Bayesian Neural Networks
Weight-space posteriors over neural networks: Laplace approximation, MC-dropout as approximate VI, deep ensembles, stochastic-gradient MCMC (SGLD and SGHMC), calibration diagnostics, and the function-space view via NNGP and NTK
Overview
A trained neural network gives us a function, but it does not tell us how confident to be in that function. A point-estimate classifier confidently extrapolates its decision rule into regions where no training data lives, with no language for “I don’t know.” Bayesian neural networks are the response: instead of a single weight vector that minimizes a training loss, we work with a distribution over weights and integrate predictions against it, so predictive variance grows where the data has nothing to say. The catch is that is a distribution on for on the order of to , and the posterior is intractable in four distinct ways for any non-trivial network.
This topic develops the practical recipes that make BNN inference work at deep-learning scale. §1 frames the problem on a 2D Two Moons toy classifier so the picture is visible. §2 lifts the geometric picture into a formal weight-space posterior, derives the weight-decay-as-MAP identity, and explains the three structural ways the Bernstein–von Mises asymptotic fails for neural networks. §§3–7 develop five recipes for fitting the posterior — Laplace approximation, MC-dropout, deep ensembles, stochastic-gradient Langevin dynamics (SGLD), and stochastic-gradient HMC (SGHMC) — each addressing a different subset of the §2.4 obstacles. §8 evaluates them head-to-head on calibration metrics: expected calibration error, the Brier score, and negative log-likelihood as a proper scoring rule, plus the epistemic-aleatoric decomposition and the cold-posterior effect. §9 closes with the function-space view from the neural network Gaussian process (NNGP, Neal 1996) and the neural tangent kernel (NTK, Jacot et al. 2018), which ties weight-space methods to the Gaussian Processes machinery.
This is the sixth topic of T5 Bayesian & Probabilistic ML, after Variational Inference, Gaussian Processes, Probabilistic Programming, Mixed-Effects Models, and Stacking & Predictive Ensembles. It is the T5 flagship — the topic where the substrate of the prior five topics (variational families, GP machinery, model declaration, hierarchical structure, predictive averaging) gets combined into the catalog of methods practitioners actually reach for when the model is a deep network and uncertainty matters.
1. Why Bayesian over the weights
A trained neural network gives us a function, but it does not tell us how confident to be in that function. A point-estimate classifier on the Two Moons distribution — two interleaving crescents in , separable by a smooth nonlinear boundary, contaminated with isotropic noise — produces a single decision rule and confidently extrapolates that rule into regions where no training data lives. The rule is wrong somewhere, but the model has no way to say where. For an ML practitioner, this is a structural problem: medical-imaging classifiers, autonomous-vehicle perception models, and clinical-decision-support systems all need to know when they don’t know. A model that returns “99% confident” everywhere — including on inputs unlike anything it has ever seen — is a liability.
Bayesian neural networks are the response. Instead of a single weight vector that minimizes a training loss, we work with a distribution over weights, conditioned on the training data . Predictions integrate over that distribution. This topic is the catalogue of practical recipes for building, fitting, and reading that distribution when the model has thousands or millions of weights and the posterior is intractable in every standard sense. §§3–7 develop five recipes — Laplace approximation, MC-dropout, deep ensembles, SGLD, SGHMC. §8 evaluates them head-to-head on calibration. §9 closes with the function-space view. This section frames why the recipes are needed and what they share.
1.1 What a point-estimate model can’t tell us
Fix notation. A neural network with weights is a parametric function assembled from compositions of affine maps and elementwise nonlinearities. For binary classification, and the model produces a real-valued logit which we squash through the logistic sigmoid to get a class-1 probability . The likelihood under the Bernoulli observation model is
A point-estimate network minimizes a regularized cross-entropy loss using stochastic gradient descent or one of its momentum variants, and returns the single learned weight vector . At test time the model produces a single predicted probability . Two things are missing.
The first is uncertainty about the prediction. The model returns a number near or near , with no companion estimate of how much that number would change under a different reasonable choice of . The second is uncertainty about itself. The training loss is non-convex in ; the SGD trajectory ends in some local minimum determined by initialization, batch order, and learning-rate schedule; a different run with a different seed lands in a different minimum, with potentially different predictions far from the training data. The point estimate is one of many plausible weight vectors, and the model has no language for that fact.
1.2 The predictive distribution and the four obstacles
The Bayesian fix is to replace with the full posterior. Place a prior on the weights — typically the isotropic Gaussian that pairs with the regularizer above (§2.2 makes this correspondence explicit). Bayes’ rule gives where is the likelihood of the training data under weights . The predictive distribution at a new input marginalizes the weights out:
Where the data is dense, plausible weight settings agree on what should be, and the integral concentrates — predictive variance is small. Where the data is sparse, plausible weight settings disagree, the integral spreads, and predictive variance grows. The model knows when it doesn’t know, because “I don’t know” is encoded as breadth in the weight posterior.
The catch is that is a distribution on for on the order of to , and the posterior is intractable in four distinct ways. The marginal likelihood has no closed form for any non-trivial network, so we cannot evaluate pointwise without an approximation. The negative log-likelihood is deeply non-convex in : by symmetry, every loss-landscape mode has copies under permutations of the hidden units, and the modes are separated by sharp ridges where Gaussian approximations break down. The dimension is high enough that vanilla MCMC mixes too slowly to be useful at deep-learning scale. And the likelihood gradient requires a full pass over — feasible for in the hundreds, infeasible for the millions that motivate using a neural network in the first place.
Every method in this topic is an answer to one of these obstacles. Laplace approximation (§3) gives up on the multimodal structure and fits a single local Gaussian centered at the MAP estimate — cheap and asymptotically justified by the Bernstein–von Mises theorem from formalStatistics: Central Limit Theorem that §2 imports from formalstatistics. MC-dropout (§4) reinterprets the dropout regularizer used at training time as a Bernoulli variational posterior and turns the deterministic predictor’s stochastic forward passes into Monte Carlo posterior samples — almost free, but the variational family is rigid. Deep ensembles (§5) abandon weight-space inference altogether and treat independently-trained networks as approximate samples in function space — empirically the strongest of the cheap methods, but the theoretical justification is delicate. Stochastic-gradient Langevin dynamics (§6) and stochastic-gradient HMC (§7) bring the asymptotic exactness of MCMC into the deep-learning regime by injecting calibrated Gaussian noise into mini-batch gradient updates — the noise compensates for the bias mini-batching introduces, and the resulting stochastic process has the posterior as its stationary distribution.
