative change
accelerated : if True, use FISTA momentum
Returns
-------
x : solution
info : dict with convergence diagnostics
"""
n_obs, p_dim = A.shape
if x0 is None:
x0 = np.zeros(p_dim)
x = x0.copy()
x_prev = x.copy()
t_k = 1.0
L_est = 1.0
AtA = A.T @ A
Atb_vec = A.T @ b
info = {'f_vals': [], 'grad_norms': [], 'step_sizes': [], 'nnz': []}
def f_smooth(x):
r = A @ x - b
return 0.5 * np.dot(r, r)
def grad_smooth(x):
return AtA @ x - Atb_vec
def F_obj(x):
return f_smooth(x) + lam * np.linalg.norm(x, 1)
for k in range(max_iter):
if accelerated and k > 0:
t_next = (1 + np.sqrt(1 + 4 * t_k**2)) / 2
y = x + ((t_k - 1) / t_next) * (x - x_prev)
t_k = t_next
else:
y = x
g = grad_smooth(y)
f_y = f_smooth(y)
# Backtracking: find step size that satisfies descent condition
while True:
eta_k = 1.0 / L_est
x_new = soft_threshold(y - eta_k * g, eta_k * lam)
f_new = f_smooth(x_new)
d = x_new - y
if f_new <= f_y + np.dot(g, d) + (L_est / 2) * np.dot(d, d):
break
L_est *= 2
# Adaptive decrease of L_est for efficiency
if k % 10 == 0 and L_est > 1.0:
L_est *= 0.8
x_prev = x.copy()
x = x_new
info['f_vals'].append(F_obj(x))
info['grad_norms'].append(np.linalg.norm(g))
info['step_sizes'].append(eta_k)
info['nnz'].append(np.sum(np.abs(x) > 1e-8))
# Stopping criterion: relative change
if k > 0 and abs(info['f_vals'][-1] - info['f_vals'][-2]) < tol * abs(info['f_vals'][-2]):
break
return x, infoConvergence diagnostics. A well-implemented proximal gradient solver tracks four quantities:
- Objective value — should decrease monotonically (for ISTA; FISTA may oscillate).
- Gradient norm — measures how close the smooth part is to stationarity.
- Step size — should stabilize; rapid changes indicate numerical issues.
- Sparsity (number of nonzeros) — should converge to a stable support.
Connections & Further Reading
Proximal methods sit at the intersection of convex analysis, gradient-based optimization, and linear algebra — drawing on the foundations of the first two topics in the Optimization track and connecting forward to constrained optimization.
| Topic | Connection |
|---|---|
| Convex Analysis | Every proximal operator solves a convex minimization problem. The subdifferential optimality condition becomes the fixed-point condition . Conjugate functions and the Moreau envelope are dual objects connected by the Fenchel–Moreau theorem. |
| Gradient Descent & Convergence | Proximal gradient descent generalizes gradient descent to composite objectives . When , the proximal step reduces to the identity and we recover vanilla GD. The convergence analysis parallels the Descent Lemma, and FISTA inherits Nesterov’s momentum machinery. Mirror descent from GD is a special case of the proximal point algorithm with Bregman divergence. |
| The Spectral Theorem | The condition number that governs proximal gradient convergence involves eigenvalues of the Hessian. For quadratic , the Spectral Theorem gives the eigendecomposition that determines and . |
| Singular Value Decomposition | The proximal operator of the nuclear norm requires computing the SVD and applying soft-thresholding to the singular values — the singular value thresholding operator, which is the key subroutine in low-rank matrix recovery. |
| Lagrangian Duality & KKT | ADMM is a dual decomposition method: it applies Douglas–Rachford to the dual of the consensus problem. The KKT conditions generalize the fixed-point characterization to constrained settings. |
The Optimization Track
Convex Analysis
├── Gradient Descent & Convergence
│ └── Proximal Methods (this topic)
└── Lagrangian Duality & KKTConnections
- Every proximal operator solves a convex minimization problem. The subdifferential optimality condition 0 ∈ ∂f(x*) from Convex Analysis becomes the fixed-point condition x* = prox_f(x*) that characterizes solutions. Conjugate functions and the Moreau envelope are conjugate-dual objects connected by the Fenchel–Moreau theorem. convex-analysis
- Proximal gradient descent generalizes gradient descent to composite objectives F = g + h. When h = 0 (no non-smooth term), the proximal step reduces to the identity and we recover vanilla gradient descent. The convergence analysis parallels the Descent Lemma framework, and FISTA inherits the Nesterov acceleration machinery. gradient-descent
- The condition number κ = L/μ that governs proximal gradient convergence for strongly convex problems involves eigenvalues of the Hessian. For quadratic smooth terms g(x) = (1/2)x^TAx, the Spectral Theorem provides the eigendecomposition that determines L and μ. spectral-theorem
- The proximal operator of the nuclear norm (the matrix analogue of the ℓ₁ norm) requires computing the SVD and applying soft-thresholding to the singular values. This singular value thresholding operator is the key subroutine in low-rank matrix recovery via proximal methods. svd
References & Further Reading
- book Convex Optimization — Boyd & Vandenberghe (2004) Chapter 6: Proximal algorithms in the context of constrained optimization
- book First-Order Methods in Optimization — Beck (2017) Chapters 6-10: The primary reference — proximal operators, proximal gradient, FISTA, splitting methods
- book Convex Optimization: Algorithms and Complexity — Bubeck (2015) Chapter 4: Proximal and projection methods, mirror descent connections
- paper Proximal Algorithms — Parikh & Boyd (2014) The comprehensive survey — proximal operators, ADMM, splitting methods, applications
- paper A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems — Beck & Teboulle (2009) The FISTA paper — accelerated proximal gradient with O(1/k²) convergence
- paper Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers — Boyd, Parikh, Chu, Peleato & Eckstein (2011) The ADMM monograph — theory, applications, and distributed computing
- paper A Douglas–Rachford Splitting Approach to Nonsmooth Convex Variational Signal Recovery — Combettes & Pesquet (2007) Douglas–Rachford splitting for signal processing and inverse problems