Minimum Description Length
Model selection as data compression — the shortest total description identifies the best model
Overview & Motivation
Every statistician and every machine learning practitioner faces the same core problem: given data, which model should we use? Fit a polynomial of degree 3 or degree 15? Use a Gaussian mixture with 2 components or 20? The model that fits the training data best — the one with the highest likelihood — is almost never the right answer, because it overfits. We need a principled way to balance fit against complexity.
The Minimum Description Length (MDL) principle, introduced by Jorma Rissanen in 1978, provides exactly that balance by reframing model selection as a compression problem. The idea is beautifully concrete: imagine you want to send your dataset to a colleague using as few bits as possible. You can first describe a model (costing bits), then describe the data given that model (costing bits). The best model is the one that minimizes the total description length:
A simple model costs few bits to describe but leaves large residuals; a complex model describes the data well but costs many bits itself. The minimum is the sweet spot — the model that captures the genuine structure in the data without encoding noise.
This is Occam’s Razor made precise: among models that explain the data equally well, prefer the simplest one — and “simplest” means “shortest to describe.”
Prerequisites: This topic builds on KL Divergence & f-Divergences, particularly the information-theoretic interpretation of divergence as coding redundancy. Familiarity with Shannon Entropy & Mutual Information is essential — especially source coding and the connection between entropy and optimal code lengths.
What We Cover
- Two-part codes and crude MDL — the description-length trade-off , Rissanen’s universal code for integers, and model selection as compression
- Kolmogorov complexity — the ideal but uncomputable measure of descriptive complexity, and why MDL provides a practical alternative
- Stochastic complexity and refined MDL — the Normalized Maximum Likelihood distribution, parametric complexity, and Shtarkov’s minimax optimality theorem
- Fisher information and asymptotic complexity — the geometric structure hidden inside model complexity, and why BIC is a crude MDL approximation
- MDL and Bayesian model selection — the surprising asymptotic equivalence of stochastic complexity and the marginal likelihood under Jeffreys prior
- Prequential codes and online MDL — sequential model selection that avoids the normalization problem entirely
- MDL for practical model selection — feature selection, distribution family selection, and overfitting detection
Two-Part Codes & Crude MDL
The simplest version of MDL works with two-part codes: first encode the model, then encode the data given the model. We need to make both parts precise.
Encoding Models
Suppose our model class is a family of polynomials of degree . To encode “degree ,” we need a code for positive integers. Using a fixed-length code wastes bits on small values; a variable-length code does better.
Definition 1 (Two-Part Code / Crude MDL).
Given a countable collection of models and a coding scheme that assigns code length to each model and to the data given model , the crude MDL principle selects the model minimizing:
where is typically the negative log-likelihood under the maximum likelihood estimator:
For the model code length, Rissanen proposed a universal code for positive integers:
Definition 2 (Universal Code for Integers).
Rissanen’s universal code assigns to positive integer the code length:
where the sum includes only positive terms. The constant normalizes the code so that the implied distribution sums to 1 over positive integers. This is a universal code: it does not assume any prior distribution on model complexity.
Example: Polynomial Regression
Consider fitting a polynomial of degree to noisy observations. The model has free parameters (coefficients). Using bits of precision per coefficient, the two-part code length is:
where is the residual variance under the degree- fit. The model code grows with ; the data code shrinks as the fit improves. The minimum total code length selects a degree that balances these competing pressures.
The interactive visualization below demonstrates this trade-off. Try increasing the noise level — MDL selects simpler models when the signal-to-noise ratio is low.