1.3 The geometric picture and the road ahead
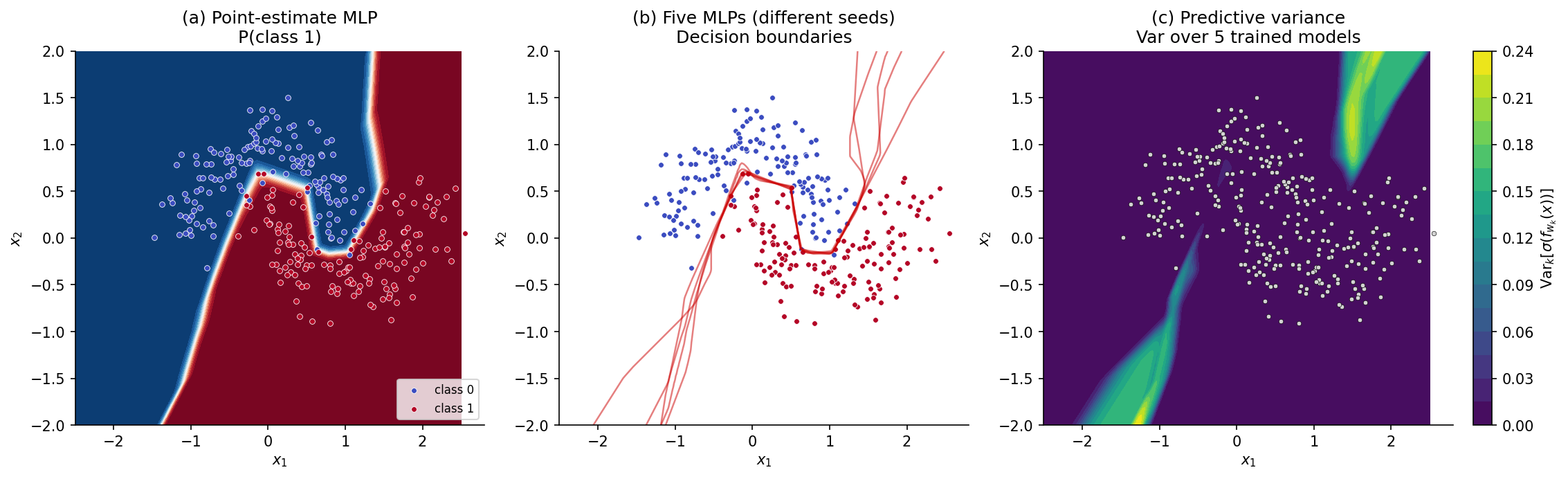
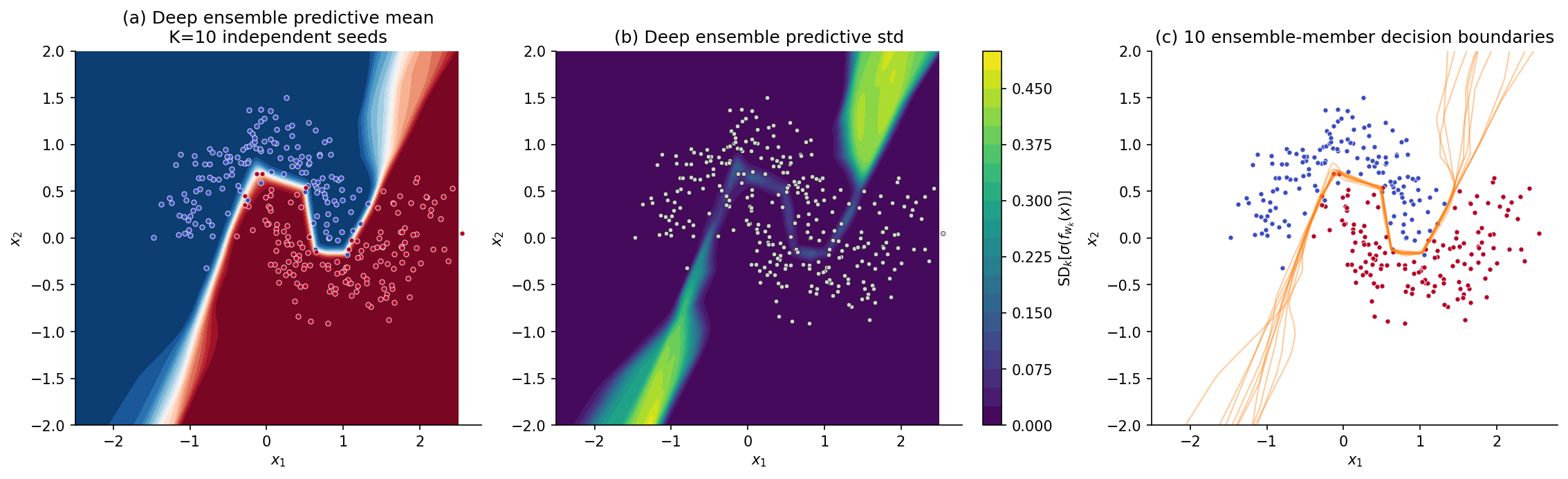
For the rest of this section we work on a 2D toy classifier so the picture is visible. Data are drawn from Two Moons with noise level at points. We fit a small MLP — three hidden layers, 32 ReLU units each — by minimizing the regularized binary cross-entropy loss with for 200 Adam epochs. The point-estimate model gives the decision surface in panel (a) of Figure 1: a clean boundary separating the two classes, with predicted probabilities near or near across most of the input space — high confidence even at distances from the data where any honest model should hesitate.
To see what an honest predictive distribution looks like we fit five copies of the same architecture from independent random initializations. Panel (b) overlays the five -probability decision boundaries. Where the data is dense, the boundaries agree and the overlay is sharp. Far from the data — in the corners of the input frame — the boundaries fan out: five plausible models trained on the same data give five different answers in the regions where the data has nothing to say. Panel (c) renders the disagreement as a heatmap of predictive variance over the input space, the variance of the predicted class-1 probabilities across the five models. Bright regions are where the model knows it doesn’t know. The five-model ensemble previewed here is the embryo of every method in this topic, and §5 formalizes it as a deep ensemble; §§3, 4, 6, 7 will produce comparable heatmaps from very different mechanisms.
A second axis of uncertainty matters too. If two data points sit in the same input neighborhood but carry different class labels — which Two Moons can produce in the strip between the crescents at high noise — no model on any architecture can confidently predict that neighborhood. That is aleatoric uncertainty: irreducible noise inherent in the data-generating process. The variance from disagreement among trained models is epistemic uncertainty: it reflects what the model would learn from more data, not what no model can ever learn. §8 disentangles the two formally; for now we note that BNNs primarily address epistemic uncertainty, and that a calibrated BNN should report large epistemic variance off-distribution and large aleatoric variance in noisy regions of the support.
The §2 derivation lifts this geometric picture into a formal weight-space posterior — the object the rest of the topic approximates. With that machinery in hand, §3 fits its first Bayesian neural network.
2. The weight-space posterior
The §1 picture — a model that should report breadth of plausible weight settings as predictive variance — is geometric. §2 lifts it into formal mathematics. The deliverable of this section is four facts: (i) the posterior under a Gaussian weight prior has a closed-form negative-log expression; (ii) maximizing that posterior is equivalent to L2-penalized empirical-risk minimization, so the well-known weight decay regularizer is a maximum-a-posteriori estimator under a specific prior; (iii) the Bayesian central-limit theorem (Bernstein–von Mises) guarantees that, in well-specified parametric models, the posterior asymptotically concentrates as a Gaussian centered at the MLE; and (iv) the regularity conditions for that theorem fail for typical neural networks, in three specific ways that motivate the four approximation strategies of §§3–7.
2.1 The Gaussian-prior MLP
Fix a parametric MLP with weights . For binary classification the conditional distribution of the label given the input is Bernoulli with logit : where is the logistic sigmoid. We complete the model with a Gaussian prior on the weights:
Definition 2.1 (Gaussian-prior MLP).
Let be an MLP with weights and Bernoulli observation likelihood as above. Place the isotropic Gaussian prior for some scale . The weight-space posterior given training data is the conditional distribution
The choice of as the prior covariance is the default in the BNN literature and the one we’ll work with throughout. It assumes weights are a priori independent and identically distributed — a strong assumption that ignores all structure in the weight tensor (layer, channel, position) but keeps the math tractable. Heavy-tailed and hierarchical priors are the subject of Sparse Bayesian Priors; per-layer prior scales are revisited in §8.5’s cold-posterior remark. For now, is a single scalar hyperparameter — large is a weak prior (close to MLE), small is a strong prior (heavy regularization).
2.2 The negative log-posterior, and weight decay as a Bayesian prior
Take the negative log of the posterior: The first term is the negative log-likelihood — the cross-entropy training loss (modulo signs). The second is a quadratic in , since the prior is Gaussian: , where the constant absorbs . The third does not depend on . Stripping -independent constants we get where is a constant in . This is structurally the L2-penalized cross-entropy training loss with regularization strength .
Proposition 2.2 (MAP equals weight decay).
Let be the L2-penalized cross-entropy loss with weight-decay strength , and let . Under Definition 2.1’s Gaussian prior with , the maximum-a-posteriori estimator coincides with .
Proof.
Maximizing a function and minimizing its negative are equivalent, so . From the calculation above, with , The first two terms are exactly , and does not depend on . So .
∎Three corollaries are worth pulling out, each with downstream consequences for §§3–8.
Weight decay is a Bayesian regularizer. The standard “weight decay” hyperparameter in deep-learning libraries has a Bayesian interpretation: is the inverse variance of the implicit Gaussian prior on the weights, . A weight-decay-trained model with is the MAP estimator under a prior on each weight. The choice of is therefore a choice of prior, and “tuning on a validation set” is empirical-Bayes hyperparameter selection. This is the canonical home for the cross-cutting concept of weight decay — the slug never gets its own page; the concept lives here.
The MAP is the starting point for §3. The Laplace approximation builds a Gaussian posterior approximation centered at . Because , any standard PyTorch model trained with weight decay is already the center of a Laplace approximation; we just haven’t computed the surrounding curvature yet. §3 fills in that missing piece.
The cold-posterior caveat. Many BNN practitioners empirically find that tempered posteriors with — equivalently, larger than the prior naturally specifies — give better-calibrated predictions than the strict Bayesian . This is the “cold-posterior effect” (Wenzel et al. 2020) and indicates that the Gaussian prior is misspecified for typical training datasets: the data effectively want a stronger regularizer than the principled delivers. The phenomenon is one of the central open problems in BNNs and is treated formally in §8.5.
2.3 The Bernstein–von Mises asymptotic
What does the weight-space posterior look like for large ? The classical result is the Bayesian central-limit theorem, also known as Bernstein–von Mises:
Theorem 2.3 (Bernstein–von Mises).
