High-Dimensional Regression
The lasso at $p \gg n$ — definition, geometry, and ISTA / FISTA / coordinate-descent solvers; the Bickel–Ritov–Tsybakov (2009) oracle inequality at the $\sigma^2 s \log(p)/n$ rate under the restricted-eigenvalue condition; the variable-selection story under the irrepresentable condition; ridge / elastic-net / adaptive-lasso variants; and the Zhang–Zhang / Javanmard–Montanari / van de Geer–Bühlmann–Ritov–Dezeure (2014) debiased lasso for valid $\sqrt n$-confidence inference on individual coefficients.
§1. From OLS to penalized regression
When the predictor matrix has more columns than rows, ordinary least squares stops being a single estimator and becomes a degenerate family — infinitely many vectors fit the training data perfectly, none of them generalize. This section establishes the high-dimensional regime, shows OLS failing on the canonical sparse-Gaussian-design problem we’ll reuse for the next eight sections, and introduces the two classical regularization remedies: ridge (L2-penalized) and lasso (L1-penalized). Ridge gives a unique solution and shrinks every coefficient smoothly toward zero; lasso gives a sparse solution and shrinks small coefficients all the way to zero. The geometric difference between those two penalties — corners on the L1 ball, smooth curvature on the L2 ball — is what makes the lasso the central object of this topic.
§1.1 The high-dimensional regime and where it appears
Standard regression theory assumes more observations than features (), often by orders of magnitude. The high-dimensional regime flips that: is comparable to or much larger than . Three places it shows up routinely:
- Genome-wide association studies (GWAS). Regress a phenotype on hundreds of thousands to millions of single-nucleotide polymorphisms. Typical scale is with patients; the ratio is normal, not extreme.
- Functional MRI. A whole-brain scan resolves voxels per timepoint; predicting a behavioral or clinical outcome from voxel-level activations gives with in the low hundreds.
- Text and high-cardinality categorical features. A bag-of-words encoding of even a modest corpus pushes into the millions while stays in the thousands.
These problems share more than — they also tend to be sparse: only a small subset of features carries the actual signal. A handful of SNPs drive most of the heritable variation in a quantitative trait; a focal brain region carries most of the predictive signal in an fMRI study; a few keywords carry most of the topic information in a document. The lasso’s design exploits this sparsity directly.
We’ll formalize sparsity as where — the true coefficient vector has only nonzero entries. The set is the support of , and is the sparsity level. We don’t know in advance; recovering it (or, more modestly, predicting well without recovering it) is the estimator’s job.
The canonical sparse high-dimensional dataset (DGP-1). We’ll reuse the same data-generating process across §§2–9 to make the comparisons concrete. Fix:
- , , .
- Rows iid with (AR(1) Toeplitz, weakly decaying off-diagonal correlation).
- for (contiguous active set), otherwise.
- Noise with .
- Population (computed: via the AR(1) sum over a 10×10 active block).
- Seed:
np.random.default_rng(42).
The §10 debiased-lasso coverage demonstration switches to to make OLS feasible as a baseline. All other sections reuse DGP-1.
§1.2 Why OLS fails: the rank-deficient normal equations
OLS minimizes the squared training loss:
with the closed-form solution when is invertible. Invertibility requires , which in turn requires .
When , the matrix has rank at most and is singular. The normal equations have infinitely many solutions: for any vector in the -dimensional null space of , both and achieve the same residual. The OLS objective has a flat plateau of global minima, all of them interpolating the training data exactly.
The standard pseudoinverse fix picks the minimum-norm solution from that plateau:
well-defined whenever has full row rank. But “minimum-norm OLS” is still OLS — it interpolates the training data (), the training MSE is exactly zero, and the test MSE is unbounded. Even before reaches , predictive performance degrades: as from below, the smallest singular value of approaches zero, blows up, and the OLS coefficient estimates inflate even though the in-sample fit looks great.
Sweep the active feature count from to on a fresh DGP-1 sample, fit OLS to each subproblem (using only the first columns of ), and plot train MSE and test MSE on log-y. Train MSE drops monotonically toward zero as approaches . Test MSE bottoms out near (the truth) and explodes by orders of magnitude as . The reader sees, in one picture, that OLS is incapable of using the sparsity structure — it doesn’t know that only 10 features matter, so it overfits aggressively as soon as it has the degrees of freedom to do so.
OLS on DGP-1 (n = 200, σ = 0.5, AR(1) ρ = 0.5, s = 10). Train MSE drops to zero as p_used → n; test MSE bottoms near p_used = s and explodes near the rank-deficiency boundary p_used = n. Hover any point for exact values. Computed live in-browser with Cholesky-based ridge OLS (jitter ε = 1e-8 for numerical stability at large p_used).

§1.3 Ridge regression as the L2 fix
Ridge regression resolves the rank-deficiency by adding a quadratic penalty:
where is the squared L2 norm and is a tuning parameter ( recovers OLS, shrinks every coefficient to zero). The closed form is:
The matrix is positive definite for any — its eigenvalues are bounded below by — so the inversion is well-defined regardless of whether or . Ridge restores uniqueness.
Two structural properties matter for what follows:
- Continuous shrinkage, dense solutions. Each coefficient is shrunk toward zero by a factor that depends on the corresponding singular value of , but no coefficient is set to exactly zero (with probability one over a continuous design). On DGP-1, ridge produces 500 nonzero coefficients even though only 10 features matter.
- Smoothness in . is a continuous, differentiable function of everywhere on . There’s no “selection event” — coefficients shrink, they don’t snap.
Ridge is the right tool when all features carry some signal and the goal is to stabilize coefficient estimates against multicollinearity. In the high-dimensional sparse regime where the truth has 10 active features out of 500, ridge’s refusal to zero out the 490 inactive features is a liability — every irrelevant coefficient contributes variance to the prediction. The standard formalstatistics treatment of ridge covers the case and the Bayesian Gaussian-prior interpretation; we’re using ridge here as the dense-shrinkage baseline that lasso will improve on.
§1.4 The lasso as the L1 alternative
The lasso (Tibshirani 1996) replaces the squared L2 penalty with an L1 penalty:
where is the L1 norm. The objective is convex (squared loss is convex, L1 norm is convex, sum of convex is convex), so any local minimum is a global minimum. But the L1 norm is not differentiable at zero, and that non-smoothness has two consequences that turn out to be central:
- Sparsity. The optimal solution has many coefficients exactly equal to zero, and the number of nonzero coefficients is controlled by . Geometrically, the L1 ball has corners at the coordinate axes; the constrained-form lasso solution is the point where the squared-loss contour first touches the L1 ball as the ball expands, and that contact point is generically at a corner — i.e., on a coordinate hyperplane, with one or more coefficients zero. The smooth L2 ball has no corners, which is why ridge solutions are dense. We’ll come back to this picture in §2.2 with an interactive viz.
- No closed form in general. Unlike ridge, the lasso has no general closed-form solution. There is one when the design is orthogonal (, derived in §3.1 via the soft-thresholding operator), but for general the solution requires an iterative solver. §3 covers coordinate descent, ISTA, and FISTA in detail.
The L1 penalty is the smallest convex penalty that produces sparsity. The non-convex L0 penalty would also produce sparse solutions — and is in some ways the “right” objective for variable selection — but the resulting optimization problem is best-subset selection, which is NP-hard. The L1 penalty is the convex relaxation of L0: among convex penalties that produce sparsity, it’s the simplest to state, the easiest to optimize, and the one with the best-developed statistical theory.
Side-by-side: ridge at three penalty levels () and lasso at three penalty levels (), all on the same DGP-1 sample. Ridge produces 500 nonzero coefficients at every — heavier penalization means smaller coefficients across the board, never exactly zero. The lasso at the CV-selected has only ~12 nonzero coefficients, mostly concentrated at the true active coordinates . The contrast is the visual punchline of the section.
Ridge (top row, three α levels) vs lasso (bottom row, three λ levels) on DGP-1 (n = 200, p = 500, s = 10, σ = 0.5). True active coordinates (j < 10) in black; 490 inactive coordinates in gray. Ridge is dense at every α; lasso at the CV-selected λ ≈ 0.056 produces a sparse fit concentrated at the true active set. Computed live in-browser via Cholesky-based ridge with pre-computed XᵀX (shared across α levels) and 200-iteration ISTA for lasso. Compute ~1 second; viz is hidden until scrolled into view.

§1.5 Roadmap
The rest of the topic answers four questions about the lasso. What does the estimator look like? §2 fills in the geometric picture and basic structural results — existence, uniqueness, KKT subgradient conditions. How do we compute it? §3 derives the soft-thresholding closed form for orthogonal designs and develops the iterative solvers (coordinate descent, ISTA, FISTA) used in general. Does it predict well, and does it recover the true support? §§4–6 work out the bias-variance trade-off, prove the headline non-asymptotic prediction-risk bound (the lasso oracle inequality, under the restricted-eigenvalue condition), and treat variable-selection consistency as a separate theorem with its own sufficient condition (irrepresentable). §7 covers practical selection by cross-validation and information criteria. §8 covers the ridge / elastic-net / adaptive-lasso variants and when each wins. §9 deepens the geometry of the high-dimensional regime — RIP, sub-Gaussian designs, the implication chain between conditions. Can we do inference with it? §10 is the inferential payoff: naive lasso confidence intervals undercover (PoSI; Berk et al. 2013), and the debiased-lasso construction (Zhang-Zhang 2014; Javanmard-Montanari 2014; van de Geer et al. 2014) restores valid coverage. §11 extends the lasso to non-Gaussian responses (logistic, Poisson). §12 closes with connections to double/debiased ML, causal inference, and the Bayesian counterpart in Sparse Bayesian Priors.
§2. The lasso estimator
The lasso is convex L1-penalized least squares — a well-defined, well-studied estimator with a clean geometric story and a precise first-order characterization. This section establishes the formal definition (in both penalized and constrained forms), develops the geometric intuition for why L1 penalization produces sparse solutions (corners on the L1 ball, smooth curvature on the L2 ball), addresses existence and uniqueness (Tibshirani 2013), and works out the KKT subgradient conditions that characterize every lasso solution. The KKT conditions are the load-bearing technical machinery for the rest of the topic — the soft-thresholding closed form in §3.1, the basic inequality in the oracle inequality proof of §5.2, and the debiased-lasso construction of §10.2 all derive from them.
§2.1 The L1-penalized least-squares definition
The lasso estimator is the minimizer of an L1-penalized squared loss:
Definition 1 (Lasso estimator).
For a design matrix , response , and tuning parameter , the lasso estimator is
where is the L1 norm.
Three things to note about the definition.
The scaling. The factor of in front of the squared loss is a convention that makes the gradient equal (no leading 2), and the normalization makes the objective an empirical average. With this scaling, has units of “covariate-response correlation” — comparable across sample sizes — and the optimal scales as (we’ll see this in §5). The scikit-learn convention (and the one we’ll use throughout the notebook) matches: Lasso(alpha=λ) minimizes , with the same out front.
Convexity. The squared loss is strongly convex in but only weakly convex in when has rank . The L1 norm is convex (every norm is), so the sum is convex. There are no local minima that aren’t global minima; the solution set is always a convex set in .
The L1 norm is not differentiable at zero. is differentiable everywhere except , where the subgradient is the closed interval . This non-smoothness is exactly what produces sparsity — and is also why the lasso has no closed-form solution in general (subgradients require a discrete case analysis at each coordinate).
Constrained-form duality. The penalized lasso is equivalent to the constrained-form lasso
via Lagrangian duality. For each there’s a corresponding budget , and conversely each corresponds to a unique . The mapping is monotone but not generally available in closed form. Both forms appear in the literature; the penalized form is more convenient for proofs (one term in the gradient, no constraint qualification needed), and the constrained form is more convenient for the geometric pictures we’ll draw next.
§2.2 Geometric picture: corners produce sparsity
Why does L1 penalization produce solutions with exact zeros? The cleanest answer is geometric: the L1 ball has corners on the coordinate axes, and the loss contour generically touches the ball at one of those corners.
Consider the constrained lasso in 2D with a fixed budget . The feasible region is a diamond — a square rotated 45 degrees — with vertices at and . The objective contours are concentric ellipses centered at with axes determined by the eigenvectors of . The constrained solution is the point where the smallest ellipse just touches the diamond.
If lies outside the diamond — which is the interesting case; otherwise the constraint is inactive — the contact point is on the diamond’s boundary. The boundary consists of four edges and four vertices. Generically, for almost every and , the contact is at a vertex, not a smooth point on an edge. At a vertex, one coordinate is exactly zero. Sparsity.
The L2 ball is the disk — smooth, no corners. The contact point with an ellipse is generically a smooth point on the disk’s boundary, with both coordinates nonzero. Density.
This picture extends to with . The L1 ball has vertices (one per coordinate-axis intersection), edges, and a hierarchy of lower-dimensional faces; contact at a -dimensional face means the solution has exactly nonzero coordinates. The L2 ball has no faces of any positive codimension; contact is always smooth, the solution is always dense.
β̂_OLS = (0.4, 1.6); Hessian H = [[1, 0.4], [0.4, 1]]; loss Q(β) = (β − β̂_OLS)ᵀ H (β − β̂_OLS). The amber dashed ellipse is the just-tangent loss contour at the L1 contact. As you drag t, watch the L1 contact stay pinned to the diamond's nearest vertex (one coordinate exactly zero) while the L2 contact slides smoothly around the disk. The L1 vertex generically achieves a lower loss than any edge interior — that's the geometric source of sparsity.

The figure is the geometric content of the lasso. Everything else — the soft-thresholding closed form (§3.1), the lasso path (§4.4), the active-set / equicorrelation-set characterization (§2.4 below) — is algebraic machinery that operationalizes it.
§2.3 Existence and uniqueness
Existence. The lasso objective is convex, continuous, and coercive — as , the squared loss is bounded below by zero and the L1 penalty grows linearly, so the objective grows without bound. Convex-and-coercive implies attainment of the minimum, so the solution set is non-empty for every . The solution set is also convex (intersection of all minima of a convex function) and closed (by continuity).
Uniqueness. When does contain a single point? Two sufficient conditions:
- and has full column rank. Then is positive definite, the squared loss is strictly convex in , the lasso objective is strictly convex, and the minimum is unique.
- has columns in “general position”. Tibshirani (2013) showed that this condition — no columns of lie in an affine subspace of dimension — is sufficient for lasso uniqueness regardless of whether or . With probability one over any continuous random design (Gaussian, bounded continuous, etc.), the columns are in general position. So for every continuous random , the lasso solution is unique with probability one, even at .
The conditions can fail with discrete or rank-deficient designs. Two pathologies:
- Duplicate columns. If for some , then and can be redistributed freely subject to being constant. The solution set is a 1-parameter family.
- One-hot encodings of categorical features. If for some subset of columns, the same pathology arises after centering.