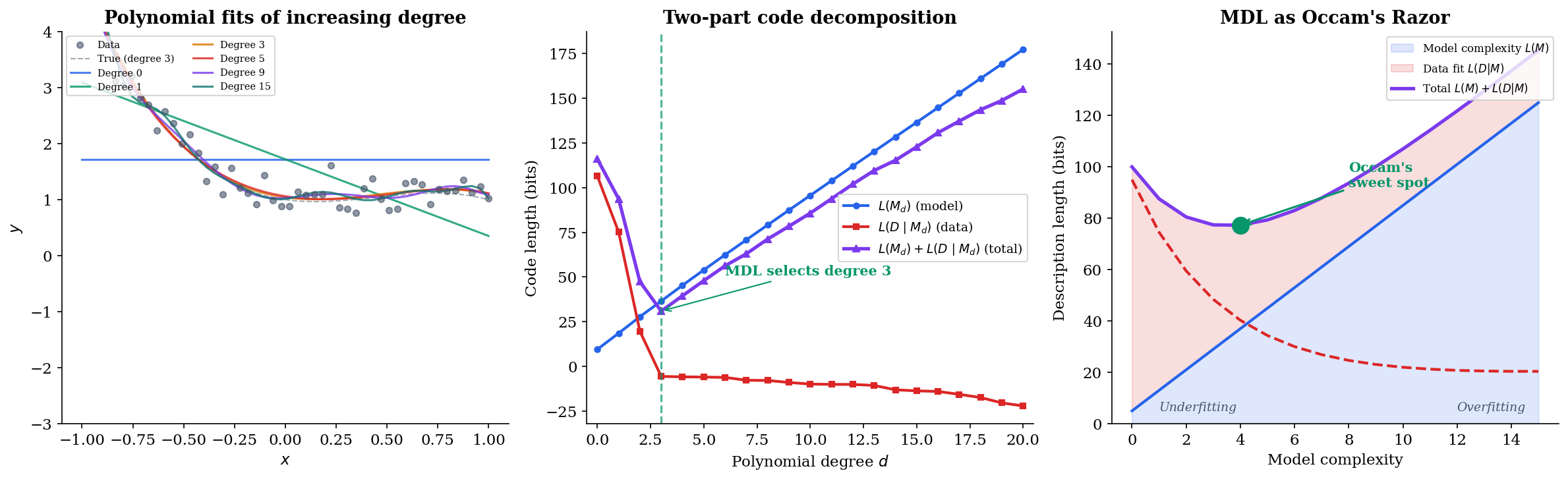
The left panel shows how the polynomial fit tightens as degree increases; the right panel reveals the two-part code decomposition. The total code length (purple line) reaches its minimum at a degree that neither underfits nor overfits — this is the MDL-optimal model.
Kolmogorov Complexity
Before we can refine MDL, we need to understand the ideal notion of descriptive complexity — one that Rissanen’s practical MDL approximates.
Definition 3 (Kolmogorov Complexity).
The Kolmogorov complexity of a binary string with respect to a universal Turing machine is:
where denotes the length of program in bits. In words: is the length of the shortest program that outputs and halts.
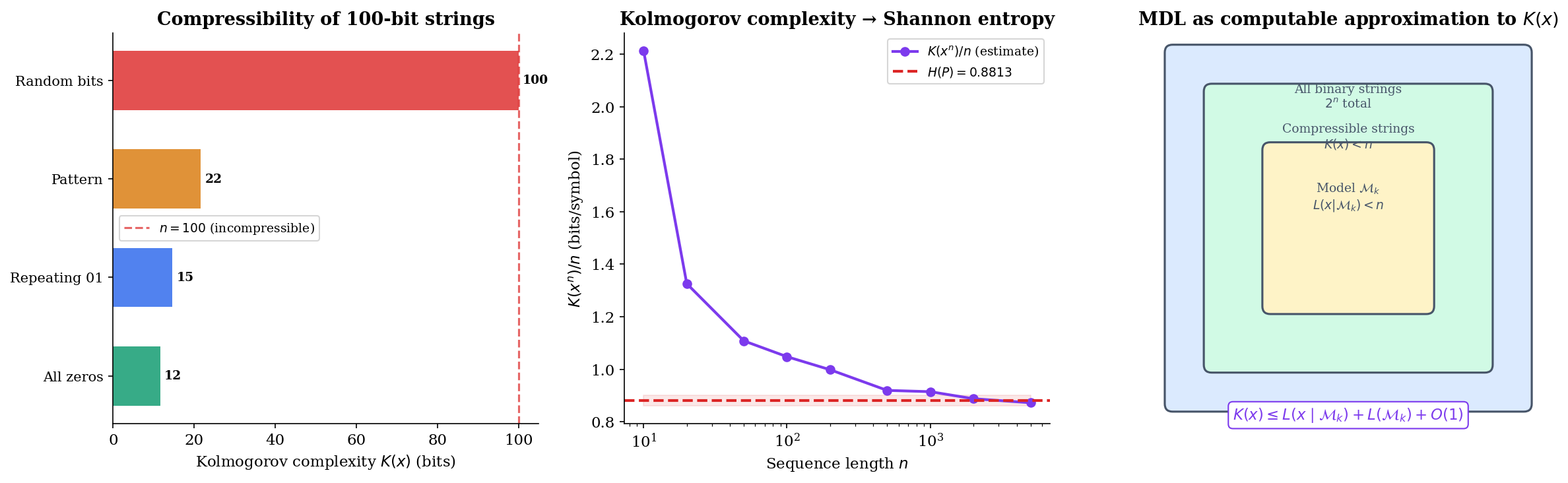
captures the intuitive notion of the “true complexity” of a string. A string of all zeros has low Kolmogorov complexity (a short loop produces it), while a random string has complexity close to its length (no program shorter than the string itself can produce it).