Let be a regular parametric family with fixed, and suppose the data are iid from for some interior . Let denote the MLE based on , and let denote the Fisher information matrix at the true parameter. Under standard regularity conditions (see formalstatistics’s formalStatistics: Central Limit Theorem topic), as : in posterior probability, where denotes total-variation distance.
The proof is the subject of formalstatistics’s central-limit-theorem topic. In words: the posterior, recentered at the MLE and rescaled by , converges in total variation to a Normal distribution with covariance equal to the inverse Fisher information. Equivalently, for large the un-rescaled posterior is approximately a Gaussian centered at the MLE with covariance the inverse total Fisher information .
This is the asymptotic license for §3’s Laplace approximation. Under BvM, fitting a Gaussian centered at the MAP with the right curvature gives a posterior approximation that is exact in the limit. The Laplace construction in §3 will use the observed Fisher information , which differs from by a fluctuation that is itself . The point is: there is a principled reason to expect the posterior to be approximately Gaussian centered at the MAP for large , provided the regularity conditions hold.
2.4 Why Bernstein–von Mises fails for neural networks
The regularity conditions for BvM are: fixed, model well-specified, MLE consistent and asymptotically Normal, Fisher information matrix positive-definite at , posterior absolutely continuous with respect to the prior. These conditions fail for typical neural networks in three structural ways.
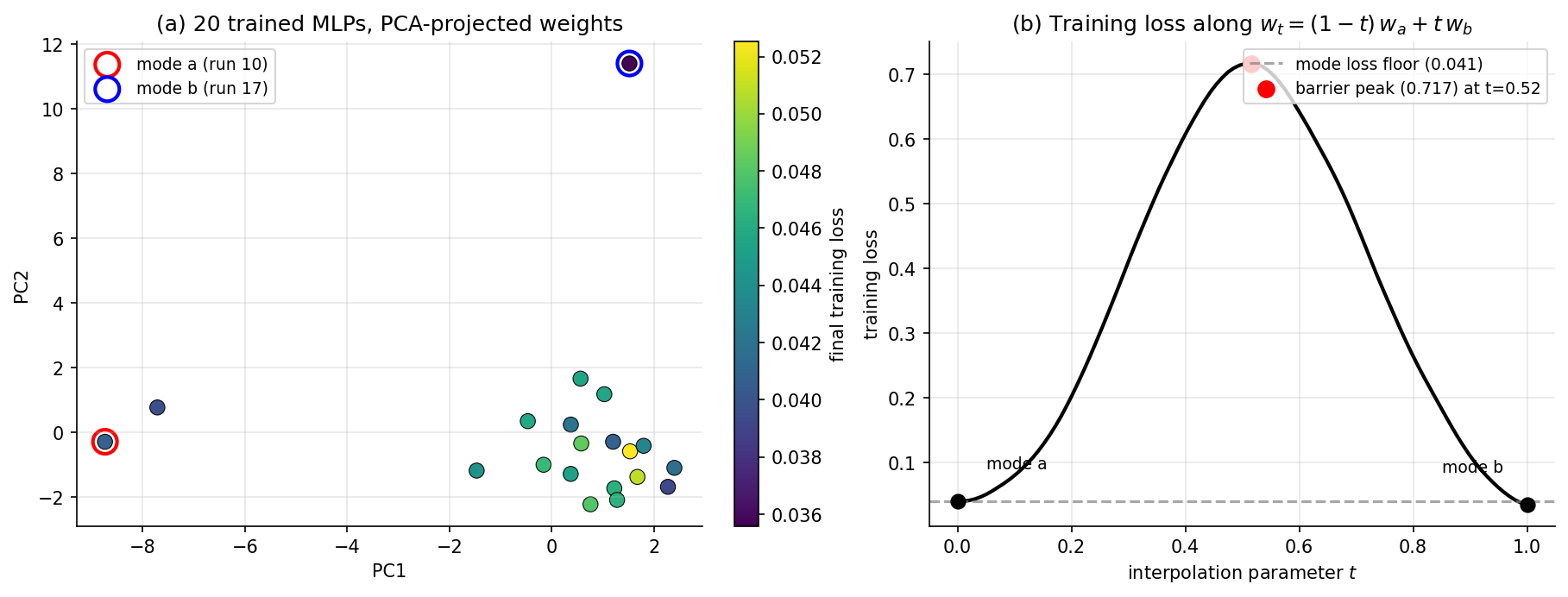
Hidden-unit permutation symmetry. Consider an MLP layer with hidden units, input weights and biases. Permuting the columns of (and the corresponding entries of and the next layer’s row weights) gives an exactly equivalent function. So the function is invariant under , the symmetric group on elements. The likelihood inherits this symmetry, and so does the posterior. There are at least identical modes per hidden layer. For a 32-unit layer, . The posterior has more than identical modes, separated by ridges of low likelihood — interpolating linearly between two modes via does not generally produce another mode, since the loss along the interpolation rises through a barrier. Vanilla MCMC can mix over the connected component of the posterior support that it starts in, but cannot in finite wall-clock time mix between disconnected modes. BvM’s “single Gaussian centered at the MLE” is wrong globally because there is no single MLE.
ReLU positive scaling. For ReLU activations, for any . So if we multiply the input weights to a hidden unit by and divide the outgoing weights by , the function is unchanged: is invariant under the action of the multiplicative group on weights. This is a continuous symmetry, not a discrete one, and it means that even within a single permutation class the MLE is not isolated — it sits on a -dimensional submanifold of equally-good weights. The Fisher information matrix is singular along this submanifold (the gradient of the log-likelihood is zero in those directions because the function does not change), so BvM’s invocation of as a positive-definite covariance fails. Weight decay breaks the symmetry by penalizing rescalings — is minimized at a specific — so the MAP is locally unique even when the MLE is not. But the underlying likelihood is not strongly identified.
Over-parametrization. Modern deep networks have . ResNet-50 has parameters; ImageNet has training images. BvM operates in the regime fixed, . The opposite regime — with fixed or growing slowly — is the regime of high-dimensional statistics, and the asymptotics there are different. The infinite-width limit of §9 makes one specific version of this regime tractable (function-space rather than weight-space), but for finite-width over-parametrized networks, BvM gives no asymptotic guidance.
These three failure modes organize the rest of the topic. Laplace (§3) gives up on the global picture and approximates the posterior locally at the MAP — accepting the failure of BvM globally and pursuing a local Gaussian that captures local curvature even if it misses the permutation copies and the ReLU rescaling submanifold. MC-dropout (§4) uses a tractable but rigid variational family that sidesteps the exact-posterior question entirely. Deep ensembles (§5) sample approximate samples from different initializations, getting some coverage of distinct modes. SG-MCMC (§§6–7) accepts the multimodality and tries to mix between modes via Langevin dynamics on minibatches.
Remark (Why naïve sampling fails).
Three obstacles in compact form, as a checklist for §§3–7. (i) Multimodality: exact replicas per layer; vanilla MCMC cannot mix in any practical wall-clock time. (ii) Identifiability: ReLU positive-scaling submanifold; Fisher information singular within each mode under the un-regularized likelihood. (iii) Computational cost: full-data gradients infeasible at deep-learning scale; vanilla HMC needs the gradient at every leapfrog step, an pass. Each method in §§3–7 sidesteps a subset of these obstacles via a specific technical trick.
3. The Laplace approximation
§2 ends with a problem and a permission. The problem is that the true weight-space posterior is intractable: no closed-form normalizer, more than identical modes, and continuous symmetries that make the Fisher information singular within each mode. The permission is Bernstein–von Mises: under the regularity conditions the posterior is asymptotically a Gaussian centered at the MLE. The Laplace approximation accepts that the BvM regularity conditions don’t strictly hold globally but observes that they hold locally at any sufficiently regular minimum of the negative log-posterior — and builds a Gaussian approximation by Taylor-expanding around such a minimum. The construction goes back to Laplace’s 1774 calculation of the asymptotic value of ; MacKay’s 1992 PhD thesis brought it into Bayesian neural networks; the modern revival is Daxberger et al. 2021 (laplace-torch), which scales the construction to ImageNet-class networks via Kronecker-factored curvature.
3.1 The construction
Let be the negative log-posterior, modulo the unknown constant . From §2.2 we have Suppose is a local minimum at which is twice continuously differentiable and the Hessian is positive-definite. Taylor-expand to second order around : At a local minimum , so the linear term vanishes. Dropping the higher-order terms — the Laplace approximation itself — we get Exponentiating and renormalizing, The construction takes a Gaussian whose mean is the MAP and whose precision is the local curvature of the negative log-posterior. Two further facts come for free.
The Hessian decomposes additively. From the form of , the data Hessian plus the prior precision. The prior contribution is constant in , isotropic, and explicitly positive-definite; it stabilizes the data Hessian when the latter has near-zero or negative eigenvalues from saddle directions or the §2.4 ReLU rescaling submanifold. In practice we either compute directly or compute and add explicitly.