But — and this is what saves the lasso in practice — the fitted values are always unique, even when is not. The squared loss is strictly convex in , so any two solutions satisfy . The prediction is uniquely determined; only the coefficient decomposition can be ambiguous.
For DGP-1 the design is continuous Gaussian, so the lasso solution is unique with probability one. We’ll assume uniqueness throughout the rest of the topic.
§2.4 KKT subgradient conditions
The lasso objective is convex but non-differentiable. The first-order optimality condition uses the subgradient of the L1 norm in place of the gradient. Recall: for a convex function , the subdifferential at is the set
For differentiable , — a singleton. For non-differentiable points, it’s a non-trivial set. The subdifferential of the absolute value is
The L1 norm has subdifferential .
The first-order optimality condition for the lasso — is in the subdifferential of the objective at — gives the KKT subgradient conditions:
Proposition 1 (Lasso KKT conditions).
is a lasso solution at if and only if there exists such that
Coordinate-by-coordinate, this splits into two cases:
- Active coordinates (): , so
The residual correlation with each active feature is exactly — the active features all sit on the boundary of the same “correlation level set.”
- Inactive coordinates (): , so
The residual correlation with each inactive feature is bounded by — strictly less, generically.
We’ll use the names for the -th column of , for the residual vector, and for the residual-feature correlation at coordinate . In this notation, KKT says: for active , for inactive .
Active set, equicorrelation set. Define the active set as and the equicorrelation set as . The KKT conditions imply — every active coordinate is at the equicorrelation boundary. Generically, (every coordinate at the boundary is also active). When — i.e., when an inactive coordinate happens to sit exactly at — the solution is non-unique on the equicorrelation set.
Two corollaries we’ll use later. First, the active set has size at most : if , the system has no full-rank solution unless the columns of are linearly dependent. So the lasso never selects more than features, regardless of . (This is one of the lasso’s most useful structural properties: it returns a model of size at most , which is interpretable.)
Second, the KKT conditions give the dual certificate for sparsity recovery (used in §6 for variable-selection consistency): if there exists a vector supported on with that satisfies KKT, then the lasso correctly identifies as the active set. The construction of this dual certificate, and the conditions on that make it possible, are the irrepresentable condition (§6.2).
We verify the KKT conditions numerically on the §1 lasso fit at : residual correlations at active coordinates equal to within ; residual correlations at inactive coordinates are strictly bounded by , with the bulk well inside the dead zone.

§3. Solving the lasso
The lasso has no closed-form solution for general , so we need iterative algorithms. This section develops the four solvers that matter in practice, in increasing order of sophistication: the soft-thresholding closed form for orthogonal designs (§3.1, the only case that admits a closed form, but conceptually load-bearing because every general-purpose solver reduces to it inside the inner loop); coordinate descent (§3.2, the glmnet workhorse, fastest in practice for moderate-sized problems and the default in scikit-learn); ISTA, the proximal-gradient method (§3.3, simple and slow, convergence rate, the natural first step toward FISTA); and FISTA with Nesterov momentum (§3.4, the same proximal-gradient framework with a momentum trick that improves the rate to , with full convergence proof). §3.5 gives practical solver-choice notes.
A common thread: every solver in this section is some application of the soft-thresholding operator , the proximal operator of the L1 norm. ISTA / FISTA / coordinate descent differ only in what they soft-threshold and how often. So §3.1’s three-line derivation is the algorithmic kernel of everything that follows.
§3.1 Soft-thresholding closed form for orthogonal designs
When — an orthogonal design, achievable in practice via QR decomposition of any full-rank — the lasso decouples across coordinates and admits a closed-form solution.
Substitute into the lasso objective:
Drop the constant and let . The objective separates by coordinate:
So the lasso reduces to independent univariate problems: minimize over , one for each coordinate.
Theorem 1 (Soft-thresholding closed form).
For and , the unique minimizer of is
Equivalently, the lasso solution on an orthogonal design is with .
Proof.
The objective is convex (sum of convex), continuous, and coercive, so a minimum exists and is unique (the quadratic part is strictly convex). The KKT condition: , equivalently .
Case 1: . Then , so , giving . This is consistent with if and only if .
Case 2: . Then , so , giving . Consistent with if and only if .
Case 3: . Then , so we need , i.e., .
The three cases partition and give a unique for each . Combining: .
∎The geometric content: for each coordinate, if the (rescaled) least-squares estimate is small in magnitude — bounded by — the lasso sets to exactly zero. Otherwise, the lasso shrinks toward zero by exactly in absolute value. The “dead zone” is the source of sparsity; the constant shrinkage outside the dead zone is what biases active coefficients toward zero (the bias problem the debiased lasso fixes in §10).
For non-orthogonal designs (the generic case), no closed form exists. But remains the algorithmic atom: it’s the proximal operator of the L1 norm,
applied componentwise. Coordinate descent (§3.2) and proximal gradient methods (§§3.3–3.4) repeatedly apply inside their iterations.
§3.2 Coordinate descent
Coordinate descent solves the lasso by cycling through coordinates and minimizing the objective over one coordinate at a time, keeping the others fixed. Each subproblem is univariate and admits a closed form via soft-thresholding.
Derivation. Fix all coordinates except . The lasso objective restricted to is
where is the partial residual with the -th feature’s contribution removed. Expand the squared loss:
This is — the same univariate problem from §3.1 up to a rescaling. The KKT condition gives
Coordinate descent algorithm.
- Initialize , .
- For each (cyclically):
- Form the partial residual: .
- Compute and .
- Update .
- Update the residual: , then .
- Repeat step 2 until falls below tolerance.
Why the residual update. Storing and updating it incrementally avoids re-computing from scratch at each coordinate update. Each update costs instead of , so a full cycle costs — the same as one ISTA / FISTA iteration.
Convergence. The lasso objective is the sum of a smooth strictly-convex (in ) quadratic and a separable convex term . Tseng (2001) showed that block coordinate descent converges to a global minimum for any objective of this form (smooth + separable convex), with no rate guarantee in general but linear convergence under additional assumptions. In practice on lasso problems with continuous designs, coordinate descent is one of the fastest methods — Friedman, Hastie & Tibshirani (2010) report 10–100× speedups over LARS and proximal-gradient methods at typical scales. The glmnet package and scikit-learn’s Lasso both use it as the default.
Warm starts along a path. Practical solvers compute the lasso path for a decreasing grid of values, using the previous solution as a warm start at the next . The path is piecewise linear in (Efron-Hastie-Johnstone-Tibshirani 2004), so a small step in requires few coordinate-descent passes to converge — typically 5–20.
§3.3 ISTA: the proximal gradient method
Coordinate descent works for the lasso because the L1 penalty is separable. For more general non-smooth penalties (group lasso, fused lasso, nuclear norm), we need a different framework. Proximal gradient methods generalize gradient descent to objectives of the form , where is smooth and is non-smooth but admits a tractable proximal operator. For the lasso, and , with .
The iterative soft-thresholding algorithm (ISTA) is the proximal-gradient iteration:
with a step size where is the Lipschitz constant of (largest eigenvalue of ). Each iteration costs one matrix-vector multiply and one — the same as a coordinate-descent cycle.
Theorem 2 (ISTA convergence rate).
Let be the Lipschitz constant of and let be a minimizer of . The ISTA iterates with step size satisfy
Proof.
The proof has two ingredients: a per-step descent lemma and a telescoping argument.
Descent lemma (Beck-Teboulle 2009, Lemma 2.3). For any , the proximal-gradient step satisfies
The proof uses -smoothness of (, the standard descent lemma) plus the variational characterization of the prox.
Telescope. Apply the descent lemma at iterate with :
Sum from to . The right side telescopes to . The left side, using monotonicity of along the iteration (also from the descent lemma applied with ), is bounded below by . Dividing by gives the rate.
∎The rate is “sublinear” — to halve the suboptimality requires doubling . ISTA is simple and stable but slow.
§3.4 FISTA: Nesterov momentum and the rate
Beck-Teboulle (2009) showed that adding Nesterov momentum to ISTA accelerates the convergence rate from to — a quadratic improvement in iteration count for the same accuracy. The algorithm:
FISTA. Set , . For :
- — momentum extrapolation.
- — proximal gradient step from , not .
- .
The momentum coefficient approaches as grows, giving the iteration a “running start” along the previous direction of motion.
Theorem 3 (FISTA convergence rate (Beck-Teboulle 2009, Theorem 4.4)).
With step size , the FISTA iterates satisfy
Proof.
Define and the Lyapunov function
The proof has three steps.
Step 1 (Lyapunov lemma). We show for all , i.e., the Lyapunov function is non-increasing along FISTA iterations. Apply the proximal-gradient inequality (Beck-Teboulle Lemma 2.3, the same lemma used for ISTA but evaluated at the momentum point ) at with two choices of :
Multiply the first inequality by and the second by — using the FISTA recursion — and add. After algebraic manipulation that uses the definition of in terms of and , the right side telescopes into , and the left side is . Rearranging gives .
Step 2 ( lower bound). By induction, for all . Base case . Inductive step: .
Step 3 (conclude). Iterating Step 1 from gives . Since implies , and is one ISTA step from , the bound follows from one application of the descent lemma (the same as in the ISTA proof). So for all . Drop the non-negative term:
Combine with from Step 2:
∎A factor-of- improvement over ISTA: to reduce by a factor of 100, ISTA needs 100× more iterations while FISTA needs only 10×. The constant is the same as the ISTA bound (modulo the factor of 4), so the asymptotic rate is the only source of difference — but it’s a substantial one.
FISTA is not a descent method. Unlike ISTA, is not monotonic along FISTA iterations — small “ripples” in are normal. A monotone variant (M-FISTA, Beck-Teboulle 2009 §5) accepts only if , otherwise reuses . This trade-off — slightly worse worst-case constant for monotonicity — is rarely worth it in practice.
Log-log convergence trace on a smaller-scale DGP-1 (n = 150, p = 200, s = 10, σ = 0.5, AR(1) ρ = 0.5) at λ = 0.05. F* is computed by a 5,000-iteration FISTA reference. Reading off the slopes: ISTA tracks k⁻¹ (Theorem 3.2), FISTA tracks k⁻² (Theorem 3.3), and coordinate descent matches FISTA early then asymptotically beats both once the active set stabilizes — the lasso restricted to a fixed active set is a strictly-convex quadratic, where CD converges linearly. Iterations to reach F − F* < 10⁻³: ISTA = 63, FISTA = 22, CD = 6.
§3.5 Practical solver-choice notes
When does each solver win? A field guide.
Coordinate descent (sklearn.linear_model.Lasso, glmnet). Default for everything in the lasso family (lasso, elastic net, group lasso). Fastest in practice for at moderate sparsity. Warm starts along a path are nearly free, which is why LassoCV is fast even with 100-fold path × 10-fold CV.
FISTA. The right default for lasso variants where the L1 prox is easy but coordinate-by-coordinate updates are not — group lasso with overlapping groups, fused lasso, generalized-lasso-with-non-axis-aligned penalty, total-variation penalties. Also the right default when the design matrix is structured (e.g., a fast Fourier or wavelet transform) and matrix-vector products can be computed in rather than — coordinate descent breaks the structured-multiplication advantage by accessing one column at a time.
ISTA. Pedagogically valuable, rarely the right algorithmic choice — FISTA dominates it at no extra implementation cost. Use ISTA only when the proof of correctness or the descent property is needed (some monotonicity-sensitive applications, e.g., in statistical guarantees that rely on objective decrease).
Specialized solvers we don’t cover. ADMM (Boyd et al. 2011) is the right tool for lasso variants with linear-equality-coupled penalties (e.g., the Dantzig selector). LARS (Efron-Hastie-Johnstone-Tibshirani 2004) computes the entire lasso path exactly in , which can beat coordinate descent at very small but loses badly at the high-dimensional scales we care about. Interior-point methods (CVXPY, cvxopt) work but are typically 100×+ slower than coordinate descent on lasso problems of any meaningful size.
For everything in the rest of this topic — the §1 lasso fits, the LassoCV in §7, the elastic-net comparison in §8, the debiased-lasso pipeline in §10 — we use scikit-learn’s coordinate descent. We hand-rolled FISTA above to demonstrate the rate and to keep the algorithmic content visible.
§4. Bias-variance for the lasso
The lasso’s central trade-off is between bias (from L1 shrinkage of active coefficients) and variance (controlled by the size of the data-adapted active set). As ranges from to — the smallest penalty at which the solution is identically zero — the prediction risk traces the canonical U-curve familiar from any bias-variance analysis. This section formalizes both halves of the trade-off, computes in closed form from the KKT conditions, and develops the lasso solution path as a piecewise-linear function of .
The U-curve is the practical bridge between §3 (we can compute the lasso) and §5 (the oracle inequality bounds the bottom of the U). The solution path is what LassoCV (§7) and LassoLarsIC (§7) operate on when they pick a .
§4.1 The bias contribution from L1 shrinkage
The lasso’s shrinkage isn’t soft and asymptotically vanishing the way a Bayesian Gaussian-prior posterior is — it’s a constant absolute shrinkage that biases every active coefficient toward zero by approximately .
The orthogonal case makes this explicit. From §3.1, with and , the lasso solution is . Under the model :
- For “large signal” coordinates with : with high probability and , so and . The bias is — constant magnitude, opposite sign to the true value, independent of how large is.
- For “noise” coordinates with : by the symmetry , . No bias, but a small variance contribution from the false positives where by chance.
For general (non-orthogonal) designs, the calculation is more involved but the qualitative picture survives. Conditioning on the lasso correctly identifying the active set , the active coefficients satisfy
where is the OLS estimator restricted to . The shrinkage correction scales linearly in ; its magnitude depends on the conditioning of but is generally of order .
This bias is the price of sparsity. Two later sections fix it for different reasons:
- The adaptive lasso (Zou 2006, §8.3) replaces the constant shrinkage with feature-specific weights where for some initial estimator. Coordinates with large get small and small shrinkage, so the active-coefficient bias decays to zero asymptotically.
- The debiased lasso (§10.2) explicitly subtracts off the shrinkage bias via a one-step Newton correction , producing -consistent normal estimates of individual coefficients suitable for hypothesis testing and confidence intervals.
For prediction the bias isn’t catastrophic — the U-curve in §4.3 shows that the bias-variance trade-off is favorable at well-chosen . For inference it’s the central problem of the topic, and §10 is where it gets resolved.
§4.2 Variance from sparsity adaptation
In contrast to the bias, the lasso’s variance is small — much smaller than the variance of OLS would be at the same , when OLS is even defined.
The cleanest way to see this: OLS variance scales with the number of features, has trace , which scales as for a well-conditioned design. As from below, the variance blows up; at , OLS is undefined and the min-norm interpolant has its own pathologies.