Theorem 1 (Invariance Theorem).
For any two universal Turing machines and , there exists a constant (depending only on and , not on ) such that:
for all strings .
Proof.
The key idea is simulation. Since is universal, there exists a program that makes simulate . For any string with , we can construct a program for : the simulator followed by . This gives . By symmetry, for some simulator . Setting completes the proof.
∎The invariance theorem means that Kolmogorov complexity is well-defined up to an additive constant — the choice of reference machine doesn’t matter asymptotically. We drop the subscript and write simply .
The fundamental connection between Kolmogorov complexity and Shannon entropy:
Proposition 1 (Kolmogorov Complexity and Entropy).
If are i.i.d. draws from a distribution with entropy , then:
Proof.
The upper bound follows from the asymptotic equipartition property (AEP): with high probability, lies in the typical set, which has elements. A program that encodes the index within the typical set uses bits. The lower bound comes from the incompressibility lemma: random strings cannot be systematically compressed below their entropy rate.
∎This proposition reveals the deep connection: Kolmogorov complexity is the individual-sequence analogue of Shannon entropy. But there’s a fatal practical problem: is uncomputable. No algorithm can compute for all inputs — this follows from the halting problem. MDL sidesteps uncomputability by restricting to computable coding schemes, providing a practical upper bound on .
Stochastic Complexity & Refined MDL
Crude MDL has a troubling dependence on arbitrary choices: the precision used to encode coefficients, the integer code for model indices. Refined MDL eliminates these choices by using a single universal code — the Normalized Maximum Likelihood (NML) distribution.
Definition 4 (Stochastic Complexity).
The stochastic complexity of a data sequence relative to a parametric model class is:
where is the Normalized Maximum Likelihood distribution defined below.
Definition 5 (Normalized Maximum Likelihood (NML)).
The NML distribution for model class is:
where is the maximum likelihood estimator for data , and the parametric complexity is the normalizing constant:
The sum ranges over all possible data sequences of length . (For continuous data, the sum becomes an integral.)
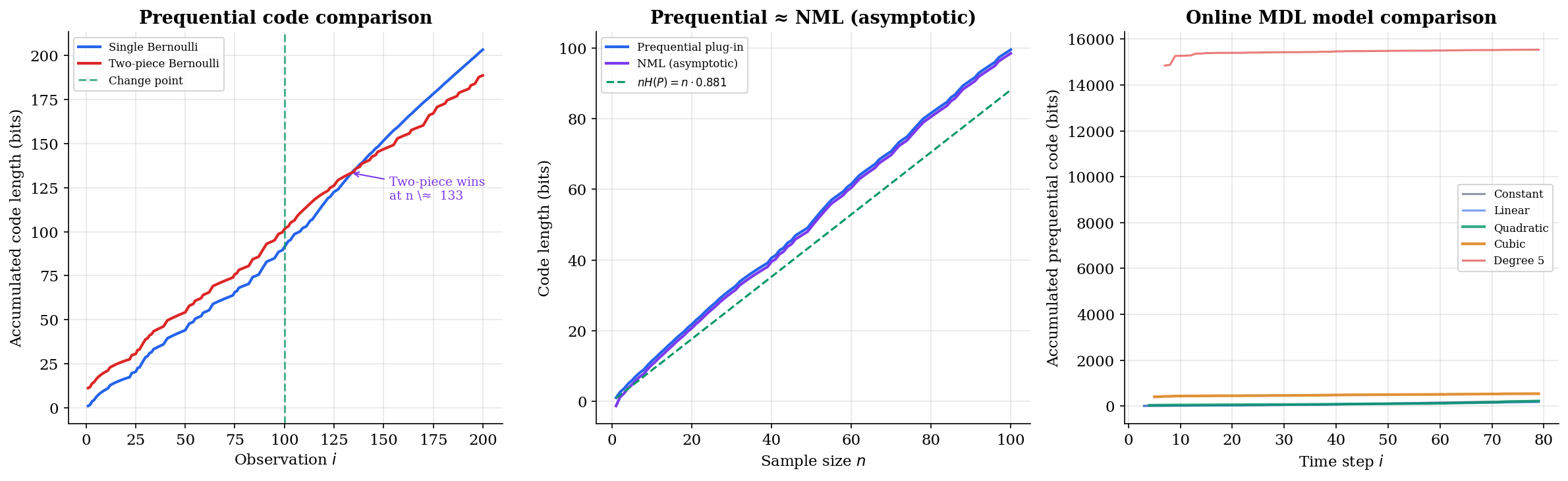
The NML distribution is remarkable: it assigns to each dataset the maximum likelihood for that dataset, but normalized so the result is a proper probability distribution. Why is this a good universal code?