The marginal likelihood comes for free as a side effect. The Laplace approximation also gives a closed-form estimate of : known as the Laplace marginal-likelihood approximation. This is the basis of Variational Bayes for Model Selection and the BIC’s asymptotic form (cross-link to formalstatistics’s formalStatistics: Model Selection and Information Criteria ).
Definition 3.1 (Laplace approximation).
Given a twice-differentiable negative log-posterior with positive-definite Hessian at a local minimum , the Laplace approximation to the posterior is the Gaussian
3.2 Asymptotic exactness — and where it stops
Theorem 3.2 (Asymptotic exactness of Laplace under BvM).
Suppose the conditions of Theorem 2.3 hold. Let be the MAP based on iid observations and the negative-log-posterior Hessian at . Let be the Laplace approximation. Then in posterior probability.
Proof.
Two ingredients combine. First, , where is the MLE: differentiating and setting to zero gives . The right-hand side is for the Gaussian prior, so . The MLE satisfies , so solves the first-order condition , which gives since the data Hessian scales as .
Second, in probability by the law of large numbers applied to the per-observation Fisher information contributions. So at first order.
Putting these together, in total variation. Theorem 2.3 says the true posterior also converges to this limit. By the triangle inequality for , the Laplace approximation converges to the true posterior.
∎The §2.4 caveats apply with full force here. The proof above assumes (i) fixed, (ii) positive-definite at , and (iii) the BvM regularity conditions. For neural networks: is not fixed in any meaningful sense (over-parametrization), has near-zero eigenvalues from the ReLU rescaling submanifold (we rescue this with , but the result is a Laplace approximation around an artificially regularized minimum), and the global posterior has many modes that the Laplace approximation around any one of them cannot represent. So Theorem 3.2 should be read as a local guarantee that the Gaussian fit is the best second-order approximation around , plus an asymptotic guarantee that this best approximation converges to the truth in well-specified parametric settings. For BNNs we get the local part and lose most of the asymptotic part.
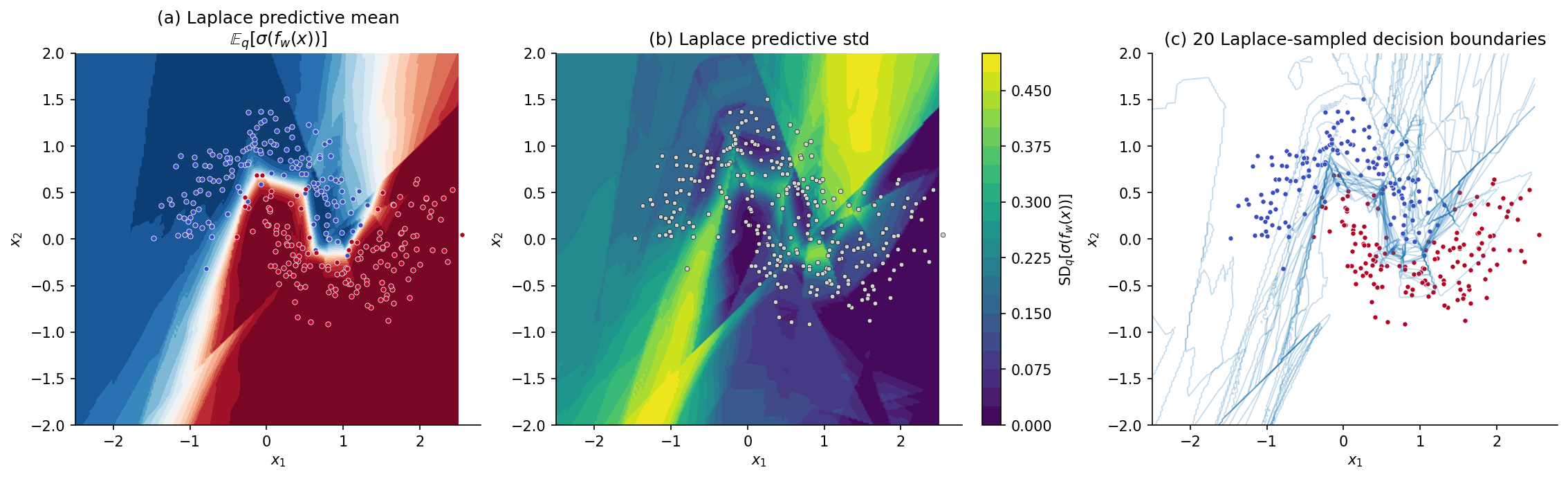
This is enough for a useful method. The Laplace BNN’s predictive mean recovers the point estimate, its predictive variance grows away from the data exactly because the local quadratic in flattens away from , and the construction needs no sampling at all once and are in hand. What it loses — multi-modality, ReLU-rescaling spread — is exactly what §§5–7 will recover.
3.3 The predictive distribution under linearization
A Gaussian posterior over weights does not directly give a Gaussian posterior over outputs, because is a nonlinear function of . The integral has no closed form. The standard reduction is first-order linearization of the network around the MAP: Under this linearization, is an affine function of . If , then the logit is Gaussian with mean and variance .
Proposition 3.3 (Linearized Laplace predictive).
Define and . Under the linearized Laplace approximation, the logit at is approximately Gaussian: The class-1 probability under the moment-matched probit approximation is
The factor comes from MacKay’s 1992 Gaussian-CDF approximation to the sigmoid: . The reader sees the predictive variance enter explicitly: where is small (data-dense regions, where the network is well-determined), the predictive collapses to — the point estimate from §1. Where is large (off-distribution regions, where small changes in produce large changes in ), the predictive is squashed toward — the model’s confession of ignorance.
In practice we have two implementation choices for the predictive: (a) closed-form via Prop 3.3, computing at each test point and the matrix product ; (b) Monte Carlo, sampling and averaging over samples. For the §3.5 Two Moons figure we use (b) because it lets us also visualize sample decision boundaries; in production BNN libraries the closed-form (a) is faster.
3.4 Practical curvature
Computing and storing for in the millions is impossible — memory, inversion. Three standard reductions trade fidelity for tractability.
Last-layer Laplace (Daxberger et al. 2021). Fix all but the final linear layer’s weights at their MAP values; do Laplace only over the last layer. The last layer typically has parameters — for a 32-unit penultimate layer × output classes, . is cheap. Empirically competitive with full Laplace on a wide range of tasks; the underlying intuition is that in over-parametrized networks, most of the weight-space uncertainty that affects predictions is concentrated in the final layer.
Kronecker-factored approximate curvature (KFAC; Martens & Grosse 2015). For each layer, approximate the Fisher information block as a Kronecker product , where is the input-activation second moment and is the output-gradient second moment. Storage cost reduces from to per layer. The Kronecker assumption is structural (it ignores cross-layer covariance entirely), but matches the block-diagonal-plus-Kronecker structure of the Fisher information of natural-gradient methods.
Diagonal Fisher. Take only the diagonal of . Cheapest possible — memory — but discards all weight correlations. Often too aggressive: the diagonal Hessian eigenvalues are unreliable estimates of the full spectrum, and diagonal-Fisher Laplace BNNs frequently underestimate predictive variance in correlated directions.
For the §3.5 Two Moons example with parameters, full Laplace is feasible. For real-world BNNs, last-layer or KFAC is the practical choice; the laplace-torch library (Daxberger et al. 2021) implements all three reductions and is the default tool.
3.5 Algorithm and worked example
Algorithm 3.4 (Laplace-fit BNN).
Input: training data , network , prior scale , sample count . Output: predictive distribution at test inputs.
- Compute via Adam or SGD with weight decay .
- Compute the data Hessian via autodiff (or one of the §3.4 reductions).
- Form and stabilize: for small if any eigenvalue is non-positive.
- Cholesky-factor .
- Sample for ; set .
- Predict via , or via Prop 3.3’s closed-form.
The §1 first-seed model serves as . Step 2 uses torch.autograd.functional.hessian on the negative-log-posterior of the full training set; for this is s on CPU. The contribution is automatic (we trained with weight decay , so and the prior precision contribution is ). Stabilization handles the residual ReLU-rescaling near-singularity. The Cholesky factorization on a matrix is s; sampling posteriors and predicting on the -point grid is s.
4. MC-dropout as approximate variational inference
The Laplace approximation of §3 builds a Gaussian posterior over weights from a single point estimate plus its local curvature. The construction is principled but expensive once the network is large — full Laplace needs Hessian storage, and even the §3.4 reductions (last-layer, KFAC) require non-trivial implementation effort. MC-dropout (Gal & Ghahramani 2016) is the cheap end of the BNN spectrum: it observes that a dropout-regularized network, trained the standard way, is already doing variational inference under a specific variational family, and that the only change needed at test time to extract a predictive distribution is to leave dropout on and average over stochastic forward passes. No new training, no Hessian, no extra hyperparameters beyond what dropout already requires. The trade is that the variational family is rigid in a way that systematically underestimates epistemic uncertainty in some regimes; §8’s calibration analysis quantifies the trade.