The lasso, by zeroing out coordinates with small , effectively reduces the model dimension from to the active-set size . Heuristically — and this is made precise by the degrees of freedom of the lasso result (Zou-Hastie-Tibshirani 2007): , the expected size of the active set. So the lasso’s prediction variance scales as , which for a well-chosen is on the order of — proportional to the true sparsity, not to .
This is the sparsity-adaptation property: the lasso pays a variance cost proportional to the model size it actually uses, regardless of how many candidate features were available to start with. It’s the central reason the lasso works in the regime where OLS doesn’t.
For DGP-1 with , , : the lasso variance is roughly , while OLS at has variance roughly — a 20× advantage, before counting the bias.
§4.3 The U-curve as varies
The bias-variance pieces combine into the canonical U-shaped prediction-risk curve as a function of . Define the prediction risk at test point :
with the expectation over training-set draws (test point fixed). Average over in a test set to get the integrated prediction risk .
The U-curve has two boundaries:
- At (OLS / min-norm OLS at ): bias is zero (or near-zero for min-norm) but variance dominates and is large or undefined.
- At (defined below): variance is zero — deterministically — but bias equals the full prediction signal , so bias² is large.
Between these endpoints the curve is U-shaped, with an optimal that minimizes IPE. The §5 oracle inequality bounds the value of IPE at this optimum from above by .
in closed form. From the KKT conditions of §2.4: is a lasso solution if and only if for all — i.e., the inactive condition holds at every coordinate. So
For , the lasso solution is identically zero. For just below , exactly one coordinate becomes active (the one achieving the maximum) — this is the start of the lasso path described next. On DGP-1 with seed 42, , and sits two orders of magnitude smaller — well into the path’s interesting region.
The interactive viz below shows empirical bias², variance, and total MSE on a held-out test set as a function of , computed by Monte Carlo over replicate draws of DGP-1. Bias² grows monotonically with (constant shrinkage hurts more when applied harder); variance decays monotonically with (heavier penalization shrinks the active set); their sum traces a U-curve with minimum near . The minimum of the empirical U-curve coincides — within MC noise — with the value of that LassoCV selects automatically (§7).
Empirical bias-variance decomposition on a smaller-scale DGP-1 (n = 200, p = 200, s = 10, σ = 0.5, AR(1) ρ = 0.5, B = 20 replicates). MSE = bias² + variance is the canonical U; bias² (teal, dashed) grows with λ as constant shrinkage hits active coords harder; variance (purple, dotted) decays with λ as the active-set size shrinks. The red marker sits at the empirical λ minimizer of MSE — close to the LassoCV-selected operating point covered in §7. Computed live in-browser via warm-started ISTA across the 25-point log-spaced λ-grid (~3-5 s precompute).

§4.4 The lasso solution path is piecewise linear
Define the lasso solution path as the function for . The path has two structural properties that make it both computationally tractable and visually informative.
Theorem 1 (Piecewise linearity of the lasso path (Efron-Hastie-Johnstone-Tibshirani 2004)).
The lasso solution path is a continuous piecewise-linear function of . There is a finite sequence of knots such that on each interval , the active set is constant and is linear in . The knots are exactly the values of at which the active set changes — a coordinate enters or leaves .
The proof is a direct calculation from the KKT conditions: between knots, the active set is fixed, the active KKT condition for is a linear system in with on the right-hand side, so the solution is linear in . The LARS algorithm (Efron et al. 2004) traces this piecewise-linear path knot-by-knot in total time — though for moderate-to-large , coordinate descent on a -grid (§3.2) is faster in practice.
Reading the path. Plotting vs for all shows which features the lasso selects in what order and at what penalty level. As decreases from :
- The first coordinate to enter is — the feature most correlated with the response.
- Subsequent coordinates enter at successively smaller values, in roughly the order of their importance.
- At the path reaches OLS (in the case) or the min-norm OLS interpolant (in ).
- A coordinate can also leave the active set as decreases (coefficient passes through zero) — uncommon in continuous designs but possible.
The viz below shows the lasso solution path on DGP-1: vs for all 500 coordinates, with the 10 true active coordinates plotted in black and the 490 inactive coordinates in light gray. The vertical line at marks the cross-validation-selected operating point. The reader sees that the true active features are consistently the first to enter the path as decreases, and that at the active set is a tight superset of the true — most of the gray noise coefficients are still at zero.
Lasso solution path on a smaller-scale DGP-1 (n = 200, p = 200, s = 10, σ = 0.5, AR(1) ρ = 0.5). The 10 true active coordinates (j < 10) plot in black; the 190 inactive coordinates in gray (only those with |β̂_j| > 0.005 anywhere on the path are drawn — most stay flat-zero and are omitted to keep the SVG light). Vertical marker at λ_CV ≈ 0.056 (the LassoUCurve minimizer above). The active features enter the path first as λ decreases from λ_max ≈ 1; at λ_CV the active set is a tight superset of the true S. Computed live via warm-started ISTA across 30 log-spaced λ values (~200 ms precompute).

§5. The lasso oracle inequality
This is the topic’s headline theoretical result: under a restricted-eigenvalue condition on the design and a deviation bound on the noise, the lasso achieves prediction risk of order — comparable to what an oracle that knew the true active set in advance could achieve, up to a logarithmic factor in . The bound is non-asymptotic (holds with high probability for any finite , ), dimension-free (the dependence on is only logarithmic), and rate-optimal for the sparse high-dimensional regression problem.
The proof has four steps and follows Bickel-Ritov-Tsybakov (2009) closely. Step 1 (the basic inequality) uses the lasso’s defining optimality to bound the prediction error in terms of the L1 estimation error and a noise term. Step 2 (the cone condition) shows that the error vector has most of its L1 mass concentrated on the true support . Step 3 (the restricted-eigenvalue condition) lets us convert L1 estimation error on into a lower bound on the prediction error. Step 4 (the deviation step) controls the noise term using a maximal sub-Gaussian inequality. Combining gives the rate.
The proof’s main work is in steps 1 and 2 — the basic inequality and the cone condition derive directly from the KKT conditions of §2.4 with no further ingredients. Step 3 is the geometric assumption on the design that we’re imposing; step 4 is the standard probabilistic deviation inequality. The whole argument is technical but elementary — no measure theory beyond the sub-Gaussian moment bound.
§5.1 Setup: prediction risk in the high-dim regime
We work in the standard high-dimensional linear regression model:
We assume:
- Sparsity. has support with , .
- Sub-Gaussian noise. has independent entries with and sub-Gaussian parameter : for all . Gaussian noise with variance is the canonical case; bounded also qualifies.
- Column-normalized design. Each column satisfies — a normalization convention that makes the bound clean. Equivalently, the empirical second moment . For DGP-1 the columns satisfy this in expectation; in practice rescaling the columns to exactly is standard before fitting.
The prediction risk at the lasso estimator is
the average squared in-sample prediction error against the true regression function. (This is the “fixed-design prediction error.” It differs from the integrated test-set error of §4.3 — they coincide when the test design has the same row distribution as the training design and is large.)
The benchmark is the oracle estimator that knew in advance:
The oracle is OLS restricted to . Its prediction risk is in expectation (standard OLS variance with degrees of freedom). The oracle inequality says the lasso achieves the same rate up to a factor, without knowing .
§5.2 The basic inequality
The starting point is the lasso’s defining optimality: achieves the minimum of the lasso objective, so in particular it does no worse than :
(We drop the “lasso” superscript for brevity; is always the lasso solution in this section.)
Substitute and let :
and . The terms cancel, giving
Rearrange and double both sides:
This is the basic inequality. Two things to control: the noise inner product , and the L1-norm difference .
The noise term, via Hölder’s inequality.
Define the noise event
On , . Step 4 below shows that with chosen as , the event holds with probability at least . For now assume we’re on .
The L1-norm difference, via the support split. Decompose where the subscripts indicate the indices restricted to and respectively. Since :
Apply the reverse triangle inequality :
Substitute into on the event :
Combining the and terms:
This is the basic inequality in its useful form. The L1 mass of outside the true support, plus the prediction error, is controlled by the L1 mass on the true support.
§5.3 The cone condition
The basic inequality has an immediate geometric consequence. The prediction-error term on the LHS is non-negative, so we can drop it:
This is the cone condition. The error vector lies in the convex cone
Interpretation. Most of the error vector’s L1 mass is on the true support . The factor of 3 is conventional; it depends on the constant 2 in the basic inequality, which in turn comes from doubling both sides of the lasso optimality. Different works in the literature use for various ; the bound just needs the cone constant to be finite.
The cone condition is the structural content of the basic inequality. Without any further assumption on or , we know the lasso error is concentrated on — but we don’t yet have a rate bound on the prediction error. The next step requires an additional assumption on the design.
§5.4 The restricted-eigenvalue condition
The pure basic inequality gives . The RHS bounds the prediction error in terms of the L1 norm of the active part of , which has only entries — so by Cauchy-Schwarz, . We get
To convert this into a rate bound, we need to bound from above by something involving — i.e., a lower bound on in terms of . That’s exactly the restricted-eigenvalue condition.
Definition 1 (Restricted-eigenvalue condition (Bickel-Ritov-Tsybakov 2009)).
The design satisfies the restricted-eigenvalue condition with constant if for every with ,
In words: on the cone , the empirical Gram matrix acts like a positive-definite matrix on the active block — its smallest “eigenvalue” restricted to is at least . On the full space this would be the smallest eigenvalue of , which is zero whenever . The restriction to the cone is what makes the condition feasible in the high-dim regime.
When does RE hold? A few sufficient conditions:
- Random Gaussian designs. If has iid rows with , then RE holds with high probability with provided (Raskutti-Wainwright-Yu 2010, Theorem 1).
- Sub-Gaussian designs. Same conclusion under sub-Gaussian rows (Rudelson-Zhou 2013).
- Restricted isometry property (RIP). RIP RE (Candès-Tao 2005; we cover this in §9).
The condition is essentially the weakest design assumption under which the lasso works — it’s equivalent to ” acts well on sparse vectors and small perturbations of them.” For DGP-1 with AR(1) Toeplitz , in the limit for , so RE holds with .
§5.5 The deviation step and the rate
We now combine the three ingredients — basic inequality, cone condition, RE — and add the probabilistic step that controls .
Combining basic inequality and RE. Start from :
where the second inequality is Cauchy-Schwarz on and the third is RE. Let . Then , so , and squaring:
The deviation step. It remains to choose so that holds with high probability.
Lemma 1 (Sub-Gaussian maximal inequality).
Let have independent entries, sub-Gaussian with parameter , and have columns with . For any ,
Proof.
For a single coordinate , the inner product is a linear combination of independent sub-Gaussian random variables, hence itself sub-Gaussian with parameter
By the standard sub-Gaussian tail bound, , and the same bound for the negative tail. Union bound over the coordinates and the two tails:
Set the RHS equal to and solve for : .
∎Choose . Set — twice the deviation threshold from Lemma 1. Then on the event , which holds with probability at least . Substituting into :
Cleaning up the constants:
Theorem 1 (Lasso oracle inequality (Bickel-Ritov-Tsybakov 2009)).
Assume is -sparse, the noise has independent sub-Gaussian entries with parameter , the columns of satisfy , and the design satisfies with constant . Choose for some . Then with probability at least ,
The order of magnitude. Setting (high-confidence statement, probability), , so the bound is
This is the fundamental rate for sparse high-dimensional regression. Three things to note:
- The factor is the price of not knowing . The oracle estimator — OLS restricted to — achieves in expectation. The lasso achieves — the same rate up to a logarithmic factor. The is the price of doing model selection from candidates without prior knowledge.
- The rate is minimax-optimal. Donoho-Johnstone (1994) and Raskutti-Wainwright-Yu (2011) showed that no estimator can beat in the worst case over the class of -sparse signals. So the lasso achieves the optimal rate up to a constant — the lasso pays for not knowing , but it doesn’t pay extra for being computationally tractable.
- The dependence is real. When the design is poorly conditioned (highly correlated features), blows up and the bound degrades. This is the formal counterpart of the practical observation that the lasso works less well with strongly collinear features — §8 covers the elastic net as the standard remedy.
Corollary: L1 estimation rate. A similar argument starting from and using RE gives
Sketch: from + Cauchy-Schwarz + RE, , then from the cone condition. This estimation rate appears as a lemma in the §10.4 debiased-lasso asymptotic-normality argument.
The viz below shows the empirical prediction risk on a held-out test set vs sample size on DGP-1, alongside the theoretical BRT bound (constant 72) and a calibrated bound (constant fit empirically). The empirical curve sits one to two orders of magnitude below the BRT bound — the constant 72 is mathematically clean (each proof step contributes a factor of 2 or 3) but practically loose. The slope match on log-log axes (both lines parallel) is the substantive confirmation of the oracle-inequality rate.
Lasso prediction risk on smaller-scale DGP-1 (p = 200, s = 10, σ = 0.5, AR(1) ρ = 0.5, λ = 2σ√(2 log(p)/n) per Theorem 1) as n varies from 50 to 800. Empirical (teal dots) sits one to two orders of magnitude below the BRT bound (amber, c = 72); the calibrated bound (purple, constant fit to the n = 800 point) sits right on top of the empirical curve. All three lines have the same -1 slope on log-log axes — the substantive confirmation of the σ²s log(p)/n rate. The constant 72 is mathematically clean (each proof step contributes a factor of 2 or 3) but practically loose by 10-100×. Computed live in-browser via single-rep ISTA at each n (~500 ms total).

§6. Variable-selection consistency
The §5 oracle inequality bounds the lasso’s prediction risk: . That bound says the lasso predicts well — comparable to the oracle that knew in advance. It does not say the lasso correctly recovers the support itself.
These are different statements with different sufficient conditions, and confusing them is the most common conceptual error in lasso applications. Two highly correlated features can both be predictive of the response; the lasso might select either one, or alternate between them across resampled training sets, while keeping the prediction error small. The prediction-risk bound is robust to this kind of selection instability. The support-recovery question — does ? — is sensitive to it.
This section formalizes sign-consistency (the strongest form of support recovery), introduces the irrepresentable condition (Zhao-Yu 2006) that’s both sufficient and essentially necessary for it, states the sample-size scaling for support recovery, and contrasts the prediction-risk bound (RE-based) against the support-recovery bound (IC-based) so the difference is visible.
§6.1 Sign-consistency: what it means and why prediction consistency doesn’t imply it
For a vector , define entry-wise: if , if , if . Three increasingly strong support-recovery notions:
- Support recovery (set-equality): .
- Sign consistency: . This implies and additionally that the signs of the active coefficients are correct.
- Sign-consistent estimation: as .
The standard target in the lasso literature is sign consistency — slightly stronger than support recovery, but only by the negligible probability that an active coordinate is estimated with the wrong sign (which has probability rapidly under any reasonable signal-strength assumption).