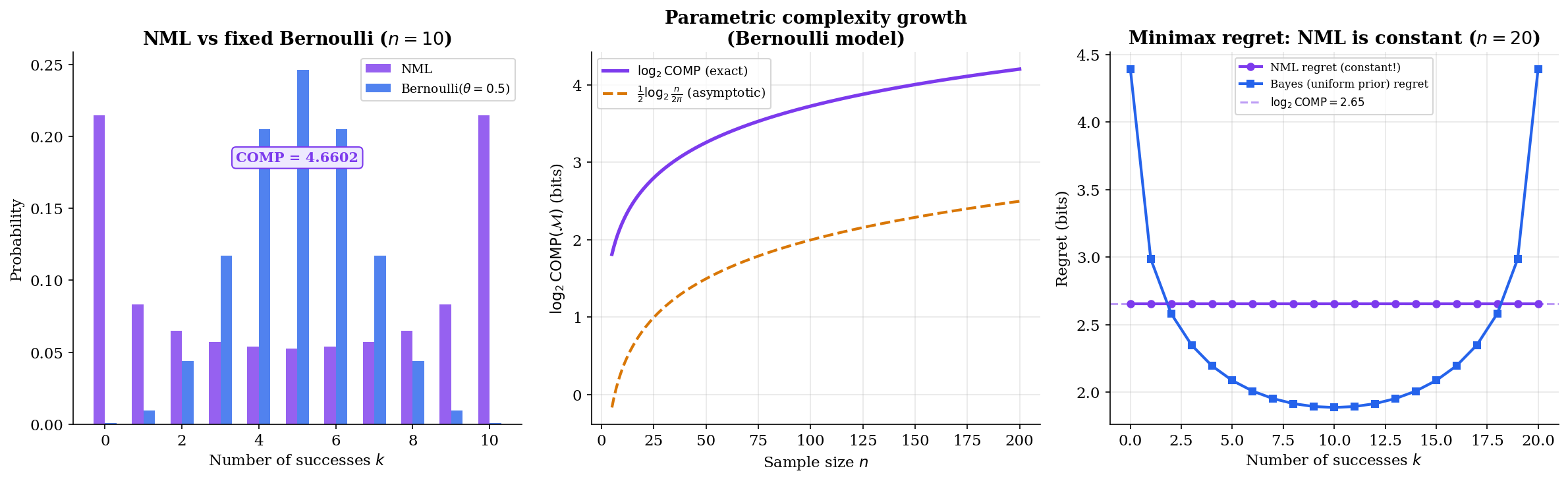
Theorem 2 (Shtarkov's Minimax Optimality).
The NML distribution achieves constant regret across all data sequences:
for all . Moreover, NML is the unique distribution achieving the minimax regret:
Proof.
The regret of NML is:
This is constant — it does not depend on . For any other distribution , the maximum regret over all is at least . To see this, suppose achieves maximum regret . Then for all :
Summing over all : , a contradiction. Therefore NML achieves the minimax regret, and this regret equals .
∎The interactive visualization below shows NML in action for the Bernoulli model. Notice that the NML regret (purple line) is perfectly flat — constant across all possible numbers of successes. The comparison codes (Bayes, plug-in) achieve lower regret for some outcomes but much higher regret for others.
Fisher Information & Asymptotic Complexity
Computing exactly requires summing over all possible datasets — exponential in . Rissanen’s asymptotic expansion reveals the geometric structure hiding inside this sum.
Theorem 3 (Asymptotic Parametric Complexity (Rissanen 1996)).