4.1 Recap: dropout as a regularizer
Dropout (Srivastava et al. 2014) trains a network by, at each minibatch, sampling a Bernoulli mask for each layer’s input activations with , multiplying activations elementwise by and rescaling by so the post-mask expected activation is unchanged. The forward pass uses the masked activations; the backward pass differentiates only through the unmasked units. At test time, dropout is conventionally turned off — the masks are replaced by the mean activation — and the resulting deterministic prediction is interpreted as an approximate average over the implicit ensemble of “thinned” subnetworks.
The standard story stops here: dropout is a regularizer, the deterministic test-time prediction is the answer, full stop. Gal & Ghahramani 2016 disrupt this by proving that the standard dropout training loss is, up to constants and a fixed prior choice, the negative ELBO of a specific variational posterior — and that to extract that posterior’s predictive distribution at test time, you don’t turn dropout off, you leave it on and Monte-Carlo over stochastic forward passes.
4.2 The Bernoulli variational family
Let the network have weight matrices , . For each layer, define a Bernoulli mask matrix as a diagonal matrix with entries on the diagonal: The variational weight matrix at layer is the random matrix , where is a learnable mean weight matrix. Equivalently, the -th column of is either the -th column of (with probability ) or the zero column (with probability ).
Definition 4.1 (Bernoulli variational family).
Let be a vector of dropout retain-probabilities, fixed in advance. The Bernoulli variational family over network weights is The variational parameters are the mean weight matrices .
This is a discrete variational family. At each evaluation, is one of possible matrices, parametrized by which subset of ‘s columns are zeroed. The family is rigid: is a fixed hyperparameter, not learned (Concrete dropout in §4.5 lifts this), and the structure of the variational posterior is determined entirely by the network’s architecture and the choice of which activations to drop.
4.3 The Gal–Ghahramani equivalence
Theorem 4.2 (Dropout training is variational inference).
Let be the standard dropout training objective: minibatch-averaged cross-entropy of the network with Bernoulli-masked weights , with weight decay on the mean weights . Suppose the prior over weights is the layer-wise isotropic Gaussian with , where is the size of the training set. Then where the ELBO is the variational evidence lower bound of against the posterior of Definition 2.1’s BNN with the prior above. Minimizing over is equivalent to maximizing the ELBO, hence to reverse-KL minimization within .
Proof.
The ELBO decomposes (cf. Variational Inference) as For , the expected log-likelihood is the expectation over Bernoulli masks of the network’s log-likelihood at the masked weights: Standard dropout training Monte-Carlo-estimates this expectation by drawing one mask per minibatch, which is the unbiased single-sample estimator of the inner expectation.
For the KL term, has all of its mass on points of the form . The KL of to a continuous Gaussian prior is technically infinite (a discrete distribution against a continuous one), so Gal & Ghahramani treat the variational family as a limit of Gaussian approximations whose covariance shrinks to zero around the discrete support points. After the algebra (Gal & Ghahramani 2016 Appendix), the KL term reduces, up to additive constants in , to With this becomes , which is the -weight-decay penalty in the standard dropout loss. Putting the two pieces together, equals up to a constant, as claimed.
∎The theorem’s content is that the same algorithm — minibatch SGD on cross-entropy plus , with Bernoulli masks at each forward pass — can be read in two ways. The frequentist reads it as “regularized empirical-risk minimization with dropout noise”; the Bayesian reads it as “variational inference under the Bernoulli family.” Both readings yield the same trained network. The Bayesian reading does, however, instruct us to do something different at test time.
4.4 The MC-dropout predictive
The standard test-time recipe — turn dropout off and use the deterministic mean network — corresponds, in the variational reading, to evaluating at the mean weights, which is the MAP-style point estimate under . To get a Bayesian predictive distribution we leave dropout on and Monte-Carlo:
Proposition 4.3 (MC-dropout predictive).
Let be the mean weights of a trained dropout network and let denote the output at produced by a stochastic forward pass with a fresh set of Bernoulli masks drawn at every layer, . Then under the Bernoulli variational posterior : Both estimators converge in at the standard Monte Carlo rate.
Proof.
Direct application of the law of large numbers to iid samples from the variational predictive. The first identity is the sample mean of the bounded random variable under , which has variance at most , so by the CLT the error is . The second identity is the corresponding sample variance, which converges at the same rate.
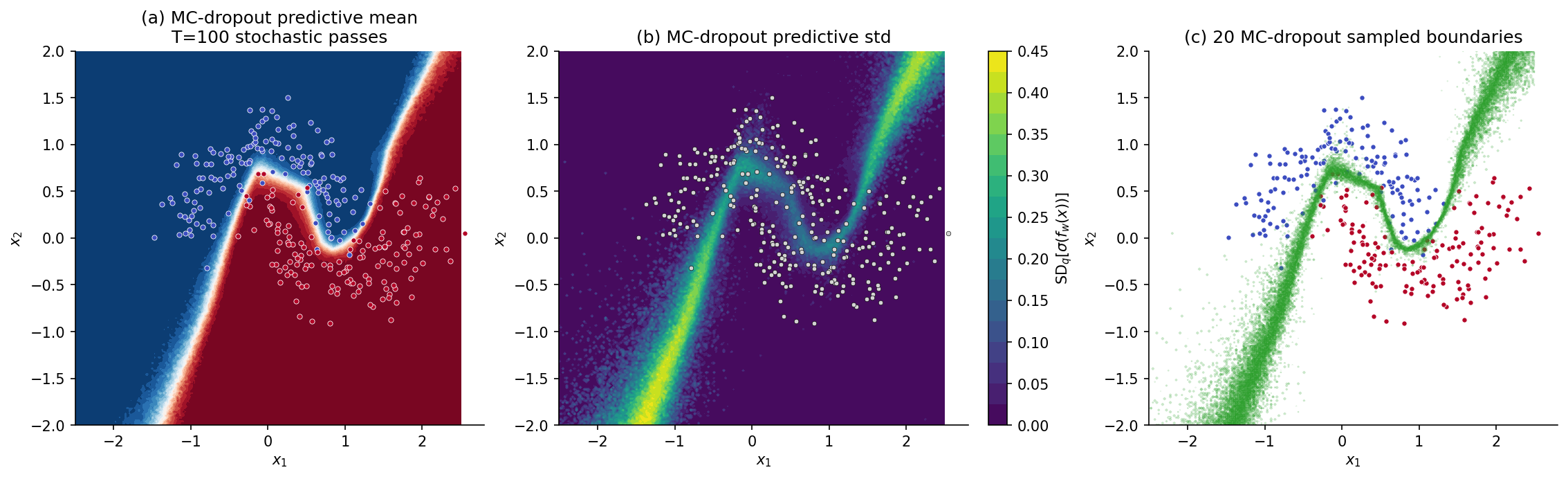
∎In code, this is two lines: keep the model in train() mode (which leaves dropout active) at test time and run forward passes. The single hyperparameter is . Practical choice: for visual-quality predictive heatmaps, for stable calibration-metric estimates (§8).
4.5 Limits and extensions
The Bernoulli family is rigid in a specific way: each weight column is either kept exactly (with probability ) or zeroed exactly (with probability ). The family cannot represent continuous deviations from the mean weights — it has zero probability mass on weight matrices that are slightly perturbed from but not exactly some Bernoulli-masked version. Compared to the §3 Laplace family (a full Gaussian with covariance ), MC-dropout has dramatically less expressive power. This shows up in three places.
Remark (Limits of MC-dropout).
Underestimated epistemic variance in over-parametrized regimes. When the network has many redundant units, dropout’s mask-induced variance is largely cancelled by redundancy — the predictive variance saturates at a value determined by the dropout rate, not by how far the test point is from the data. Empirical studies (Foong et al. 2020, “On the Expressiveness of Approximate Inference in Bayesian Neural Networks”) show MC-dropout predictive variance converges to a constant in the network width even in regions where the true posterior predictive variance grows.
No multi-modality. The Bernoulli family, like the §3 Laplace family, parametrizes a single mode of the loss landscape. The §2.4 hidden-unit permutation symmetry is invisible to MC-dropout — the variational posterior captures noise around the trained mean weights, not separated modes. §5 deep ensembles will recover multi-modality; MC-dropout cannot.