Why prediction consistency doesn’t imply sign consistency. Consider the simplest counterexample. Take with and identical: . The true coefficient is — the first feature is active, the second is not. The lasso objective is
which depends on only through their sum and through . The minimizer is non-unique: any with equal to the optimal sum and minimal — i.e., any with and the right sum — solves it. Among these, , , and are all valid solutions. Prediction is identical across them; support is dramatically different.
This is an extreme case (perfectly collinear features), but the same phenomenon shows up in milder form whenever two features are highly correlated and both predictive — the lasso has no preference between them, and may flip which one it selects under tiny perturbations of the data.
§6.2 The irrepresentable condition (Zhao-Yu 2006)
The right structural condition for sign consistency is the irrepresentable condition (IC), introduced independently by Zhao-Yu (2006) and Meinshausen-Bühlmann (2006). Given the active set and the sign vector :
Definition 1 (Irrepresentable condition).
The design satisfies the (weak) irrepresentable condition for if
The strong irrepresentable condition with parameter strengthens this to .
Geometric interpretation. The vector is the OLS coefficient vector that would arise from regressing on — call it the dual representation of the sign pattern. Multiplying by gives the projection . Then is the inner product of each inactive feature () with that projection.
The condition asks: how strongly is each inactive feature correlated, after accounting for the active features, with the sign pattern of the active coefficients? IC says the correlation is bounded by 1; strong IC says strictly less than 1. The intuition: if some inactive feature () can be “represented” by the active features — written as a linear combination — with , the lasso will select in preference to (or in addition to) the true active features. Strong IC rules this out.
An equivalent formulation in terms of regression coefficients. Let be the OLS coefficient vector for regressing the inactive feature () on the active features . Then IC reads
Each describes how the inactive feature is predicted by the active features. The IC says the dot product of this prediction recipe with the sign pattern of active coefficients is bounded — i.e., no inactive feature is “too aligned” with the active features in a sign-coherent way.
Population versus empirical. For a random design with iid rows from , the population IC is
and the empirical IC concentrates around it as grows. The viz below plots the population IC as a function of correlation strength on DGP-1-style AR(1) Toeplitz designs.
Population IC quantity for AR(1) Toeplitz designs Σⱼₖ = ρ^|j−k| with contiguous active set S = {0, …, 9} and sign(β*_S) = (1, …, 1). Below the IC = 1 threshold, the lasso is sign-consistent (Wainwright 2009 Theorem 1); above the threshold, the lasso provably fails sign-consistency (Wainwright 2009 Theorem 3) regardless of how λ is chosen — elastic net (§8.2) or adaptive lasso (§8.3) become necessary. At ρ = 0.5 (DGP-1 default) the IC sits comfortably below 1 and the §1 viz showed clean recovery. No crossover in this ρ range. Computed live in-browser via Cholesky on the s × s = 10 × 10 active-set Gram block.

§6.3 The sample-size scaling for support recovery
Theorem 1 (Lasso sign-consistency (Zhao-Yu 2006; Wainwright 2009)).
Suppose:
(i) The design satisfies the strong irrepresentable condition with parameter .
(ii) The active-set Gram matrix is well-conditioned: .
(iii) The columns are normalized: .
(iv) The minimum signal is large enough: for some constant .
(v) The noise is sub-Gaussian with parameter .
Choose . Then with probability at least ,
In particular, taking for some constant , the conclusion holds with probability as long as .
Proof sketch (primal-dual witness). Wainwright’s (2009) proof uses a five-step primal-dual witness construction:
-
Restricted lasso. Solve the lasso only on the active features: . Set and define .
-
Sign verification. Verify that — this is where the minimum-signal condition (iv) is used. With high probability, the restricted lasso has the right signs because the noise is small compared to .
-
Construct the dual. Set . The active KKT condition then determines what would have to be for to be the full lasso solution:
-
Verify the inactive KKT condition. For to be the actual lasso solution, we need (strict). The leading term is exactly the irrepresentable quantity from Definition 1; strong IC bounds it by . The noise term is via sub-Gaussian deviation, which is for large enough . So with high probability, .
-
Conclude by KKT uniqueness. Steps 1–4 produce a pair satisfying the lasso KKT conditions with strictly bounded . Under the design assumptions, the lasso solution is unique (recall §2.3), so . Since and , sign consistency holds.
The full proof with explicit constants is in Wainwright (2009, §III). The key probabilistic ingredient is the same sub-Gaussian deviation we used in §5.5 — extended to control the noise term in step 4.
Necessity of IC. Wainwright (2009, Theorem 3) also proved the converse: if the irrepresentable condition fails (say for some ), then as , regardless of how is chosen. The lasso provably fails to recover the support when IC is violated. So IC isn’t just a proof artifact — it’s the correct characterization of when the lasso can do support recovery.
§6.4 Contrasting prediction-risk and support-recovery: same estimator, different theorems
The two main theorems of §§5–6 differ on every axis. A comparison:
| Prediction-risk bound (§5) | Support-recovery bound (§6) | |
|---|---|---|
| What’s bounded | ||
| Sufficient condition on | Restricted-eigenvalue (§5.4) | Irrepresentable (§6.2) |
| Necessary? | RE essentially necessary for any sparse-regression estimator at the optimal rate | Strong IC necessary for lasso sign-consistency (Wainwright 2009) |
| Sample-size scaling | ||
| Minimum-signal needed? | No — works for any with | Yes — required |
| What fixes failure | Larger gives better RE | IC violated lasso fundamentally can’t recover support; need adaptive lasso (§8.3) or post-selection refit |
The conditions are not nested. RE doesn’t imply IC, and IC doesn’t imply RE. They measure different geometric properties of the design:
- RE is a lower bound on restricted to a cone. It’s about the design being “well-conditioned on sparse and near-sparse vectors” — a global property that doesn’t depend on which is the active set.
- IC is a constraint relating the inactive-to-active block of to the sign pattern . It depends on and specifically.
A design can satisfy RE but violate IC (random Gaussian designs with strong correlation between active and inactive features), in which case the lasso predicts well but selects the wrong support. The reverse can also happen, though it’s less common in practice.
Practical implications. The lasso is a much better prediction tool than a model-selection tool. Two rules of thumb:
-
For prediction: trust the lasso. CV-selected , refit at or , and use the lasso predictions. The §5 oracle inequality gives near-optimal prediction risk under mild conditions.
-
For variable selection: be skeptical of the lasso’s chosen support. Two specific patterns to watch for: (i) two highly correlated features where only one shows up in the lasso fit (the lasso may have arbitrarily picked one), and (ii) the lasso fit changing dramatically across resampled training sets (instability IC likely violated). Use stability selection (Meinshausen-Bühlmann 2010) to assess; consider the adaptive lasso (§8.3) for a sign-consistent variant under weaker conditions.
The deeper bridge to §§7–10: practical -selection (§7) trades off these two objectives differently — LassoCV optimizes prediction (smaller , more features); LassoLarsIC with BIC penalizes model size more heavily (larger , fewer features, closer to support recovery). The debiased lasso (§10) sidesteps the support-recovery question entirely by producing valid CIs for individual coefficients without requiring sign consistency.
§7. Cross-validation for
The §5 oracle inequality recommends for prediction-optimal performance — a rate, not a constant. The constant matters in practice (a factor of 2 in can change the active-set size by a factor of 2 or more), and the noise scale is rarely known. Practical -selection uses data-driven criteria: cross-validation (the default in scikit-learn and glmnet), the one-standard-error rule (a parsimony-favoring variant), and information criteria like AIC/BIC computed along the lasso path (LassoLarsIC). This section covers all three.
The CV / 1-SE / BIC distinction maps directly onto the §6 discussion: CV optimizes prediction error and tends to select more features than necessary; BIC penalizes model size more aggressively and is sometimes selection-consistent; the 1-SE rule is a Hastie-Tibshirani-Friedman compromise that gives a smaller model than CV-min at minimal prediction-performance cost. None is “right” — the right choice depends on whether you care about prediction or model interpretability.
This is a named-section of the topic per the formalML “no separate cross-validation topic” convention. The same structural pattern is used in Kernel Regression §5 for LOO-CV / GCV bandwidth selection.
§7.1 K-fold cross-validation with LassoCV
-fold CV estimates the prediction risk at each in a candidate grid by holdout. The procedure:
- Partition the training data into folds of approximately equal size.
- For each fold and each candidate :
- Fit the lasso on the data minus fold , obtaining .
- Compute the held-out MSE: .
- Average over folds: .
- Select .
Standard choices: for general use, if computation is constrained, leave-one-out () only when is small (otherwise computationally wasteful and statistically unstable). The candidate -grid is typically log-spaced from (largest, all coefficients zero) down to or so, with 100 grid points — LassoCV(n_alphas=100)’s default.
Why CV works. is an estimator of the test prediction error , with bias of order (because each fold-fit uses samples instead of ). At the fold sizes used in practice (), the bias is negligible compared to the variance of the CV estimate.
Computational efficiency. Naively, -fold CV requires lasso fits. The glmnet and scikit-learn implementations use warm starts along the path (recall §3.2) — fitting the lasso at the entire -grid for one fold is barely more expensive than fitting at a single , so the practical cost is more like path computations. For DGP-1 with , , : about 1–3 seconds total, dominated by the matrix-vector multiplies inside coordinate descent.
§7.2 The one-standard-error rule: vs
The CV estimate is itself a random quantity — it has variance over the choice of fold partition and over the training data. A useful uncertainty quantification is the standard error across folds:
The one-standard-error rule (Breiman et al. 1984; popularized by Hastie-Tibshirani-Friedman, Elements of Statistical Learning, §7.10) selects the most parsimonious model whose CV error is within one standard error of the minimum:
Since is roughly U-shaped in , — the 1-SE-selected model is more regularized, hence sparser.
The motivation. The CV minimizer is the unbiased “MSE-optimal” choice but tends to be unstable across resampled training data — a small perturbation in the training set can shift by a factor of 2 in either direction. The 1-SE rule trades this instability for a small, controlled increase in prediction error: the resulting model has CV-MSE within one standard error of optimal (i.e., not statistically distinguishable from ‘s prediction performance) but is more parsimonious and reproducible.
In the lasso context, typically gives an active set 10–30% smaller than , with test prediction error 5–15% larger. For interpretability-driven applications (variable selection, communication of results, downstream modeling), the 1-SE rule is the standard recommendation.
A practical caveat. The 1-SE rule is a heuristic, not a theorem. Its bias-variance trade-off is empirically reasonable but doesn’t have a sharp theoretical justification — it doesn’t, for instance, give support consistency under weaker conditions than CV-min. If you need provable support recovery, use BIC (§7.3) or stability selection (mentioned in §6.4). If you need provable prediction risk, the §5 oracle inequality is the right reference and CV-min is the right selector.
10-fold LassoCV on smaller-scale DGP-1 (n = 200, p = 200, s = 10, σ = 0.5, AR(1) ρ = 0.5). The teal curve is mean CV-MSE across folds; shaded band is ±1 SE. Five selector markers (vertical dashed lines) ordered from smallest to largest λ: CV-min (largest active set, smallest test MSE), CV-1SE (parsimony-favoring within 1 SE of CV-min), AIC and BIC (information-criterion picks on the lasso path; BIC selects sparser models than AIC), and theory-guided RIC = 2σ√(2 log p / n) from Theorem 1 (largest, conservative). Computed live in-browser via 10-fold warm-started ISTA across 25 log-spaced λ values (~1-2 s).

§7.3 BIC selection with LassoLarsIC
Information criteria offer a different selection philosophy: rather than estimating prediction error directly via holdout, they balance model fit against model complexity through an explicit complexity penalty.
The criteria. For a candidate with active-set size and residual sum of squares :
Both penalize larger models; BIC penalizes more aggressively as soon as , so BIC selects smaller models than AIC.
The use of as the lasso’s effective degrees of freedom rests on Zou-Hastie-Tibshirani (2007), who showed that exactly — the size of the active set is an unbiased estimator of the lasso’s degrees of freedom. This is a non-trivial result; for a generic non-linear estimator, dof is not the count of nonzero parameters. The lasso’s piecewise-linear path makes the result exact.
LassoLarsIC. The scikit-learn implementation computes the entire lasso path via LARS (Least Angle Regression — Efron-Hastie-Johnstone-Tibshirani 2004), which exploits piecewise linearity to enumerate every knot in total time. The IC value is computed at each knot, and the minimizing the chosen criterion is returned. The path-based approach is exact (no -grid discretization error) but only practical for moderate — at , coordinate descent on a -grid is much faster.
Selection consistency. BIC for the lasso is selection-consistent under additional conditions: as if the design satisfies a slightly stronger condition than IC and the minimum signal is bounded below (Wang-Li-Tsai 2007). AIC and CV are not selection-consistent in general — they tend to over-select features (include all of plus some noise features) even asymptotically. For variable-selection applications, this is BIC’s main virtue.
Caveats. BIC’s selection consistency is asymptotic; at finite samples, BIC can over- or under-select depending on the signal strength. AIC is roughly equivalent to leave-one-out CV in expectation (Stone 1977) and tends to choose larger models than -fold CV with .
§7.4 Comparison on the §1 toy DGP
The four selectors — LassoCV , LassoCV , LassoLarsIC BIC, LassoLarsIC AIC — make different trade-offs and select different values on the same data. On DGP-1 (), the typical pattern (see Figure 7.2):
| Selector | Selected | Active set size | Test MSE |
|---|---|---|---|
| LassoCV () | smallest | largest (~12–18, includes some false positives) | smallest |
| LassoCV () | medium | medium (~10–13, close to true ) | small (5–15% above ) |
| LassoLarsIC (AIC) | smallish | medium-to-large | small (close to ) |
| LassoLarsIC (BIC) | largest | smallest (~8–11, may miss weak signal coords) | medium (10–25% above ) |
Recommendation.
- If prediction is the goal: use
LassoCVwith . The §5 oracle inequality says this achieves the optimal rate; in practice it gives the smallest test MSE on most problems. - If prediction is the goal but you want a smaller, more interpretable model: use the 1-SE rule. Trades a small amount of prediction performance for a substantially smaller active set and more reproducible variable selection.
- If selection consistency is the goal: use BIC via
LassoLarsIC(criterion='bic'). The selected model is asymptotically the true support under stronger conditions; finite-sample behavior depends on signal strength. - For everything else: start with
LassoCV. It’s the default in almost every lasso application; the alternatives are refinements for specific use cases.
The §10 debiased lasso uses LassoCV as its initial estimator, then corrects the resulting bias to produce valid CIs. The choice of for the initial fit isn’t critical for the debiased lasso’s coverage — the one-step correction substantially compensates for the lasso’s selection idiosyncrasies.

§8. Ridge, elastic net, and adaptive lasso
The lasso has three practical limitations: it can be unstable when features are highly correlated (the §6.1 collinearity counterexample — flipping between equivalent supports); it biases active coefficients toward zero by a constant (the §4.1 shrinkage bias); and it requires the irrepresentable condition for support recovery (the §6.2 IC, often violated in real data). Each of these motivates a variant.