For a -dimensional parametric model class with parameter space and Fisher information matrix , as :
This expansion has a beautiful geometric interpretation:
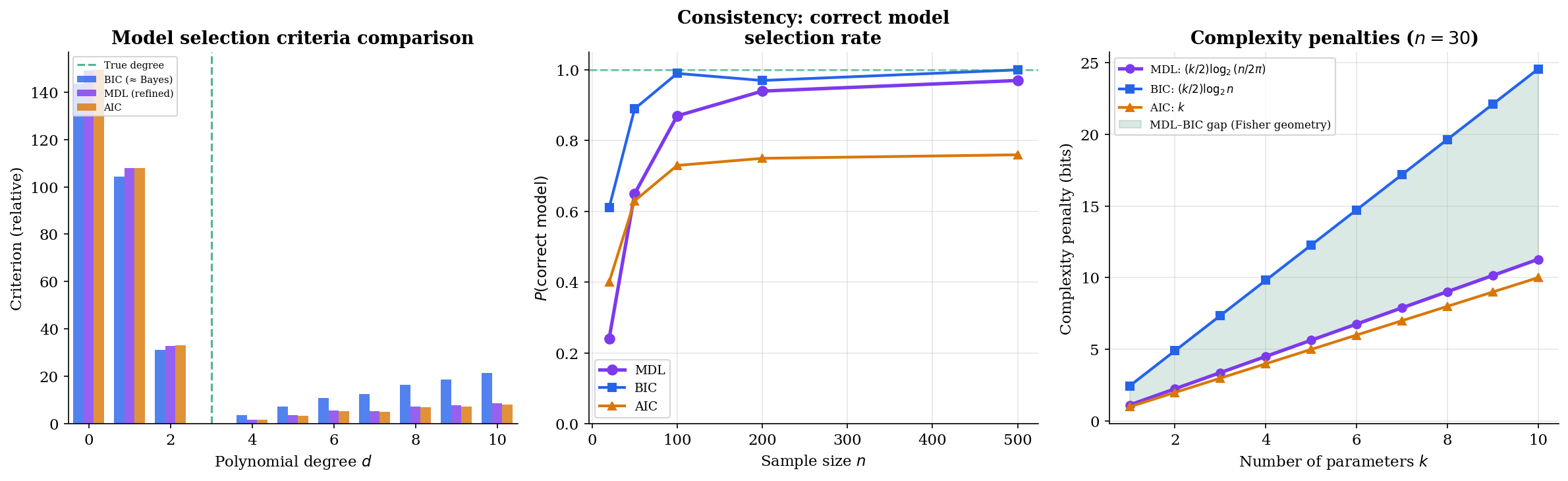
- The term is the dominant contribution — it grows with both the number of parameters and the sample size . This is essentially the BIC penalty.
- The integral is the volume of the model manifold in the Fisher information metric. Models with larger parameter spaces (in the Fisher metric sense) receive a larger complexity penalty. This is the term that distinguishes refined MDL from BIC.
Corollary 1 (Stochastic Complexity ≈ BIC + Geometry).
The stochastic complexity can be approximated as:
The first two terms match the BIC (up to additive constants); the third term is the geometric correction that BIC misses.
Proposition 2 (BIC as Crude MDL Approximation).
The Bayesian Information Criterion:
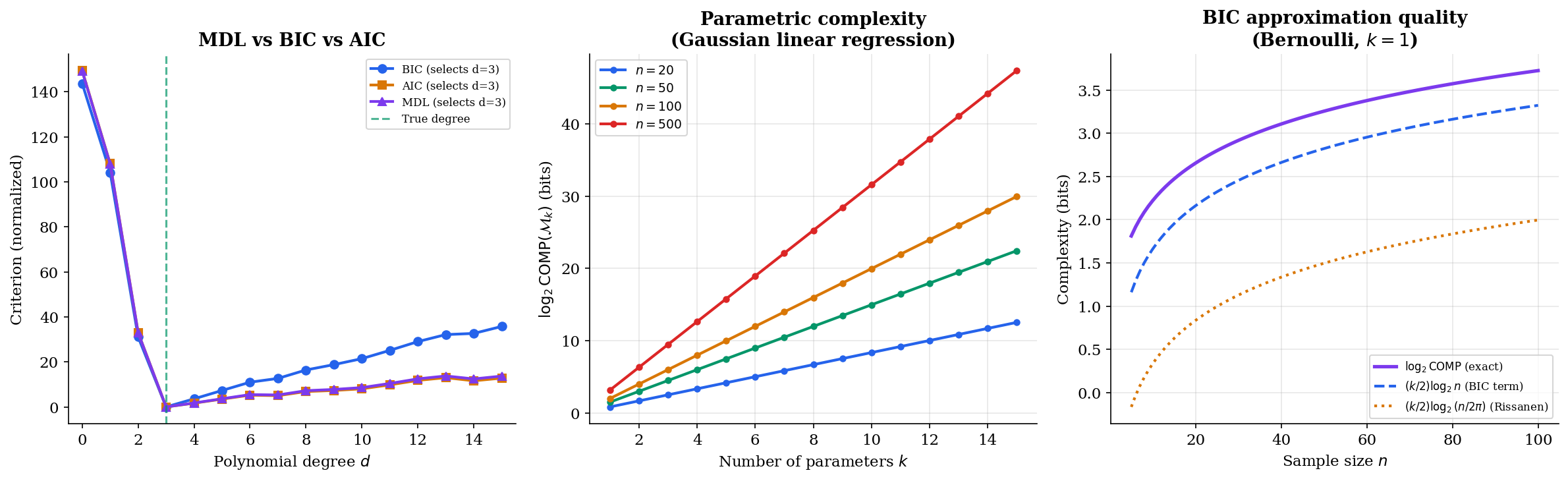
is a rough approximation to twice the stochastic complexity, dropping the Fisher information integral and using in place of . BIC is consistent (selects the true model as ) but generally less accurate than refined MDL for finite samples.