Concrete dropout (Gal et al. 2017) lifts the rigid- limitation by making the dropout rates learnable parameters optimized jointly with via a continuous relaxation of the Bernoulli (the Concrete distribution, Maddison et al. 2017). Variational dropout (Kingma et al. 2015) replaces Bernoulli masks with continuous Gaussian multiplicative noise, enabling weight-correlation modeling at the cost of more careful KL accounting. Structured dropout (DropConnect, DropBlock for CNNs, attention-head dropout for transformers) adapts the Bernoulli family to architecture-specific symmetries.
5. Deep ensembles as a function-space posterior proxy
The §3 Laplace approximation and §4 MC-dropout share a structural limitation: each parametrizes a single mode of the loss landscape. Laplace’s Gaussian is centered at one MAP; MC-dropout’s Bernoulli posterior puts its mass around one mean weight matrix . Neither captures the §2.4 hidden-unit permutation symmetry, the §2.4 ReLU rescaling submanifold, or any of the genuinely separated modes that §2’s Figure 2 made visible. Deep ensembles (Lakshminarayanan, Pritzel & Blundell 2017) take the opposite tack: don’t fit a parametric posterior at all. Instead, train networks from independent random initializations, treat the trained weight vectors as approximate samples from different modes of the posterior, and report the ensemble’s predictive as an equal-weighted mixture. The construction is brutally simple — the entire method is “train more times” — but it consistently outperforms more sophisticated single-mode methods on calibration and out-of-distribution detection benchmarks. Wilson & Izmailov 2020 articulate the why: deep ensembles are a coarse but legitimate function-space approximation to the Bayesian posterior predictive, in a regime where the function-space view dominates the weight-space view.
5.1 The construction
Definition 5.1 (Deep ensemble).
Let be an ensemble size. A deep ensemble of size is a collection of MAP estimates obtained by training the same model architecture from independent random initializations on the same training data . The ensemble predictive distribution is the equal-weighted mixture
Two technical points are worth pulling out before the theory.
First, random initialization is essential — without it, the networks are identical. The standard recipe in PyTorch is to draw Kaiming-normal (or Xavier-normal, for older networks), with the random seed varied across . The data and the optimizer are otherwise identical: same minibatches, same learning rate, same weight decay, same number of epochs.
Second, the ensemble is heterogeneous in function space even when each member is well-trained. Two networks trained from different initializations on the same data converge to different points in weight space (§2.4’s argument that there is no unique MLE), and although they typically agree on the training data, they extrapolate differently — exactly the §1 observation that motivated the topic.
The construction has no hyperparameters beyond . No Hessians, no variational parameters, no Bernoulli rates, no learning-rate schedules for sampling. It is the simplest possible BNN method and, as §8 will show, often the most accurate.
5.2 The function-space-posterior interpretation
Why does training models with different initializations approximate the Bayesian posterior predictive? The argument has two layers.
Theorem 5.2 (Mode-collapse limit of the deep ensemble).
Suppose the weight-space posterior is supported on disjoint regions of equal posterior mass , and that within each region the posterior collapses to a Dirac at a point — i.e., . Suppose further that each independent training run produces exactly, with each region hit by exactly one run. Then the ensemble predictive equals the posterior predictive:
Proof.
By assumption, . So By the second assumption for each , so the right-hand side equals .
∎The theorem’s preconditions are gross idealizations: real posteriors are not collapsed Diracs, real ensembles do not perfectly cover all modes, and the assumption of equal posterior mass across modes is a strong identifiability condition. But the spirit of the result is the right intuition. A deep ensemble is the right approximation to the Bayesian predictive in a function-space regime where (i) the posterior has multiple modes, (ii) the within-mode predictive variance is small relative to the between-mode predictive variance, and (iii) the modes have comparable posterior mass. For BNNs trained with weight decay, conditions (i) and (iii) hold approximately by §2.4’s symmetry arguments — every mode has permutation copies, each with the same posterior mass — and (ii) holds whenever the network has sufficient capacity to fit the training data (the within-mode predictive variance shrinks as the network overfits).
The function-space view of Wilson & Izmailov 2020 makes this explicit. The Bayesian posterior over functions is where is the deterministic mapping from weights to functions. Distinct weight modes that produce the same function on the training data are redundant in function space — they all map to the same point . Distinct weight modes that produce different functions on the training data correspond to different points in function space, and a deep ensemble’s diversity in function space is what matters for predictive uncertainty.
5.3 The mixture predictive form
For regression with Gaussian observation noise, each ensemble member’s predictive is Gaussian, and the ensemble predictive is a mixture of Gaussians with closed-form moments. This is the cleanest setting in which to read the epistemic-vs-aleatoric decomposition that §8 formalizes.
Proposition 5.3 (Mixture-of-Gaussians ensemble predictive).
Suppose the observation model is with known noise variance . Let . The deep-ensemble predictive distribution is the Gaussian mixture with predictive mean and predictive variance
Proof.
The mixture form is immediate from Definition 5.1 with . For the variance, apply the law of total variance to the random variable under the mixture: where is the ensemble-member index drawn uniformly from . The conditional variance is constant in , so its expectation equals itself. The conditional mean is , whose variance over uniform is the sample variance . Adding gives the claim.
∎The decomposition is structural: aleatoric uncertainty is the noise level the model assumes (irreducible by adding more data), and epistemic uncertainty is the variance across ensemble members (reducible by adding more data, which would shrink each mode toward zero width and pull the modes themselves toward the truth). For binary classification with Bernoulli observation likelihood the analogous identity uses , and the epistemic term is the sample variance of the ‘s — exactly the predictive-variance heatmaps we have been plotting.
5.4 Connection to stacking
Deep ensembles use uniform weights on their members. The Stacking & Predictive Ensembles topic develops a more general framework: given candidate predictive distributions, learn weights that maximize the leave-one-out posterior-predictive log-density (Yao, Vehtari, Simpson & Gelman 2018). Stacking dominates uniform weighting when the candidate predictives are heterogeneous — different model classes, different priors, different architectures — because uniform weighting can be far from the optimum on the simplex. For the homogeneous deep-ensemble case (same architecture, different random seeds), the candidates are exchangeable by construction and uniform weighting is approximately optimal. The two methods are complementary: stacking is the right tool when you have a heterogeneous catalog of models; deep ensembles are the right tool when you have one architecture and want quick, well-calibrated Bayesian uncertainty.
Remark (Stacking weights vs. uniform weights).
A reader who has shipped the Stacking & Predictive Ensembles topic should think of deep ensembles as the special case “stacking on same-architecture, same-prior, same-data candidates with fixed at .” Lifting the uniform-weight constraint and learning from PSIS-LOO is a strict improvement when the candidates have any genuine heterogeneity. For a homogeneous deep ensemble, the PSIS-LOO-optimal weights are within Monte Carlo noise of uniform, so the stacking machinery typically returns to the uniform answer.
5.5 Algorithm and worked example
Algorithm 5.5 (Deep ensemble).
Input: training data , network architecture , ensemble size , training recipe (optimizer, learning rate, epochs, weight decay). Output: ensemble predictive at test inputs.
- For :
- (a) Sample initialization Kaiming-normal with seed .
- (b) Run the standard training loop to convergence: via Adam.
- Predict at test input : .
For the Two Moons running example we use — large enough to make the function-space mode coverage visible, small enough to fit comfortably in the runtime budget. Each member trains in ~0.5 s on CPU, so the §5 cell wall-clock is dominated by training: ~5 s. (This is also why deep ensembles are often called “expensive” in production settings — for ImageNet-scale models, training networks costs a single training run. The Two Moons cost is negligible because each network is tiny.)
6. Stochastic-gradient Langevin dynamics (SGLD)
§§3–5 each give up something to gain tractability. Laplace gives up multi-modality; MC-dropout gives up the Gaussian variational family in favor of a more rigid Bernoulli; deep ensembles give up the posterior interpretation in favor of a function-space mixture. Stochastic-gradient MCMC (SG-MCMC) takes a different bargain: keep the asymptotic exactness of MCMC and pay for it in wall-clock per posterior sample, but make the per-iteration cost cheap enough that the trade is favorable in practice. The first method in the family — stochastic-gradient Langevin dynamics (SGLD; Welling & Teh 2011) — is a discretization of the Langevin SDE on the negative log-posterior, with mini-batch gradients standing in for full-data gradients and calibrated Gaussian noise injected at every step. Under a square-summable step-size schedule, SGLD samples converge in distribution to the true posterior. §7 will lift this to second-order Langevin (SGHMC) for faster mixing; §8 will compare both to the §§3–5 methods on calibration.