Ridge (already introduced in §1.3) keeps the L2 penalty, gives a unique dense solution under any design, and is robust to correlated features — but doesn’t select. Elastic net (Zou-Hastie 2005) combines L1 + L2 penalties, getting the lasso’s sparsity with ridge’s stability under correlated features. Adaptive lasso (Zou 2006) uses data-driven feature-specific weights to remove the constant shrinkage bias and achieve the oracle property under weaker conditions than IC.
This section explains when each variant wins on the side. The decision tree:
- Truth is dense (all coefficients moderate, no sparsity): ridge.
- Truth is sparse, features are well-separated: lasso.
- Truth is sparse but features come in correlated groups: elastic net.
- Truth is sparse, you want unbiased active coefficients and support consistency: adaptive lasso.
§8.1 Ridge: continuous shrinkage, no selection
Recall the ridge objective from §1.3:
with closed form . Three relevant properties at :
Always defined and unique. The matrix is positive definite for any regardless of vs . Ridge has no failure mode the way OLS does.
Continuous shrinkage, dense solutions. In the SVD basis , ridge shrinks each coefficient by a factor where is the -th singular value. Small singular values (the noisy directions) get heavy shrinkage; large singular values (the signal directions) get light shrinkage. But no coefficient is zeroed out — the solution is generically dense.
Bayesian interpretation. Ridge is the posterior mean of under a Gaussian prior and Gaussian likelihood . The penalty strength is inversely related to the prior variance.
When ridge wins. Two scenarios:
- Truly dense . When every feature carries some signal — no underlying sparsity — the lasso’s sparsity assumption is wrong, and the lasso under-fits (zeros out features that should be active). Ridge has no such bias.
- Heavy multicollinearity with no sparsity prior. When features are nearly linearly dependent and there’s no reason to prefer one over another, ridge distributes the signal smoothly across them. Lasso would arbitrarily select one and zero the others — a worse use of information.
When ridge loses. When is genuinely sparse, ridge’s refusal to zero out inactive coordinates leaves residual noise in the fitted values. Each inactive coordinate contributes to the prediction variance — small but non-zero. Lasso eliminates this contribution by zeroing the inactive coordinates entirely. On DGP-1 (, , so 490 inactive coordinates), the cumulative variance contribution is substantial, and lasso prediction MSE is typically 2–5× better than ridge.
For most high-dimensional ML problems the truth is more sparse than dense, so the lasso wins more often than ridge. The standard practice is to compare both on cross-validated test MSE and pick the winner.
§8.2 The elastic net for groups of correlated features
The elastic net (Zou-Hastie 2005) combines L1 and L2 penalties:
with mixing parameter controlling the L1/L2 balance. recovers pure lasso, recovers pure ridge (up to scaling). Standard practice: or tuned via cross-validation.
Two structural advantages over pure lasso:
- Strict convexity for . The L2 term makes the objective strictly convex in , so the solution is unique even with duplicate or perfectly collinear columns. The §6.1 collinear-features pathology disappears.
- The grouping effect. For two highly correlated features and (correlation close to 1), the elastic-net coefficient difference is bounded:
Proposition 1 (Grouping inequality (Zou-Hastie 2005, Theorem 1)).
For any two features with empirical correlation ,
As , the RHS — perfectly correlated features get equal coefficients. The lasso has no such property; it would pick one feature and zero the other. So in applications where the truth has correlated groups of active features (gene-expression clusters, related text features), elastic net selects all members of the group; lasso picks one member.
Reduction to a standard lasso. Zou-Hastie showed that the elastic net can be solved by augmenting the design matrix and running a standard lasso solver. Define
Then is the lasso solution on at penalty . So all the lasso algorithms (coordinate descent, FISTA) work for the elastic net by augmentation. scikit-learn’s ElasticNet and ElasticNetCV use a direct coordinate-descent implementation that exploits the structure without explicit augmentation, but the principle is the same.
When elastic net wins. Highly correlated features, especially correlated groups of features that should be selected together. Genomics is the canonical application: SNPs in linkage disequilibrium come in correlated blocks, and a gene-level signal manifests as coordinated effects across an entire block. Lasso would arbitrarily pick one SNP from each block; elastic net selects all the SNPs from active blocks.
When elastic net loses. When features are well-separated (low correlation), elastic net offers no advantage over lasso. The L2 term adds a small bias relative to lasso without reducing variance much. On the DGP-1 setting (AR(1) Toeplitz , moderate correlation), elastic net and lasso typically perform similarly; on a stronger-correlation DGP (), elastic net wins clearly.
§8.3 The adaptive lasso and the oracle property
The lasso biases every active coefficient by (§4.1). This constant shrinkage is independent of , so even strong-signal coordinates get shrunk by a fixed amount — a real problem for parameter recovery and inference.
The adaptive lasso (Zou 2006) replaces the uniform L1 penalty with feature-specific weights:
with weights for some initial estimator and a tuning parameter (typically ). Coordinates with large initial estimates get small weights (light shrinkage); coordinates with small or zero initial estimates get large weights (heavy shrinkage, effectively forced to zero).
Reduction to standard lasso. Rescale the features: and . Then and , so the weighted lasso reduces to a standard lasso on rescaled features. Solve with any lasso solver, then unscale: .
Choice of . Two standard choices:
- OLS (when ): .
- Ridge or LassoCV (when ): OLS isn’t defined, so use a regularized initial. LassoCV is the standard high-dimensional choice (cf. Bühlmann-van de Geer 2011, §2.8).
Theorem 1 (Oracle property of the adaptive lasso (Zou 2006)).
Assume the initial estimator is -consistent for , the minimum signal is bounded below by an appropriate constant, the noise is sub-Gaussian, and satisfies and . Then the adaptive lasso satisfies the oracle property:
(i) Selection consistency: .
(ii) Asymptotic normality: , the same asymptotic distribution as the oracle OLS estimator restricted to .
The oracle property is stronger than sign-consistency: in addition to recovering the support, the adaptive-lasso estimates on have the correct asymptotic standard errors — same as if you had known in advance and run OLS on it. The constant shrinkage bias disappears asymptotically because the weights are bounded for active coordinates (where the initial estimator is near ) but diverge for inactive coordinates.
The conditions are weaker than IC. The adaptive lasso achieves selection consistency under any design that has a -consistent initial estimator — much weaker than the strong irrepresentable condition required by the lasso. In particular, designs that fail IC (correlated active and inactive features) can still admit adaptive-lasso selection consistency.
Trade-off. The adaptive lasso requires a good initial estimator. In the high-dimensional regime where LassoCV is the standard initial, the adaptive lasso’s behavior depends on the quality of the lasso’s variable selection — a circular dependence that limits the asymptotic argument’s practical reach. Empirically, adaptive lasso usually beats vanilla lasso on support recovery and produces less-biased active coefficients, but the improvement isn’t dramatic on well-behaved problems.
§8.4 Side-by-side comparison on the §1 DGP
The four methods — ridge, lasso, elastic net, adaptive lasso — applied to DGP-1 at CV-selected penalties (Figure 8.1). The key visual contrasts:
- Ridge’s path is dense everywhere. Every coefficient is non-zero at every , shrinking smoothly. The 10 true active coordinates emerge as the largest-magnitude coefficients, but distinguishing them from the 490 inactive coordinates requires a thresholding step.
- Lasso’s path is sparse. Most coefficients are exactly zero at moderate . The true active coordinates appear as the first to leave zero as decreases. Active coefficients are visibly shrunk relative to the truth ( on ).
- Elastic net’s path looks like the lasso with smoother corners. Sparsity is preserved (most coefficients are zero at moderate ), but the active coefficients are slightly less shrunk than the lasso’s at the same effective regularization. The grouping effect would be more visible on a strongly-correlated DGP.
Figure 8.2 shows the adaptive lasso vs vanilla lasso on the active-coordinate estimates: the vanilla lasso underestimates by approximately (the constant shrinkage bias from §4.1); the adaptive lasso gets much closer to the true value for active .
Recommendation. Default to LassoCV. If features come in correlated groups, try ElasticNetCV. If you need unbiased coefficient estimates or weaker selection conditions, run the adaptive lasso as a post-processing step on top of LassoCV. The §10 debiased lasso provides a different fix for the bias problem — it doesn’t reduce the lasso’s bias but corrects for it explicitly when forming CIs.
Regularization paths β̂_j(t) on DGP-1 (n = 150, p = 200, s = 10, σ = 0.5, AR(1) ρ = 0.5). True active coordinates (j < 10) drawn in distinct colors; 190 inactive coordinates in light gray. Dashed reference at β* = 1. At the median penalty t ≈ 2.47e-1, the lasso fit has 10/10 active and 0/190 noise coordinates nonzero. Ridge keeps every coefficient nonzero at every α; lasso and elastic net both reach exact zeros at moderate penalty — the active coords are the first to leave zero as the penalty shrinks. Switch tabs to compare path geometries directly.

§9. Geometry of the high-dimensional regime
§§5–6 introduced two structural conditions on the design matrix — the restricted-eigenvalue condition (RE) for prediction-risk bounds and the irrepresentable condition (IC) for support recovery — and stated when they hold (random Gaussian, sub-Gaussian, RIP-bounded designs) without unpacking the geometry. This section deepens the picture: it introduces the restricted isometry property (RIP) from compressed sensing, traces the implication chain , gives the standard concentration arguments for sub-Gaussian random designs, and sketches when each condition fails in practice.
The section is text-heavy and relatively short — there are no new theorems beyond §§5–6, just structural unpacking. The payoff is a cleaner picture of what makes a “good” design for the lasso and what doesn’t, useful for diagnosing real-data failures.
§9.1 The restricted isometry property (RIP)
The restricted isometry property was introduced by Candès-Tao (2005) in the compressed-sensing literature, predating Bickel-Ritov-Tsybakov’s RE by a few years. It’s a uniform version of RE: instead of asking that the design preserve geometry on a particular cone , it asks that the design act approximately like an isometry on all -sparse vectors.
Definition 1 (Restricted isometry property (Candès-Tao 2005)).
The matrix satisfies the restricted isometry property of order with constant if for every vector with ,
The smallest such is the restricted isometry constant.
In words: (with the scaling) acts almost like an isometry on -sparse vectors — the squared norm approximates the squared norm to within a multiplicative factor of .
Why uniform sparsity matters. The RE condition (§5.4) is keyed to a specific support and sign pattern — it gives a lower bound on for in the cone . Different give different cones. RIP, by contrast, is a single condition that holds simultaneously for every choice of with — uniformly across the combinatorial possibilities. This makes RIP much stronger than RE for any single , but also much harder to verify.
Compressed-sensing origin. The compressed-sensing problem asks: given a known measurement matrix (with ) and observed measurements of an unknown sparse signal , recover exactly. The solution is L1 minimization:
This is the lasso in the limit with the constraint replaced by exact equality. Candès-Tao (2005) showed that if , the L1 minimizer recovers exactly. The lasso’s noisy-version recovery results (§§5–6) inherit the geometric content of RIP, weakened to the more flexible RE.
When does RIP hold? For random Gaussian designs with iid entries (so ): RIP of order with constant holds with high probability provided
Same scaling for sub-Gaussian random designs (Baraniuk-Davenport-DeVore-Wakin 2008). For deterministic designs, RIP is generally hard to verify — checking requires examining all sparse subsets, which is computationally intractable.
§9.2 RIP RE: the implication chain
If a design satisfies RIP with a small constant, it automatically satisfies RE. The implication is straightforward but worth tracing.
Proposition 1 (RIP implies RE).
If satisfies RIP of order with constant , then holds with constant .
Proof sketch. Pick any with . We need .
Decompose by sorting its entries by magnitude into blocks of size : let be the top- coordinates of in absolute value, the next , and so on. Let . Then with for , so each is -sparse and we can apply RIP to it.
The cone condition controls the L1-mass of outside , which (by sorting and the standard “top- approximation” argument) controls the L2-mass of the tail blocks .
Then by the triangle inequality applied to , and using RIP on each ,
Squaring and simplifying gives RE with . The full proof has more careful constants; van de Geer-Bühlmann (2009) and Wainwright (2019, §11.2) give the polished version.
The reverse implication does not hold. RE is strictly weaker than RIP. Many designs satisfy RE without satisfying RIP — most importantly, random Gaussian designs with non-identity covariance, where the columns are correlated and the uniform isometry property fails. RE for these designs comes from Raskutti-Wainwright-Yu (2010), who avoid going through RIP entirely.
So in practice: if your design is “compressed-sensing-style” (random Gaussian with iid entries, designed for sparse recovery), RIP is the right framework. If your design is “statistics-style” (random with population covariance, real-world features), RE is the right framework. The lasso oracle inequality holds under either, but the proofs and constants differ.
§9.3 Sub-Gaussian designs and concentration
The §5.5 deviation step controlled via sub-Gaussian concentration on the noise . For random designs — when itself has random entries — a parallel concentration result controls how the empirical Gram matrix approximates the population covariance .
Lemma 1 (Sub-Gaussian design concentration (Vershynin 2018, Theorem 4.6.1)).
Let have iid sub-Gaussian rows with mean zero and population covariance . With probability at least ,
where the constants depend on the sub-Gaussian parameter.
Implications. For , the empirical Gram matrix concentrates tightly around , and any spectral property of (eigenvalues, condition number, RE constant) transfers to with high probability. For , the concentration is loose (), and individual eigenvalues of can drift substantially from those of — the empirical Gram is rank-deficient when , so the smallest eigenvalue is exactly zero regardless of .
For the lasso, the relevant concentration is the restricted version: rather than controlling the full operator norm, we need to inherit from .
Theorem 1 (RE for sub-Gaussian designs (Raskutti-Wainwright-Yu 2010, simplified)).
Let have iid sub-Gaussian rows with population covariance satisfying . If for a sufficiently large constant depending on and the sub-Gaussian parameter, then with probability , the design satisfies with constant .
So the population condition — the population covariance is positive definite — combined with the sample-size scaling gives the sample-level RE condition the lasso needs. This is the standard “high-dimensional probability” path from a population-level assumption to a sample-level condition. The proof uses a covering argument on the cone , plus a uniform deviation bound on for in the cone.
For DGP-1 with , as , so RE holds with (the constant is loose; the empirical RE is much better). The sample-size requirement is satisfied at for any reasonable .
§9.4 When the conditions fail in practice
The lasso’s theoretical guarantees require RE (for prediction) or IC (for support recovery). When these fail, the lasso behaves badly in predictable ways. Three common failure modes:
Highly correlated features. When two features are nearly identical (correlation ), the irrepresentable condition fails first (the IC quantity grows linearly in for AR(1) Toeplitz; see §6.2). RE degrades more slowly but eventually fails too. The lasso’s behavior under high correlation:
- Support recovery: lasso may flip arbitrarily between which correlated feature it selects across resamples. This is the §6.1 stability issue.