Remark (BIC as Practical MDL).
When to use BIC vs. refined MDL: BIC is appropriate for quick model comparison when exact Fisher information computation is infeasible, or when the models being compared have the same functional form (the Fisher integral cancels in the difference). Refined MDL (stochastic complexity) is preferable when comparing models of different types — e.g., Gaussian vs. Poisson — where the Fisher volumes differ.
The visualization below compares all three criteria. Note that MDL and BIC agree on the selected model degree most of the time, but AIC tends to overfit — it selects higher-degree models because its penalty () doesn’t grow with sample size.
MDL and Bayesian Model Selection
MDL and Bayesian model selection appear to come from completely different philosophical traditions — coding theory vs. probabilistic inference. Yet they converge asymptotically in a surprising way.
Theorem 4 (Bayesian Marginal Likelihood and Stochastic Complexity).
Under Jeffreys prior , the log marginal likelihood satisfies:
as . That is, the stochastic complexity and the negative log marginal likelihood under Jeffreys prior are asymptotically equivalent.
Proof.
By Laplace approximation, the marginal likelihood concentrates around the MLE:
where is the observed Fisher information. Taking the negative logarithm:
Collecting terms and using , we recover the stochastic complexity up to terms.
∎This equivalence explains a deep fact: Jeffreys prior is not just a convenient default — it is the unique prior that makes Bayesian model selection asymptotically equivalent to MDL. Despite their different foundations (MDL is frequentist and prior-free; Bayesian inference requires a prior), the two frameworks agree in the large-sample limit when the Bayesian uses the “right” prior.
The philosophical differences remain important:
- MDL treats the code length as fundamental — models are evaluated by their compression efficiency. No prior is needed; the parametric complexity arises from the structure of the model class itself.
- Bayesian model selection treats the posterior probability as fundamental — models are evaluated by how well they predicted the data, averaged over the prior. The prior encodes genuine beliefs about which parameter values are more plausible.
- When the prior is misspecified (i.e., not Jeffreys), the two methods can disagree — and MDL is often more robust because it doesn’t rely on prior correctness.
Prequential Codes & Online MDL
There’s a practical problem with NML: computing requires summing over all possible datasets of length . For many model classes, this sum is intractable. Prequential (predictive) MDL bypasses this entirely by processing data sequentially.
Definition 6 (Prequential Code).
The prequential code length for a data sequence under a sequential prediction strategy is:
where is the predictive probability assigned to given the first observations.
The prequential code is always a valid code (Kraft inequality is satisfied by the chain rule of probability), and it’s always computable — no normalization over all possible datasets is needed.
A natural prediction strategy is the prequential plug-in code: use the MLE fitted on past data to predict the next observation. For the Bernoulli model with Laplace smoothing:
where is the number of ones in the first observations.
Theorem 5 (Prequential Code and Stochastic Complexity).
The prequential plug-in code achieves:
as . That is, the prequential code converges to the stochastic complexity, with the same leading-order complexity penalty.
Proposition 3 (Consistency of MDL).
Let be a nested sequence of model classes with being the smallest class containing the true distribution. Both NML-based and prequential MDL select with probability tending to 1 as , provided the parametric complexity grows as .
Proof.
For any model with , the difference in stochastic complexities satisfies:
The log-likelihood difference is (bounded in probability by Wilks’ theorem), while the complexity penalty grows as . Therefore overly complex models are eventually penalized out. For , the log-likelihood penalty grows linearly in (model misspecification), outpacing any complexity savings. The true model minimizes stochastic complexity asymptotically.
∎Proposition 4 (Prequential Code via Bayes Mixture).
The prequential code using a Bayesian predictive distribution with prior :
yields a prequential code length equal to the negative log marginal likelihood:
This is a consequence of the chain rule: .
The visualization below shows prequential MDL in action for change-point detection. Two models compete: a single Bernoulli (one parameter for the whole sequence) and a two-piece Bernoulli (different parameters before and after a change point). Watch how the two-piece model initially incurs higher overhead but eventually wins when the distributional shift becomes evident.