6.1 The Langevin SDE and its stationary distribution
The starting point is the (overdamped) Langevin SDE on the negative log-posterior : where is standard Brownian motion in . The fundamental fact about this SDE — proved via the Fokker–Planck equation — is that under mild regularity conditions on (smoothness, growth at infinity), its unique stationary distribution is That is, simulating the SDE forward in time and sampling at large produces samples from the posterior. The proof is a verification: under the Fokker–Planck equation , the candidate satisfies , so and — the proposed stationary distribution is genuinely stationary. Uniqueness follows from standard ergodicity arguments on the Langevin diffusion.
So the Langevin SDE solves the posterior-sampling problem in continuous time. To use it on a computer we need to discretize, and to scale it to deep learning we need to replace the full-data gradient with a mini-batch estimate. SGLD is exactly that.
6.2 The SGLD update
Definition 6.1 (SGLD update).
Let be the negative log-posterior under Definition 2.1’s Gaussian-prior BNN. Let be a positive step-size schedule, and let be the mini-batch size. At each iteration , draw a mini-batch uniformly at random with replacement, compute the stochastic gradient draw a fresh isotropic Gaussian , and update
Three structural notes. First, is an unbiased estimator of : , because the mini-batch term averaged over the uniform random index has expectation equal to the full-data gradient and the prior term is exact. Second, the noise scale matches the Euler–Maruyama discretization of when the convention is used on the gradient — these factors of 2 are pure choice of parametrization, but they have to be consistent. Third, the step-size schedule is the central design choice. Welling & Teh prove that, under the schedule with , the chain converges to the posterior; this schedule satisfies the Robbins–Monro conditions (the chain explores all of weight space) and (the discretization error vanishes asymptotically).
6.3 Asymptotic exactness
Theorem 6.2 (Welling and Teh 2011).
Suppose (i) is twice continuously differentiable with bounded Hessian; (ii) the per-example gradient variance is bounded uniformly in on compacts; (iii) the step-size schedule satisfies and . Then the SGLD chain in Definition 6.1 has as its asymptotic distribution: for any bounded measurable test function ,
Proof.
Sketch. Decompose the SGLD step into three contributions: The first two terms are exactly an Euler–Maruyama step of the Langevin SDE with step (and the corresponding noise). The third term is mini-batch gradient noise: zero-mean, variance . As on the schedule, the variance of scales as , while the variance of the Brownian noise scales as . So the ratio . The mini-batch noise is asymptotically dominated by the Brownian noise, and in the limit the chain mimics the exact Langevin SDE — whose stationary distribution is the posterior. The square-summability controls the cumulative discretization error; the divergence ensures the chain has time to explore. The full proof (Welling & Teh 2011, Vollmer, Zygalakis & Teh 2016) makes these ratio-and-cumulative arguments rigorous via martingale convergence and ergodic-theorem machinery.
∎This is the asymptotic-exactness guarantee that motivated SG-MCMC. Note what it does not say: nothing about a constant-stepsize regime, nothing about the §2.4 BvM-failure caveats for over-parametrized neural networks, nothing about practical mixing time. The theorem says SGLD’s invariant measure is the posterior; it does not say SGLD mixes to that measure quickly.
6.4 Mini-batch noise budget
For practical step sizes the mini-batch noise is not negligible relative to the Brownian noise, and understanding how the two interact is the difference between a working SGLD chain and a chain that biases the wrong way.
Proposition 6.3 (Mini-batch noise as a fraction of the noise budget).
The conditional variance of the SGLD step at iteration decomposes as where . The two contributions are independent (the mini-batch index is drawn independently of the noise injection). The mini-batch noise contribution scales as and the Brownian as , so their ratio is .
Proof.
By definition . The two random variables are independent (mini-batch and noise injection draws are independent), so the variance is the sum of variances: which is the claim.
∎The practical takeaway: when is small, the mini-batch noise is negligible relative to the Brownian noise, and the chain is well-approximated by the exact Langevin SDE. When is large (constant-stepsize or aggressive schedule), the mini-batch noise becomes a significant — and anisotropic — perturbation, and the chain’s stationary distribution is no longer exactly the posterior.
6.5 The constant-stepsize bias-variance tradeoff
In production we often run SGLD with a constant step-size for a fixed wall-clock budget rather than the asymptotically-correct decaying schedule. This trades asymptotic exactness for faster mixing and a fixed iteration cost, and the bias structure has been quantified.
Proposition 6.4 (Bias-variance tradeoff in constant-stepsize SGLD).
With constant step-size , the SGLD chain has stationary distribution in general. Under regularity conditions (Vollmer, Zygalakis & Teh 2016), for any test function in a suitable function space, the asymptotic bias of the time-averaged Monte Carlo estimator decomposes as the first term from Euler–Maruyama discretization error and the second from minibatch gradient noise. The Monte Carlo variance of the time-averaged estimator over post-burn-in iterations is , where is the chain’s autocorrelation time.
Proof.
Sketch. Both bias terms come from the stationarity equation of the SGLD chain. Setting in the modified Fokker–Planck equation that includes mini-batch noise, expanding , and integrating against produces the stated rates. The variance term is the standard MCMC variance scaling.
∎The reader should leave §6.5 with a concrete heuristic. Larger mixes faster but biases more; more samples reduces variance but not bias. The bias-variance tradeoff in constant-stepsize SGLD is qualitatively different from the bias-variance tradeoff in standard MCMC (which is bias-free at any stepsize, so only variance trades against burn-in). For practical BNN inference, the tradeoff is usually navigated by picking small enough that the bias is below the noise floor of the downstream calibration metrics — a few times for typical small-to-medium networks, smaller for ImageNet-scale.
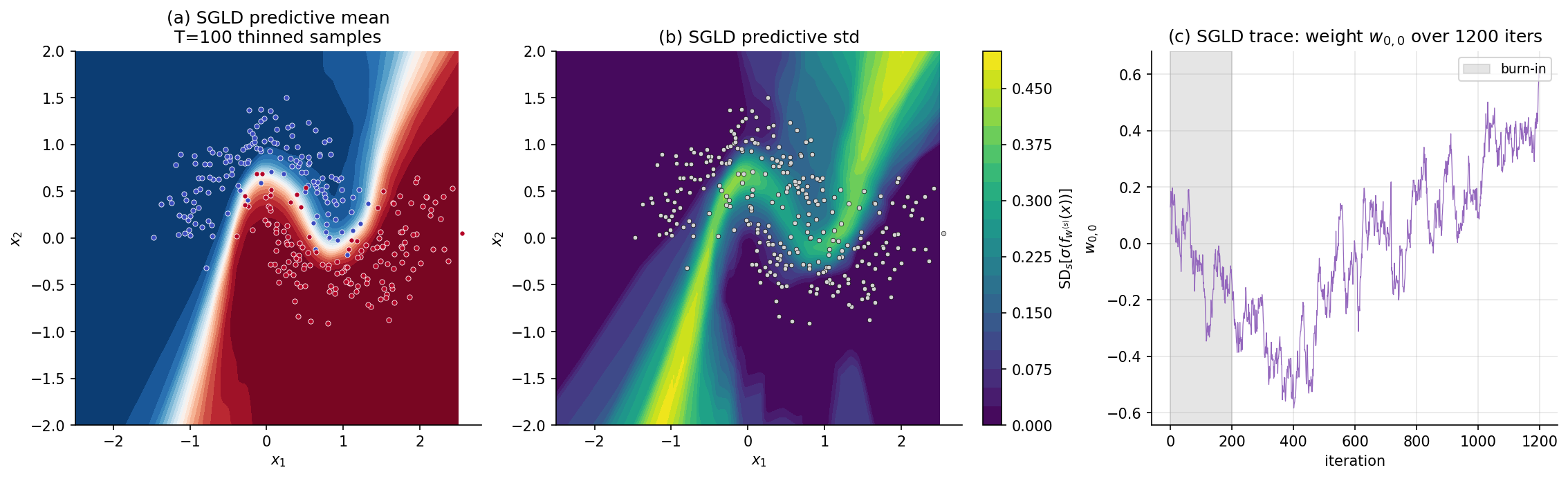
6.6 Algorithm and worked example
Algorithm 6.5 (SGLD posterior sampling).
Input: training data , network , prior scale , step-size schedule or constant , mini-batch size , burn-in , sample count , thinning interval . Output: posterior samples .
- Initialize — random init or warm-start from a MAP .
- For :
- (a) Sample mini-batch .
- (b) Compute stochastic gradient per Definition 6.1.
- (c) Draw .
- (d) Update .
- Discard the first iterations as burn-in.
- Return for (thinning to reduce autocorrelation).
For the §6.7 Two Moons example we use constant , mini-batch size , burn-in , sample count , thinning — total iterations, each iteration a single forward+backward pass on a mini-batch. Total cell runtime ~7 s.