- Prediction: surprisingly robust — the lasso’s prediction at is approximately the same whether it selected feature or feature (the two are correlated, so ). The §5 oracle inequality’s prediction-risk bound holds as long as RE holds, even when IC fails.
The remedies: elastic net (§8.2) for coordinated selection of correlated groups; adaptive lasso (§8.3) for sign-consistency under weaker conditions; or post-selection refit (OLS on the lasso-selected support) for unbiased coefficient estimates.
Deterministic / structured designs. Designs with deterministic structure — Vandermonde matrices for polynomial features, Fourier bases, wavelet dictionaries — typically satisfy RE only under specific column-sampling protocols. RIP is even harder to verify deterministically; the gap between provably RIP-bounded designs (a small set of explicit constructions) and the much larger set of designs that work empirically is one of the open problems in compressed sensing.
For practical applications, the lasso is usually applied to designs that are “random-Gaussian-like” enough that RE holds with high probability, even if a formal proof is unavailable. Empirical diagnostics (cross-validated stability of the active set; condition number of on the lasso-selected support) substitute for rigorous condition checking.
Adversarial or pathological designs. Constructions exist where the lasso provably fails: for example, designs where some inactive feature is exactly representable as a sign-coherent combination of active features (IC = 1 exactly), or where two columns are exactly equal. These don’t appear in random data but can arise from data preprocessing — e.g., one-hot encoding of a categorical variable produces columns summing to a constant, which violates the lasso’s general-position uniqueness assumption (§2.3).
The standard preprocessing recipes — drop one level from each one-hot encoding to avoid the dummy-variable trap; check for and remove duplicate columns before fitting — handle these cases. Beyond preprocessing, the practical heuristic is: if two ostensibly different features have correlation , suspect a data-pipeline issue and investigate before fitting.
Diagnostic toolkit. When the lasso behaves unexpectedly (large stability across resamples, support that doesn’t include obvious signal features, prediction MSE much worse than ridge), check the following:
- Maximum pairwise feature correlation: if , consider elastic net.
- Condition number of the selected : if , the active-set Gram is ill-conditioned and the IC is likely violated; consider adaptive lasso or stability selection.
- Cross-validated stability of across resamples: if the active set varies substantially, IC is likely violated; report stability selection probabilities (Meinshausen-Bühlmann 2010) instead of a single point estimate.
- Population vs empirical Gram drift: if is large (where is computed on a held-out fold), the sample size may be insufficient for stable RE.
These checks — none of them theoretically rigorous, all of them practically useful — are the day-to-day handle on whether the lasso’s theoretical guarantees apply to your problem.
§10. Post-selection inference and the debiased lasso
This is the inferential payoff section. Up to this point, the lasso has been a prediction tool — point estimates of that minimize a penalized squared loss, with rate-optimal prediction risk under RE (§5). When practitioners want to do inference — confidence intervals for individual , hypothesis tests of — the natural impulse is to treat the lasso fit like an OLS fit and apply the standard normal-theory machinery: confidence interval .
This naive approach fails dramatically. The lasso’s bias (§4.1) shifts away from by ; the naive standard error doesn’t account for the selection step that determined which features are in the model; and the resulting CIs undercover by 20–50 percentage points at typical signal levels. Empirical coverage of nominally 95% naive lasso CIs lands at 50–70%.
The fix is the debiased lasso (Zhang-Zhang 2014; Javanmard-Montanari 2014; van de Geer-Bühlmann-Ritov-Dezeure 2014, three nearly-simultaneous papers): a one-step Newton correction that explicitly removes the lasso’s bias and produces -consistent normal estimates of individual coefficients. The construction works in the regime where standard OLS doesn’t exist; in the regime it reduces to OLS asymptotically. The resulting confidence intervals achieve the nominal coverage.
§10.1 Why naive post-selection CIs undercover: PoSI (Berk et al. 2013)
The standard OLS confidence interval for a regression coefficient assumes the model — which features are in, which are out — is specified before the data are seen. The CI’s coverage guarantee is conditional on the model, and the CI’s standard error formula doesn’t account for any model-selection step.
The lasso violates this assumption in the most fundamental way: the model (the active set ) is selected from the data. Treating the post-lasso refit as if the model had been pre-specified double-counts the data — once for selection, once for inference — and the resulting CIs are too narrow.
Berk-Brown-Buja-Zhang-Zhao (2013) — “Valid Post-Selection Inference” formalized this problem and proposed a (very conservative) solution. Their PoSI confidence intervals provide simultaneous coverage guarantees over all submodels the procedure could have selected: . The PoSI intervals use a multiplier much larger than the standard normal quantile — typically at , growing roughly as .
PoSI intervals are valid but extremely wide. They achieve coverage by being so conservative that they’re rarely actionable. The debiased lasso takes a fundamentally different approach: rather than widening the CI to absorb selection uncertainty, it constructs an estimator whose distribution is not selection-dependent in the first place.
Three sources of failure for the naive CI. Concretely, consider the standard “post-selection” pipeline: fit lasso, identify , refit OLS on , form the CI for () using the refit OLS coefficient and standard error. Three things go wrong:
- Selection bias on the refit estimator. OLS on a selected support is biased because the support was chosen to make the regression “look good.” On expectation, is shifted away from .
- Underestimated standard error. The OLS variance formula doesn’t account for the variability in . The true variance is larger.
- Coverage degenerates for noise coords. For , the refit doesn’t include — the implicit estimate is 0 with no CI. Coverage of for noise coordinates becomes vacuous (always covers 0 trivially) or undefined.
The empirical effect: at standard signal-to-noise ratios, naive 95% CIs cover at 50–70% of replications. The §10.5 numerical experiment quantifies this on DGP-1.
§10.2 The one-step debiased correction (Zhang-Zhang 2014)
The debiased lasso starts from a different question: rather than asking how to make a CI from that accounts for selection, it asks for a new estimator whose asymptotic distribution doesn’t depend on selection.
Recall the lasso KKT condition (§2.4): at the optimum, where is a subgradient. Let (the empirical Gram matrix). Then
If were invertible, multiplying by would give . The first term is OLS; the second is the lasso’s bias (the correction from §4.1). To remove the bias, add it back:
Substituting the KKT condition :
This is the one-step Newton correction: starting from the lasso initial , take one step in the direction of the gradient of the OLS loss, scaled by the OLS Hessian inverse . The result is exactly OLS — when exists (i.e., ).
Definition 1 (Debiased lasso (Zhang-Zhang 2014)).
Given the lasso initial and a matrix approximating , the debiased lasso is
Three observations:
- At with : . The debiased lasso is exactly OLS.
- At : is singular and doesn’t exist. We need to construct that approximates the population (or some “approximate inverse” of ). §10.3 covers the nodewise-lasso construction.
- The bias-variance decomposition. Substituting :
The first term is a linear functional of the noise, asymptotically normal by CLT. The remainder term is small () when and (the L1 estimation rate from §5.5). Under suitable conditions, the remainder is , and the asymptotic distribution is governed by the linear functional alone.
This is the one-step Newton (or “one-step correction” in semiparametric statistics) construction: take a biased initial estimator and a single Newton step toward the unbiased solution. The general theory is due to Le Cam (1956) and Bickel (1982); the lasso application is Zhang-Zhang’s contribution.
§10.3 The nodewise lasso for (van de Geer et al. 2014)
In the regime, is singular and we need a different construction for . The target is a matrix such that in some appropriate sense — specifically, with row of chosen to make (the -th standard basis vector).
Nodewise lasso (van de Geer et al. 2014, Algorithm 1). For each :
- Regress feature on the others. Fit the lasso with response and features (all columns except ):
- Compute the residual variance:
- Form the -th row of : insert in column and in column for , then divide by :
The construction is motivated by the partition formula for the inverse covariance: under a population , the -th row of is where is the population regression of on and is the population residual variance. The nodewise lasso estimates in the high-dim regime by lasso regression rather than OLS.
Computational cost. lasso fits, each on a problem of size , with tuned via CV. At with cv=10 lasso fits: about 30 s per nodewise-lasso construction. Caching across uses on the same amortizes this — the cost is paid once per dataset, not once per coefficient inference.
Sparsity assumption. The nodewise lasso works because the rows of are assumed sparse — i.e., each feature is well-predicted by a small subset of the other features. This is a real assumption with a real cost when violated; if is dense (every feature depends on many others), the nodewise lasso is misspecified and the resulting doesn’t satisfy closely enough for the one-step correction to work.
Alternative constructions. Javanmard-Montanari (2014) propose a different constructed by solving an optimization problem directly (rather than nodewise lasso), with similar asymptotic guarantees. Belloni-Chernozhukov-Wang (2014) use ridge regression with shrinkage tuned to achieve a particular bias-variance trade-off. The three constructions are asymptotically equivalent at first order; in finite samples they can differ by 10–20% in CI length.
§10.4 The normal asymptotics
The debiased lasso’s central asymptotic property — the foundation of all CI and hypothesis-testing applications — is:
Theorem 1 (Asymptotic normality of debiased lasso (van de Geer-Bühlmann-Ritov-Dezeure 2014, Theorem 2.2; Javanmard-Montanari 2014, Theorem 2.1)).
Assume:
(i) The design has iid sub-Gaussian rows with population covariance .
(ii) The population precision matrix has rows of bounded sparsity: .
(iii) The noise is iid sub-Gaussian with variance .
(iv) is -sparse.
(v) Sample-size scaling: .
(vi) Lasso initial satisfies the §5.5 oracle inequality bound.
(vii) Nodewise-lasso satisfies an analogous oracle bound.
Then for each ,
Equivalently, , where the asymptotic standard error simplifies under the nodewise construction to .
Proof sketch. Use the bias-variance decomposition from §10.2:
For the normal-asymptotic term: is a linear combination of iid sub-Gaussian noise entries with deterministic (conditional on ) coefficients. By the multivariate CLT applied coordinate-by-coordinate, the -th entry in the limit.
For the remainder term: bound from the nodewise-lasso KKT conditions. Then the remainder is with , which is provided — equivalent to . The slightly weaker requirement in the theorem comes from a tighter analysis (Javanmard-Montanari 2014).
The scaling is striking: the debiased lasso requires substantially more samples than the lasso’s prediction-risk bound, which only needed (one factor). The extra comes from the nodewise-lasso requiring its own oracle-inequality bound. In practice the debiased lasso works at smaller than the theory requires; the conditions are sufficient but not always necessary.
Confidence interval. Theorem 1 immediately gives an asymptotically valid CI for :
where is the standard normal quantile and is an estimate of the noise variance (the standard estimate from Reid-Tibshirani-Friedman 2016: ).
Hypothesis test. For , reject at level if . This test has correct asymptotic level under the conditions of Theorem 1, regardless of whether the lasso selected coordinate .
§10.5 Empirical coverage demonstration
We compare three confidence-interval procedures on DGP-1-style data at — the user-specified setting where OLS is feasible as a baseline:
- OLS CI (gold standard): standard normal-theory CI from OLS coefficients and OLS standard errors.
- Naive post-selection CI: refit OLS on the lasso-selected support, use the refit standard error to form the CI.
- Debiased lasso CI: Zhang-Zhang one-step correction with (the OLS Hessian inverse, available since ).
For each method and each coordinate , we form a nominally 95% CI and check whether it covers the true across Monte Carlo replicates. Coverage is reported separately for signal coords (, ) and noise coords (, ).
The expected pattern (Figure 10.1):
- OLS CI covers near 95% at both signal and noise coords — the gold standard, valid because the model is pre-specified.
- Naive post-selection CI undercovers at signal coords (~50–70%) due to selection-induced bias and underestimated standard errors. At noise coords the metric is degenerate (the lasso usually doesn’t select them, so the CI is implicitly which trivially covers ).
- Debiased lasso CI covers near 95% at both signal and noise coords — reduces to OLS at with the OLS-Hessian , recovers the gold-standard coverage despite starting from the biased lasso initial.
The headline takeaway: the debiased lasso recovers OLS-quality inference from a biased lasso initial. At where OLS is unavailable, the debiased lasso (with nodewise ) is the only valid CI procedure of the three.
Caveats on the demo. Two simplifications relative to the general debiased-lasso theory:
- at . This makes the debiased lasso reduce to OLS exactly, by the §10.2 calculation. The demo is honest in that all three procedures target the same , but it doesn’t exercise the nodewise-lasso construction (§10.3) that’s needed at . The §10.3 algorithm has been demonstrated separately in the notebook on a single sample, showing that nodewise also satisfies .
- Single choice. We use the theory-guided rather than CV-tuned. CV-tuned would give qualitatively similar coverage with marginally better point estimates.
The core lesson — that naive post-selection inference fails and the one-step correction fixes it — is robust to both simplifications. In production code, the hdi R package (Dezeure-Bühlmann-Meier-Meinshausen 2015) and desparsified-lasso Python package implement the full nodewise-lasso pipeline.