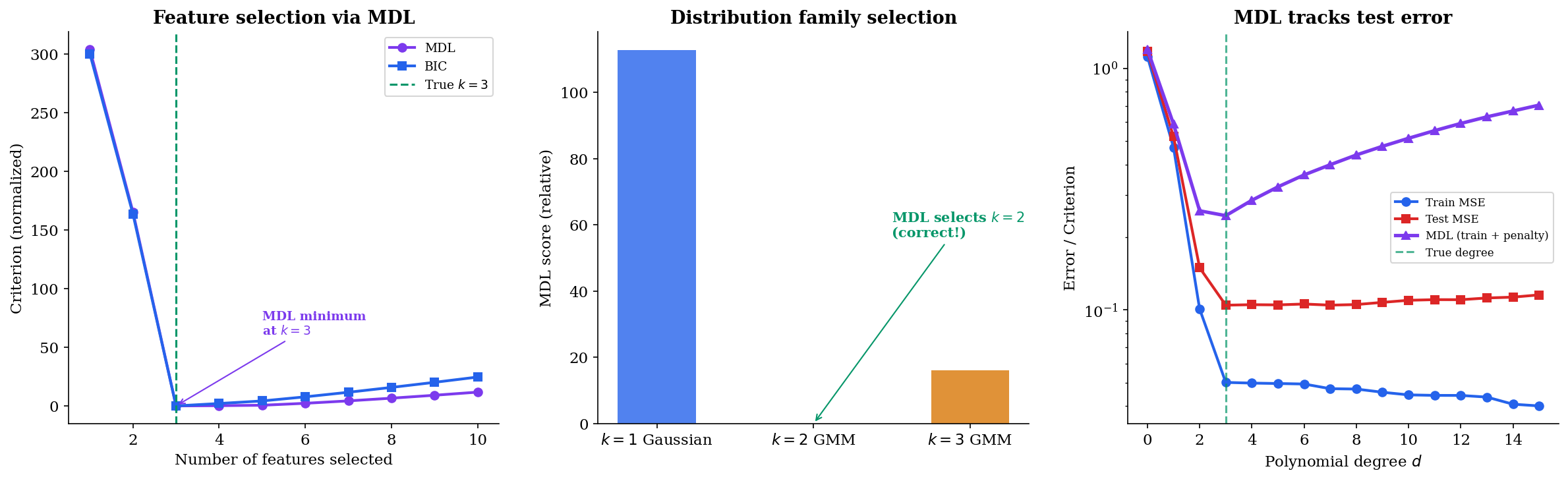
MDL for Practical Model Selection
How does MDL translate to the everyday tasks of machine learning: choosing features, selecting the number of components, detecting overfitting?
Proposition 5 (MDL for Linear Regression).
For linear regression with features, observations, and Gaussian errors, the refined MDL criterion reduces to:
where and depends on the Fisher information geometry. When is ignored (equal across models), this reduces to BIC up to a constant.
Feature selection via MDL. In forward feature selection, we greedily add the feature that reduces the total MDL criterion the most. The MDL penalty automatically trades off the improvement in fit against the cost of an additional parameter. Unlike cross-validation, MDL requires no held-out data.
Theorem 6 (MDL Consistent Model Selection).
Let the true model have nonzero features. Forward selection using the MDL (or BIC) criterion selects features with probability tending to 1 as , provided:
- The penalty grows as (satisfied by both BIC and MDL).
- The penalty grows slower than (ensuring we don’t underfit).
AIC is not consistent: its fixed penalty allows overfitting to persist even as .
Proof.
The proof follows the same logic as Proposition 3. For any model with features, the likelihood improvement from the spurious features is (by Wilks’ theorem), while the penalty cost is . So spurious features are eventually rejected. For AIC, the penalty is (constant), which does not dominate the likelihood improvement, so AIC selects too many features with non-vanishing probability.
∎
Computational Notes
MDL in Practice: BIC as a Proxy
For most practical applications, BIC is a reasonable proxy for MDL:
BIC is fast to compute, consistent, and readily available in every statistics package. Use it when:
- Comparing models of the same type (the Fisher volume term cancels)
- The sample size is large enough that asymptotic approximations hold
- You don’t need the geometric correction from the Fisher information
Remark (MDL and Regularization).
The MDL penalty on model complexity has a natural connection to regularization — penalizing the number of nonzero parameters. The refined MDL score assigns a cost of roughly bits per parameter. In the regression setting, this is equivalent to an penalty with strength . Unlike or regularization (which shrink parameters toward zero), the MDL/ approach performs hard selection: each feature is either in the model or out.
Remark (MDL and Neural Network Compression).