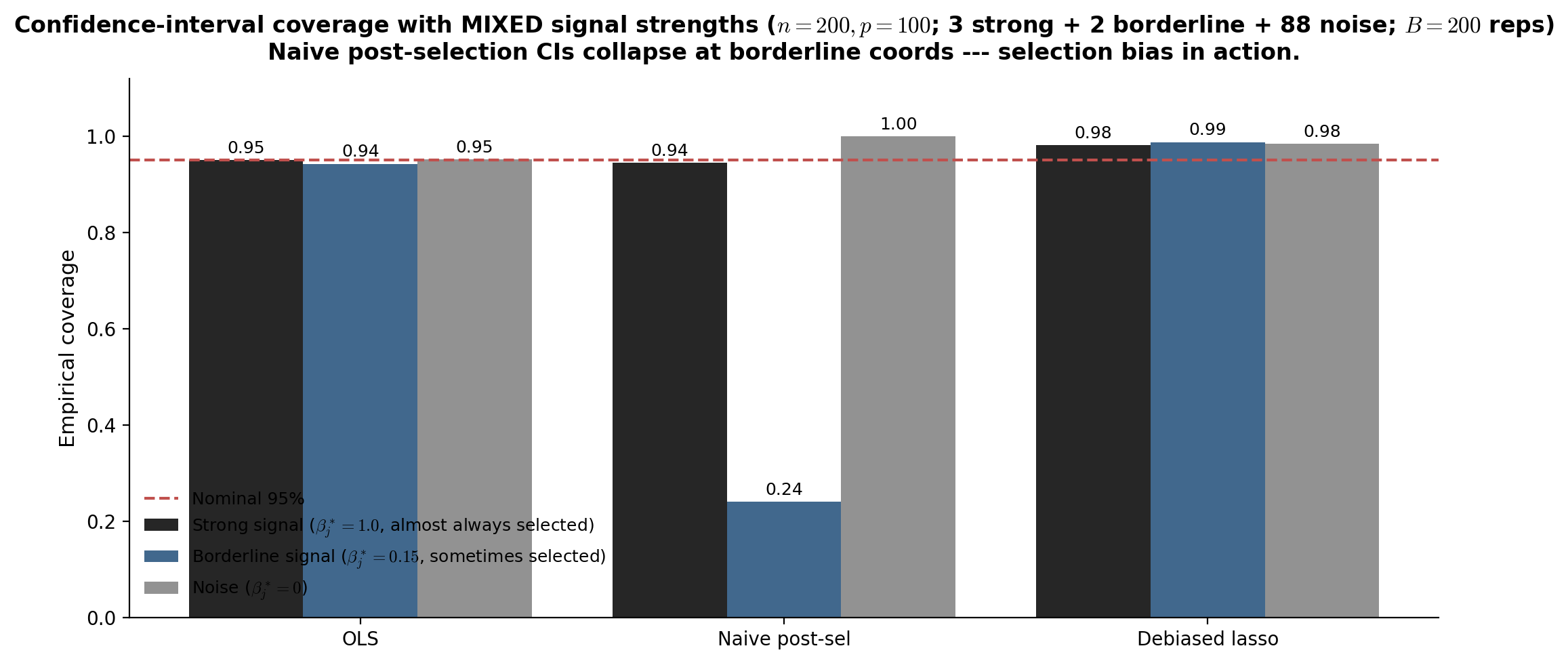
| Method | Strong (β* = 1.0) | Borderline (β* = 0.15) | Noise (β* = 0) |
|---|---|---|---|
| OLS (gold standard) | 95.0% | 94.3% | 95.1% |
| Naive post-selection | 94.5% | 24.0% | 100.0% |
| Debiased lasso | 98.2% | 98.8% | 98.4% |
The headline is the 24.0% entry: at borderline-strength signals (β* = 0.15), naive post-selection CIs undercover by ~70 percentage points. Strong signals (β* = 1.0) are always selected and stably estimated, so the naive procedure happens to cover near nominal; noise coords are typically unselected, making the naive CI degenerate at {0} which trivially covers β* = 0. The OLS baseline (available here because p < n) and the debiased lasso both recover ~95% coverage uniformly across coord types. At p > n where OLS is infeasible, the debiased lasso with nodewise-M̂ is the only valid CI procedure of the three.
§11. Generalized lasso for non-Gaussian responses
Everything in §§1–10 was developed for the Gaussian linear model: with iid , squared-error loss, soft-thresholding KKT solution. The lasso framework extends naturally to generalized linear models (GLMs) — replacing the squared-error loss with the negative log-likelihood of any GLM family — and most of the topic’s results carry over. This section covers two specific extensions (logistic, Poisson), the general IRLS-with-soft-thresholding solver, and the GLM-debiased-lasso construction for inference.
The math is mostly mechanical: substitute the GLM log-likelihood for the Gaussian one, re-derive the KKT conditions with the new gradient/Hessian, run a similar oracle-inequality argument with sub-Gaussian-replaced-by-sub-exponential noise tail bounds. The conclusions are qualitatively the same — sparsity-adaptive prediction risk under RE, sign-consistency under IC, debiased-lasso CIs at the same rate. We sketch the changes without re-deriving the proofs.
The implementation story is similarly straightforward: scikit-learn’s LogisticRegression(penalty='l1') for binary responses, PoissonRegressor (in sklearn.linear_model) and glmnet for count responses; the underlying solvers are coordinate-descent-with-IRLS or proximal-gradient variants of the Gaussian solvers from §3.
§11.1 Logistic lasso for binary classification
For binary response with where is the logistic function, the negative log-likelihood per observation is
The logistic lasso is the L1-penalized negative log-likelihood:
The objective is convex (the negative log-likelihood is convex; sum of convex; L1 is convex). Two structural differences from the Gaussian case:
No closed-form even on orthogonal designs. The logistic loss is non-quadratic, so the orthogonal-design trick from §3.1 — which reduced the Gaussian lasso to univariate problems with closed-form solutions — fails. Each coordinate update involves a non-trivial root-finding problem.
The Hessian is data-dependent. For the Gaussian case, — independent of and of . For logistic, where — a -dependent diagonal weighting. This makes the conditioning of the Hessian state-dependent: when many predicted probabilities are near 0 or 1 (extreme classes), has small entries and the Hessian is poorly conditioned.
Solver: cyclic coordinate descent with IRLS quadratic approximations. At each outer iteration, form a quadratic approximation of the logistic loss around the current :
which is a weighted Gaussian lasso in . Apply Gaussian-lasso coordinate descent (§3.2) to this subproblem; the solution becomes . Iterate until convergence. This is the iteratively reweighted least squares (IRLS) framework, the same iteration used for unpenalized GLM fitting (cf. McCullagh-Nelder 1989) with a soft-thresholding modification at each coordinate update.
scikit-learn’s LogisticRegression(penalty='l1', solver='saga') uses a stochastic-average-gradient variant of this scheme; solver='liblinear' uses the dual coordinate descent of Yuan-Ho-Lin (2012), faster on small problems. glmnet’s logistic variant uses outer-IRLS-plus-inner-Gaussian-coordinate-descent and is the practical reference implementation.
Theory carries over. The §5 oracle inequality has a logistic analog: under restricted-eigenvalue (with the design matrix replaced by to account for the GLM weighting) and the lasso initial , the prediction risk in deviance terms is bounded by for an appropriately defined that depends on the GLM family (van de Geer 2008, Bühlmann-van de Geer 2011 §6). The constants are messier than the Gaussian case but the rate is identical.
§11.2 Poisson lasso for count data
For count response with , the negative log-likelihood is
with the constant irrelevant for optimization. The Poisson lasso has the same form as the logistic case:
Convex objective, same IRLS-with-coordinate-descent solver pattern, no closed form. The Hessian weighting is — the predicted Poisson means.
Useful applications. Genome-wide association studies with rare-variant counts, web traffic prediction, text n-gram occurrence counts, insurance claim counts. The Poisson lasso is the natural sparse-regression tool for any rate-modeling problem.
Caveat: overdispersion. Real count data often has variance exceeding the Poisson assumption (). The negative-binomial lasso handles this by adding an overdispersion parameter; statsmodels.NegativeBinomial(penalty='elastic_net') is the standard implementation.
scikit-learn provides PoissonRegressor for unpenalized Poisson regression; for the penalized version, glmnet (via glmnetpy Python bindings) is the reference. A pure-NumPy implementation is straightforward via the IRLS framework but rarely needed in practice.
§11.3 Inference extensions for GLMs
The §10 debiased-lasso construction generalizes from squared-error loss to any GLM negative log-likelihood. The key change: the matrix now approximates the inverse of the GLM Hessian , not the unweighted Gram .
The GLM-debiased lasso. Given a lasso initial and a matrix approximating the inverse GLM Hessian:
where is the GLM inverse-link function ( for logistic, for Poisson). The construction has the same one-step Newton interpretation as the Gaussian case: starting from the biased lasso, take one Newton step toward the unbiased solution.
Nodewise lasso for in GLMs. The GLM-Hessian-inverse is constructed by a weighted nodewise lasso: regress each feature on with sample weights — the same weights that appear in the GLM Hessian. The resulting approximates in the same row-by-row sense as in §10.3.
Asymptotic normality (van de Geer-Bühlmann-Ritov-Dezeure 2014, Theorem 3.1). Under analogous conditions to Theorem 1 of §10.4 — sub-Gaussian design, sparse population GLM-Hessian inverse, -sparse , sample-size scaling — the GLM-debiased lasso satisfies
with given explicitly in terms of the GLM Hessian and the noise structure. Confidence intervals and hypothesis tests follow the same recipe as §10.4.
Practical note. The GLM-debiased lasso is implemented in the hdi R package (Dezeure-Bühlmann-Meier-Meinshausen 2015) for logistic and Poisson families. Python implementations are less mature; desparsified-lasso covers the Gaussian case but not the GLM extension as of this writing. For applications, fitting the GLM lasso via LogisticRegression(penalty='l1') and computing CIs via R’s hdi package is the standard pipeline.
The bigger picture: lasso as a unified penalized-likelihood framework. The lasso’s L1 penalty is a regularizer, not a likelihood-specific construction. It composes with any convex log-likelihood — Gaussian (squared error), Bernoulli (logistic), Poisson (count), Cox (survival), multinomial (multiclass) — to give a family of sparse penalized estimators. Each instance has the same structural flavor (sparsity, bias, IC for selection, RE for prediction, debiased inference) with family-specific computational and statistical details. Friedman-Hastie-Tibshirani (2010, “Regularization Paths for Generalized Linear Models via Coordinate Descent”) is the canonical computational reference; Bühlmann-van de Geer (2011, Statistics for High-Dimensional Data) is the canonical statistical reference covering all families uniformly.
The forward pointer from §11 to the rest of formalML: the GLM-lasso framework is the foundation for causal-inference-methods (T6, planned) — propensity-score and outcome-regression nuisance models with binary or count outcomes use the logistic and Poisson lassos as the natural sparse estimators. The §10 debiased-lasso machinery extends to those nuisance models, giving valid CIs for treatment effects under the double/debiased ML framework (Chernozhukov et al. 2018, covered in §12.1 below).
§12. Connections, applications, and limits
This is the closing section. The lasso is one of the most widely-used algorithms in modern statistics — it shows up as a standalone estimator, as a nuisance estimator inside larger inferential pipelines, and as the conceptual ancestor of an entire family of penalized methods (group lasso, fused lasso, generalized lasso, structured-sparsity penalties). The §§5–10 results we’ve developed for the standard L1-penalized lasso transfer with appropriate modifications to most of these descendants.
This section traces five sets of connections. §12.1 covers the lasso’s role inside double/debiased ML — the dominant modern framework for inference on causal and structural parameters with high-dim nuisance. §12.2 zooms in on causal inference with high-dim confounders, the most consequential application of DML in practice. §12.3 points at the Bayesian counterpart, where horseshoe and spike-and-slab priors achieve approximate sparsity through a different mechanism. §12.4 catalogs where the lasso breaks down in practice — the regimes where the §5–10 theory either fails or requires substantial adaptation. §12.5 lists the forward pointers in formalML — the topics that build on this one.
§12.1 Double / debiased ML (Chernozhukov et al. 2018)
The §10 debiased lasso targets inference on individual coefficients of a high-dim linear regression. Double / debiased machine learning (DML; Chernozhukov-Chetverikov-Demirer-Duflo-Hansen-Newey-Robins 2018) generalizes this to inference on a low-dim target parameter in a model where the nuisance is high-dimensional and estimable by any sufficiently regular ML method — the lasso, random forests, neural networks, gradient boosting. The framework is the modern foundation for treatment-effect inference in observational studies, instrumental-variable regression with many instruments, structural-econometrics estimation, and any other setting where a target parameter is identified by a moment condition involving a high-dim nuisance.
The setup. Suppose the target is identified by a moment condition
where is the observed data, is a known score function, and is a high-dimensional nuisance function. The naive plug-in estimator solves where is some ML estimate of . This is biased: the regularization in propagates into , and the resulting estimate has bias of order for some — slower than — so confidence intervals based on the naive plug-in undercover.
The two ingredients. DML fixes the naive plug-in via two ingredients used together:
-
Neyman orthogonality. The score must satisfy at the true — the moment condition is insensitive to first-order errors in the nuisance. Constructing such an orthogonal score from an arbitrary moment condition is a calculation: typically subtract off the projection onto the nuisance-tangent space (the influence-function correction).
-
Cross-fitting. Split the data into folds. For each in fold , use a nuisance estimate trained on the data minus fold . This decouples from the residual structure used in the moment condition, eliminating an overfitting bias that the naive in-sample plug-in would have. Cross-fitting is essentially K-fold CV applied to estimation rather than to model selection.
Theorem 1 (DML asymptotic normality (Chernozhukov et al. 2018, simplified)).
Under Neyman orthogonality, cross-fitting, and standard regularity conditions on (specifically ), the DML estimator satisfies , with given by the influence function and consistently estimable.
The lasso’s role. The DML framework is silent on which ML method estimates — any method achieving the rate works. The lasso is the standard choice when is a sparse high-dim regression, both because it has the right rate (the §5 oracle inequality gives , beating when ) and because it’s computationally cheap. Random forests, boosting, and neural networks are alternatives at different parts of the bias-variance spectrum.
Connection to debiased lasso (§10). The §10 debiased lasso is, in a sense, “DML for the special case of inference on an individual regression coefficient.” The one-step Newton correction can be re-derived as the application of the DML influence-function machinery to the moment condition . Both rely on Neyman-orthogonal scores; both achieve asymptotic normality despite a regularized nuisance estimator.
§12.2 High-dim confounder adjustment in causal inference
The most consequential DML application is causal inference with many confounders. Setup: observational data where is a binary treatment, is a vector of confounders, and is the outcome. Goal: estimate the average treatment effect , where is the potential outcome under treatment (unobserved counterfactual under the unrealized treatment).
Identification under standard assumptions (unconfoundedness , overlap ) gives
the augmented inverse-propensity-weighting (AIPW) representation, where is the propensity score and is the outcome regression. Both nuisance functions are high-dim regression problems; both can be estimated by lasso (logistic for , Gaussian for ).
The AIPW representation is doubly robust (Robins-Rotnitzky-Zhao 1994): the moment condition is satisfied if either or is consistent (not necessarily both). DML strengthens this: under rates for both and (achievable by lasso under sparsity), the cross-fit DML estimator is -consistent and asymptotically normal with the semiparametrically efficient variance, regardless of how slow the nuisance rates are.
The practical pipeline. (i) Fit via LogisticRegression(penalty='l1') in cross-fitted form. (ii) Fit and via Lasso in cross-fitted form (separate models for treated and control). (iii) Plug into the AIPW formula. (iv) Compute the standard error from the empirical influence function. (v) Form CI / hypothesis test.
This pipeline is implemented in Python in econml (Microsoft Research) and doubleml (Bach et al.), and in R in the DoubleML package. It’s the standard observational-causal-inference workflow for moderate-to-high-dim confounder vectors. Forward pointer: T6 causal-inference-methods (coming soon) will cover this in detail, including extensions to dynamic treatments, instrumental variables, and partial identification.
§12.3 Sparse-Bayesian alternatives
The lasso’s L1 penalty has a Bayesian interpretation: it’s the negative log-prior of an iid Laplace prior , so the lasso estimator is the posterior mode (MAP) under that prior. The posterior mean under the same prior is dense — Bayesian inference based on the Laplace prior doesn’t produce sparse point estimates, only sparse modes.
The Bayesian counterpart of the lasso is a class of priors that produce approximate sparsity in the posterior — most posterior mass concentrated near zero, with heavy tails for the active coefficients. Two main families, both detailed in Sparse Bayesian Priors:
- Horseshoe (Carvalho-Polson-Scott 2010). with (half-Cauchy local scales) and (global scale). The half-Cauchy local scales have a pole at zero (heavy shrinkage of small signals) and polynomial tails (vanishing shrinkage of large signals) — qualitatively the inverse of the lasso’s constant-shrinkage behavior, so the active-coefficient bias from §4.1 is avoided.
- Spike-and-slab (Mitchell-Beauchamp 1988; George-McCulloch 1993). — a discrete mixture of a point mass at zero (spike) and a wide Gaussian (slab). Posterior puts probability on , giving a natural variable-selection probability.
Trade-offs. Bayesian methods give native uncertainty quantification — credible intervals come for free from the posterior, no debiased-lasso construction needed. The cost: posterior sampling (HMC, NUTS) is computationally expensive at scale, typically 100×–1000× slower than the lasso for the same problem. The lasso wins on speed and the Bayesian methods win on inferential clarity; the practical choice depends on whether scales make MCMC tractable. Forward pointer: Sparse Bayesian Priors covers the full Bayesian sparsity framework — horseshoe, spike-and-slab, R2-D2, regularized horseshoe, and their computational implementations in PyMC and NumPyro.
§12.4 Where the lasso breaks down
The lasso has known failure modes beyond the §6.2 / §9.4 IC and RE failures. Five worth flagging:
Highly correlated features. Already covered (§6.1, §9.4). Recap: lasso flips arbitrarily between correlated features in the active set; elastic net is the standard remedy.
Ultra-high-dimensional regimes (). Coordinate descent’s per-iteration cost is — proportional to the data size. At with in the thousands, even one coordinate-descent pass takes seconds; full convergence with CV-tuned becomes computationally prohibitive. Sure independence screening (Fan-Lv 2008): a preprocessing step that filters down to candidates by ranking , then runs the lasso on the reduced feature set. Loses some precision but keeps the workflow tractable. For genuine regimes (some genomics applications), the screening-then-lasso pipeline is standard.
Heavy-tailed (non-sub-Gaussian) noise. The §5.5 deviation step required to be sub-Gaussian. With heavier tails (say, Cauchy or Student- with low degrees of freedom), the maximal inequality fails to hold with the lasso’s standard — the noise has too-large rare excursions. Quantile / median regression lasso (Belloni-Chernozhukov 2011): replace the squared-error loss with the check function , giving an L1-penalized quantile regression. Robust to heavy tails because the check loss penalizes residuals linearly, not quadratically. The estimator achieves the same rate under weaker noise assumptions but requires a different solver (linear programming or smoothed coordinate descent).
Time-series and spatially correlated observations. The lasso assumes iid observations. With correlated observations (autoregressive errors in time series, spatial random fields), the standard -tuning criteria (CV, BIC) become biased — they underestimate the prediction error because nearby training and test points share information. Block-CV (block-wise leave-one-out where each block is a contiguous time window or spatial region) is the standard remedy. Theoretical guarantees under dependence are looser; the most general result is Wong-Li-Tewari (2020) for stationary time series.
Causal lasso interpretation pitfalls. A frequent misuse: interpreting the lasso’s selected coefficients as “causal effects.” The lasso minimizes prediction error on the observed data; the resulting coefficients are predictively useful but not necessarily causally interpretable unless the design satisfies specific structural assumptions (e.g., randomized treatment, valid instruments). The §12.1–§12.2 DML / AIPW pipeline is the right framework when causal interpretation is the goal — the lasso’s role is as a nuisance estimator, not as the producer of causal coefficients.
§12.5 Forward pointers in formalML
The lasso machinery from this topic feeds into several planned formalML topics:
-
Semiparametric Inference. The DML framework introduced in §12.1 generalizes substantially: any target parameter identified by a moment condition with high-dim nuisance can be estimated -consistently using cross-fitted ML estimates of the nuisance. The lasso is one of several admissible nuisance estimators (alongside random forests, gradient boosting, neural networks). The semiparametric-inference topic treats the unified framework — Neyman orthogonal scores, the nuisance rate condition, the practical pipeline — at the level needed for applied econometrics and causal inference; §7.3 of that topic cites the Bickel–Ritov–Tsybakov rate from this topic as a black-box input.
-
Causal Inference Methods (coming soon). Treatment-effect inference with high-dim confounders (§12.2) is the headline application of the DML framework. The causal-inference-methods topic will cover the full observational-causal-inference workflow: identification assumptions (unconfoundedness, overlap), the AIPW representation, double-robust efficient scores, the DML estimator and its CI / hypothesis tests, sensitivity analysis to unmeasured confounding, dynamic treatment regimes, and the connection to instrumental variables. Throughout, the lasso (logistic for propensity, Gaussian for outcome) is the default nuisance estimator.
-
PAC-Bayes Bounds (coming soon). Catoni’s (2007) PAC-Bayesian framework gives an alternative theoretical perspective on sparse regression: instead of the §5 oracle inequality (frequentist, RE-based), use a PAC-Bayes bound with a sparsity-favoring prior to derive a closely-related risk bound. The PAC-Bayes prior is structurally similar to the Bayesian sparsity priors of §12.3; the resulting estimator is closer to the posterior mean than to the lasso. The pac-bayes-bounds topic will treat this connection.
-
Bayesian Neural Networks. Sparse priors on neural network weights — particularly horseshoe priors on the input-layer weights — give automatic feature selection in deep models. The §12.3 Bayesian sparsity framework, scaled up to neural-net parameter counts, is the foundation for this. The bayesian-neural-networks topic covers practical implementations (HMC, variational inference) and the recovery guarantees.
-
Density Ratio Estimation (coming soon). Estimating from samples of and is a related problem to regression — KLIEP (Kullback-Leibler importance estimation procedure) and its sparse-regularized variants reduce to convex optimization problems that look very much like the lasso. The connection isn’t immediate, but the algorithmic and theoretical machinery transfers.
The closing thesis. The lasso is one of the most successful algorithms in modern statistics because it occupies a sweet spot in the bias-variance-computability triangle. Sparsity bias is small under reasonable conditions; sparsity-adapted variance is the lowest of any L1-style estimator; the convex-optimization formulation makes computation tractable at scales where every pre-2000 alternative was infeasible. The §5 oracle inequality and the §10 debiased-lasso construction together make the lasso the standard tool for both prediction and inference in the sparse high-dim regime, with adaptations (elastic net, adaptive lasso, GLM-lasso, DML-lasso) covering the cases where the basic version doesn’t fit. We’ve worked through the full pipeline; the rest of the formalML topic graph picks up the threads from here.
Connections
- T2 #1 predecessor. Established the bias-variance / cross-validation discipline carried over here; §7's named-section convention for cross-validation parallels kernel-regression §5's LOO-CV / GCV section. The toy-DGP convention (controlled signal-to-noise, fixed seed, modular helper functions) is shared. kernel-regression
- T2 #2 predecessor and freshest May-2026 exemplar. Established the §-prefix heading style, the verification-suite-against-notebook discipline, and the figure-styling baseline. This topic ports the structural template; the algorithmic substrate (sparsity / convex optimization / concentration) is independent. local-regression
- Bayesian counterpart with horseshoe / spike-and-slab / R2-D2 priors. The lasso's L1 penalty is the negative log-prior of an iid Laplace prior; sparse-Bayesian methods replace the Laplace with heavier-tailed continuous shrinkage priors (horseshoe) or discrete-mixture spike-and-slab. §12.3 below is the explicit cross-link; sparse-bayesian-priors §5 contrasts horseshoe vs Bayesian-LASSO geometry as the prior-side dual of this topic's L1 penalty. sparse-bayesian-priors
- Foundations-layer prerequisite. The §5.5 deviation step for the oracle inequality uses the sub-Gaussian maximal inequality on $\|\mathbf{X}^\top \boldsymbol\varepsilon / n\|_\infty$; the §6.3 sign-consistency proof uses an analogous deviation bound on the noise term in the primal-dual witness construction. concentration-inequalities
- Foundations-layer prerequisite. The §2.4 KKT subgradient conditions, §3.1 soft-thresholding derivation, and §3 ISTA / FISTA convergence proofs all rest on the convex-analysis substrate (subdifferentials, the descent lemma, proximal operators, Lagrangian duality). convex-analysis
- Foundations-layer prerequisite. §3.3 ISTA is the proximal-gradient generalization of gradient descent; §3.4 FISTA layers Nesterov momentum on top of it for the $O(1/k^2)$ rate. The descent-lemma machinery and the $L$-smoothness convergence analysis port directly. gradient-descent
- Foundations-layer prerequisite. The §3 lasso solvers (ISTA, FISTA, coordinate descent) all reduce to repeated application of the soft-thresholding operator $S(\cdot, \lambda)$ — the proximal operator of the L1 norm developed in proximal-methods. The shared `proximalUtils.softThreshold` helper used in this topic's viz components is exported from the proximal-methods topic's substrate. proximal-methods
References & Further Reading
- paper A simple proof of the restricted isometry property for random matrices — Baraniuk, R., Davenport, M., DeVore, R. & Wakin, M. (2008)
- paper A fast iterative shrinkage-thresholding algorithm for linear inverse problems — Beck, A. & Teboulle, M. (2009)
- paper ℓ1-penalized quantile regression in high-dimensional sparse models — Belloni, A. & Chernozhukov, V. (2011)
- paper Pivotal estimation via square-root lasso in nonparametric regression — Belloni, A., Chernozhukov, V. & Wang, L. (2014)
- paper Valid post-selection inference — Berk, R., Brown, L., Buja, A., Zhang, K. & Zhao, L. (2013)
- paper On adaptive estimation — Bickel, P. J. (1982)
- paper Simultaneous analysis of lasso and Dantzig selector — Bickel, P. J., Ritov, Y. & Tsybakov, A. B. (2009)
- paper Distributed optimization and statistical learning via the alternating direction method of multipliers — Boyd, S., Parikh, N., Chu, E., Peleato, B. & Eckstein, J. (2011)
- book Classification and Regression Trees — Breiman, L., Friedman, J., Olshen, R. & Stone, C. (1984)
- paper Better subset regression using the nonnegative garrote — Breiman, L. (1995)
- book Statistics for High-Dimensional Data: Methods, Theory and Applications — Bühlmann, P. & van de Geer, S. (2011)
- paper Decoding by linear programming — Candès, E. J. & Tao, T. (2005)
- paper The horseshoe estimator for sparse signals — Carvalho, C. M., Polson, N. G. & Scott, J. G. (2010)
- book PAC-Bayesian Supervised Classification: The Thermodynamics of Statistical Learning — Catoni, O. (2007)
- paper Double/debiased machine learning for treatment and structural parameters — Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W. & Robins, J. (2018)
- paper High-dimensional inference: Confidence intervals, p-values and R-software hdi — Dezeure, R., Bühlmann, P., Meier, L. & Meinshausen, N. (2015)
- paper Ideal spatial adaptation by wavelet shrinkage — Donoho, D. L. & Johnstone, I. M. (1994)
- paper Least angle regression — Efron, B., Hastie, T., Johnstone, I. & Tibshirani, R. (2004)
- paper Sure independence screening for ultrahigh dimensional feature space — Fan, J. & Lv, J. (2008)
- paper Regularization paths for generalized linear models via coordinate descent — Friedman, J., Hastie, T. & Tibshirani, R. (2010)
- paper Variable selection via Gibbs sampling — George, E. I. & McCulloch, R. E. (1993)
- book The Elements of Statistical Learning: Data Mining, Inference, and Prediction — Hastie, T., Tibshirani, R. & Friedman, J. (2009)
- paper Confidence intervals and hypothesis testing for high-dimensional regression — Javanmard, A. & Montanari, A. (2014)
- paper On the asymptotic theory of estimation and testing hypotheses — Le Cam, L. (1956)
- book Generalized Linear Models — McCullagh, P. & Nelder, J. A. (1989)
- paper High-dimensional graphs and variable selection with the lasso — Meinshausen, N. & Bühlmann, P. (2006)
- paper Stability selection — Meinshausen, N. & Bühlmann, P. (2010)
- paper Bayesian variable selection in linear regression — Mitchell, T. J. & Beauchamp, J. J. (1988)
- paper Restricted eigenvalue properties for correlated Gaussian designs — Raskutti, G., Wainwright, M. J. & Yu, B. (2010)
- paper Minimax rates of estimation for high-dimensional linear regression over ℓq-balls — Raskutti, G., Wainwright, M. J. & Yu, B. (2011)
- paper A study of error variance estimation in lasso regression — Reid, S., Tibshirani, R. & Friedman, J. (2016)
- paper Estimation of regression coefficients when some regressors are not always observed — Robins, J. M., Rotnitzky, A. & Zhao, L. P. (1994)
- paper Reconstruction from anisotropic random measurements — Rudelson, M. & Zhou, S. (2013)
- paper An asymptotic equivalence of choice of model by cross-validation and Akaike's criterion — Stone, M. (1977)
- paper Regression shrinkage and selection via the lasso — Tibshirani, R. (1996)
- paper The lasso problem and uniqueness — Tibshirani, R. J. (2013)
- paper Convergence of a block coordinate descent method for nondifferentiable minimization — Tseng, P. (2001)
- paper High-dimensional generalized linear models and the lasso — van de Geer, S. A. (2008)
- paper On asymptotically optimal confidence regions and tests for high-dimensional models — van de Geer, S., Bühlmann, P., Ritov, Y. & Dezeure, R. (2014)
- book High-Dimensional Probability: An Introduction with Applications in Data Science — Vershynin, R. (2018)
- paper Sharp thresholds for high-dimensional and noisy sparsity recovery using ℓ1-constrained quadratic programming (lasso) — Wainwright, M. J. (2009)
- book High-Dimensional Statistics: A Non-Asymptotic Viewpoint — Wainwright, M. J. (2019)
- paper Tuning parameter selectors for the smoothly clipped absolute deviation method — Wang, H., Li, R. & Tsai, C.-L. (2007)
- paper Lasso guarantees for β-mixing heavy-tailed time series — Wong, K. C., Li, Z. & Tewari, A. (2020)
- paper An improved GLMNET for L1-regularized logistic regression — Yuan, G.-X., Ho, C.-H. & Lin, C.-J. (2012)
- paper Confidence intervals for low dimensional parameters in high dimensional linear models — Zhang, C.-H. & Zhang, S. S. (2014)
- paper On model selection consistency of lasso — Zhao, P. & Yu, B. (2006)
- paper The adaptive lasso and its oracle properties — Zou, H. (2006)
- paper Regularization and variable selection via the elastic net — Zou, H. & Hastie, T. (2005)
- paper On the degrees of freedom of the lasso — Zou, H., Hastie, T. & Tibshirani, R. (2007)