MDL provides an information-theoretic framework for understanding neural network compression. The total description length of a network is . Pruning (removing weights), quantization (reducing precision), and knowledge distillation (compressing into a smaller network) can all be understood as reducing the first two terms. The lottery ticket hypothesis — that sparse subnetworks can match the performance of the full network — is a statement about MDL: the compressed description (sparse architecture + remaining weights) has lower total code length than the full network. This connects modern deep learning compression to Rissanen’s 1978 insight that the best model is the one with the shortest total description.
Summary Comparison
| Criterion | Formula | Penalty | Consistent? | Requires |
|---|---|---|---|---|
| AIC | Fixed () | No | Only , | |
| BIC | Yes | Only , , | ||
| Refined MDL | geometry | Yes | Fisher information | |
| NML (exact) | Minimax optimal | Yes | COMP enumeration | |
| Prequential MDL | Adaptive | Yes | Sequential predictions |
Connections & Further Reading
Connection Map
| Topic | Relationship |
|---|---|
| Shannon Entropy & Mutual Information | MDL formalizes source coding for model selection: the shortest description length equals the entropy under the true model. Shannon’s source coding theorem underpins the coding interpretation of MDL. |
| KL Divergence & f-Divergences | The regret of a universal code is bounded by . The stochastic complexity decomposes into the maximized log-likelihood plus the KL divergence from the NML distribution to the MLE model. |
| Rate-Distortion Theory | Rate-distortion theory and MDL are dual perspectives on compression: rate-distortion minimizes bits for a fidelity constraint, while MDL uses total description length for model selection. The information bottleneck connects both viewpoints. |
| Convex Analysis | The NML optimization is a minimax problem solved by convex duality. The parametric complexity integral involves the Fisher information geometry, connecting to the convex structure of exponential families. |
| Information Geometry & Fisher Metric | The asymptotic parametric complexity involves — the volume of the model manifold in the Fisher metric. MDL model complexity has a geometric interpretation as the “size” of the model in information space. |
| PAC Learning & Computational Learning Theory (coming soon) | MDL and PAC learning provide complementary perspectives on generalization: MDL penalizes model complexity via description length, while PAC bounds generalization error via VC dimension. Occam’s razor lemma connects both: short descriptions imply small generalization error. |
Notation Reference
| Symbol | Meaning |
|---|---|
| Code length for model (complexity) | |
| Code length for data given model (goodness-of-fit) | |
| Rissanen’s universal code for positive integer | |
| Kolmogorov complexity of string | |
| Stochastic complexity of under model | |
| Normalized Maximum Likelihood distribution | |
| Parametric complexity: | |
| Fisher information matrix at parameter | |
| Maximum likelihood estimator for data | |
| Prequential (predictive) code length | |
| Bayesian Information Criterion: |
Connections
- The regret of a universal code is bounded by D_KL(p_θ* || p_NML). The stochastic complexity decomposes into the maximized log-likelihood plus a term interpretable as the KL divergence from the NML distribution to the best model in the class. kl-divergence
- MDL formalizes source coding for model selection: the shortest description length equals H(P) under the true model. Shannon's source coding theorem underpins the coding interpretation — entropy sets the fundamental limit that MDL approaches. shannon-entropy
- Rate-distortion theory and MDL are dual perspectives on compression: rate-distortion minimizes bits for a fidelity constraint, while MDL uses total description length for model selection. Both derive from Shannon's operational approach to information. rate-distortion
- The NML optimization is a minimax problem solved by convex duality. The parametric complexity integral involves the Fisher information geometry, connecting to the convex structure of exponential families. convex-analysis
- The asymptotic parametric complexity involves the integral of the square root of the Fisher information determinant — the volume of the model manifold in the Fisher metric. MDL model complexity has a geometric interpretation as the size of the model in information space. information-geometry
References & Further Reading
- book The Minimum Description Length Principle — Grünwald (2007) The definitive textbook on MDL — covers two-part codes, refined MDL, NML, prequential codes, and applications
- book Information and Complexity in Statistical Modeling — Rissanen (2007) Rissanen's own monograph on stochastic complexity and refined MDL
- paper Modeling by Shortest Data Description — Rissanen (1978) The foundational paper introducing the MDL principle
- paper The Minimum Description Length Principle in Coding and Modeling — Barron, Rissanen & Yu (1998) Comprehensive treatment of MDL, NML, and connections to Bayesian inference
- paper Minimum Description Length Revisited — Grünwald & Roos (2020) Modern survey of MDL with connections to deep learning and neural compression
- book An Introduction to Kolmogorov Complexity and Its Applications — Li & Vitányi (2019) Standard reference on algorithmic information theory — Kolmogorov complexity and its connections to MDL