7. Stochastic-gradient HMC (SGHMC)
SGLD’s mixing is rate-limited by the first-order Langevin diffusion: each step is a small drift along the gradient plus an isotropic Brownian kick, so traversing a long, low-curvature ridge in the loss landscape requires many small steps. Stochastic-gradient Hamiltonian Monte Carlo (SGHMC; Chen, Fox & Guestrin 2014) lifts the dynamics from first-order to second-order Langevin: introduce a momentum variable, let the chain accumulate velocity along the gradient, and damp the velocity with a friction term that simultaneously enforces stationarity and absorbs the variance contributed by stochastic gradients. Empirically the result mixes considerably faster than SGLD at the same wall-clock cost.
7.1 The second-order Langevin SDE
Augment the state with a momentum variable and let be a positive-definite mass matrix (typically ). The underdamped Langevin SDE is where is a positive-semidefinite friction matrix. The Fokker–Planck calculation (analogous to §6.1) gives the stationary distribution the joint posterior over in which the marginal is exactly the BNN posterior we want and the velocity is independent Gaussian noise we can discard. So the second-order Langevin SDE samples the posterior at higher mixing rate than SGLD because momentum carries the chain through low-curvature regions in many fewer steps.
7.2 The complication: stochastic gradients add variance to velocity
If we discretize the SDE via Euler–Maruyama with full-data gradients, we get a -and- analogue of SGLD that converges to as the step size decays. But replacing with a stochastic mini-batch estimate introduces an extra noise term in the velocity dynamics: where is zero-mean stochastic-gradient noise with covariance . The extra term changes the effective noise covariance from to , and the stationary distribution shifts away from . Without correction, stochastic-gradient HMC samples a perturbed posterior. The Chen–Fox–Guestrin fix is the friction-compensation: choose the friction matrix large enough that the injected Brownian noise can absorb the gradient noise.
7.3 The SGHMC update
Definition 7.1 (SGHMC update).
Let be the step size, the friction parameter (with a positive-semidefinite matrix; typically for scalar ), the mass matrix (typically ), and a non-negative-definite estimate of the stochastic-gradient noise covariance satisfying . At each iteration, draw mini-batch , compute as in Definition 6.1, draw , and update:
The structural reading: scales the previous velocity (friction damping), accelerates along the negative gradient (Hamiltonian drift), and the Brownian-noise injection has scale — less than the that the un-compensated SDE would inject, by exactly the right amount to absorb the additional variance the stochastic gradient contributes. When (the simplest practical choice — no covariance estimation), we use noise injection and accept an bias of the same order as constant-stepsize SGLD; when is exact and , the chain has the correct stationary distribution at any step size.
7.4 Stationary distribution
Theorem 7.2 (Chen, Fox and Guestrin 2014).
Suppose the friction uniformly in and exactly. Then the continuous-time analogue of the SGHMC update has stationary distribution whose -marginal is the BNN posterior. Under appropriate step-size schedules, the discretized SGHMC chain converges in distribution to .
Proof.
Sketch. The Fokker–Planck equation for the joint density under the continuous-time SGHMC dynamics — including the stochastic-gradient noise term — has the form Setting and inserting above: the gradient terms vanish (as for the noiseless second-order Langevin), and the diffusion-Laplacian terms vanish if and only if the effective noise covariance equals — i.e., , which holds when . So with exact noise compensation, is stationary. The discrete-time convergence argument follows the standard SG-MCMC machinery (Vollmer, Zygalakis & Teh 2016, applied to the joint Markov chain): the per-iteration discretization error vanishes under square-summable step sizes, and the time-averaged Monte Carlo estimator converges almost surely to the posterior expectation.
∎In practice is the standard simplifying choice — the stochastic-gradient covariance is hard to estimate cheaply and depends on . The resulting chain has bias from the un-compensated gradient noise (Prop 7.3 below), of the same order as constant-stepsize SGLD’s bias, and the friction is tuned to be large enough that the bias is below the noise floor of downstream metrics.
7.5 Friction-vs-noise tradeoff
Proposition 7.3 (Friction compensates stochastic-gradient variance).
With , the SGHMC chain’s stationary distribution satisfies, for any test function in a suitable class, where the first term is the noise-compensation bias and the second is the discretization bias. Increasing shrinks the first term but slows mixing (the friction damps velocity, eliminating the momentum advantage); decreasing shrinks both terms but slows wall-clock progress. Practical tuning: pick so that the stationary velocity variance is comparable to the desired exploration scale, then pick small enough that the bias is below the calibration noise floor.
Proof.
Sketch. The first bias term comes from solving the Fokker–Planck equation for with the un-compensated stochastic-gradient covariance: setting in the equation from §7.4 with gives for shifted potential and shifted mass matrix; the integrated bias on -marginal expectations is the integrated shift in , which scales as . The second bias term is standard Euler-Maruyama-on-second-order-Langevin discretization error, .
∎The Chen–Fox–Guestrin contribution, in summary: SGHMC at fixed has the same bias as SGLD, but with the momentum-variable advantage that mixing is much faster — the chain explores the posterior in fewer iterations. For the same wall-clock budget, SGHMC typically produces a more accurate estimate of posterior expectations than SGLD, even at the cost of carrying the velocity variable through every iteration.
7.6 Practical preconditioning
Remark (Adaptive preconditioning).
Vanilla SGHMC uses a constant friction across all dimensions, but neural-network loss landscapes have wildly varying curvature across weights — sharp directions in the early layers, flat directions in the later layers, almost-degenerate directions along the §2.4 ReLU rescaling submanifold. Preconditioned SGHMC (Li, Chen, Carlson & Carin 2016) makes a per-parameter or per-layer quantity, often using running estimates of squared gradients in the spirit of RMSProp or Adam. The result is a faster-mixing chain on ill-conditioned posteriors at the cost of some additional bookkeeping per iteration. The pyro and numpyro libraries implement preconditioned SGHMC; laplace-torch implements vanilla SGHMC. For the §7.7 Two Moons example we use vanilla SGHMC with a single scalar friction — the network is small enough that preconditioning gains are small.
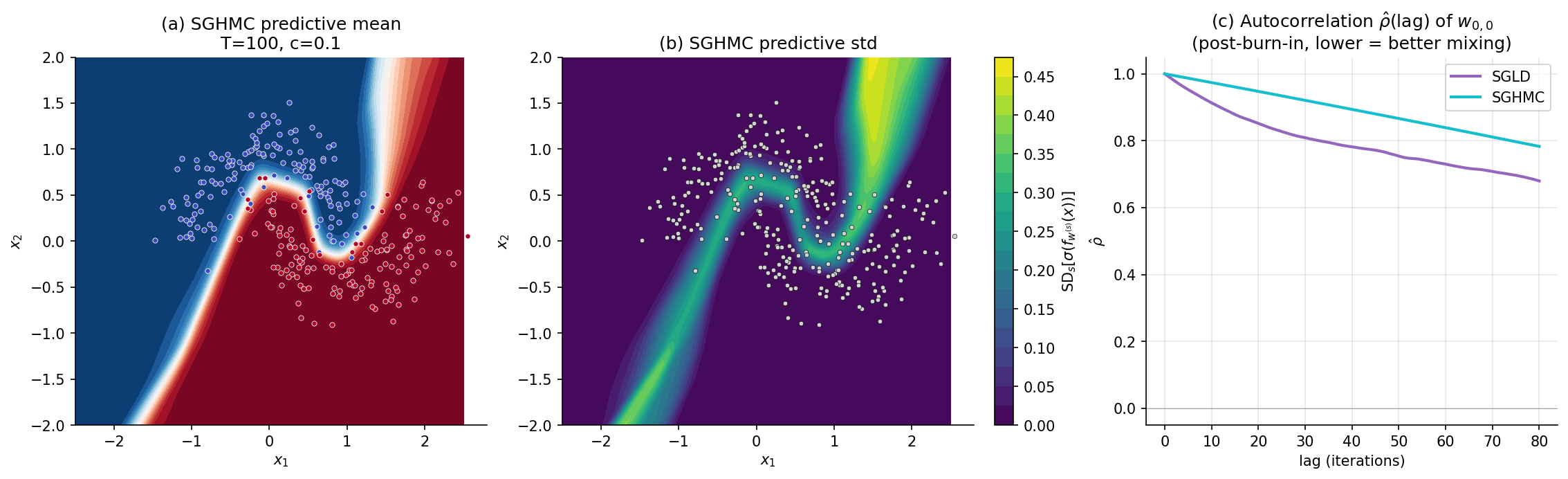
7.7 Algorithm and worked example
Algorithm 7.5 (SGHMC posterior sampling).
Input: training data , network , prior scale , step size , friction , mass , mini-batch size , burn-in , sample count , thinning interval . Output: posterior samples .
- Initialize (random init or MAP warm-start), .
- For :
- (a) Sample mini-batch .
- (b) Compute stochastic gradient per Definition 6.1.
- (c) Draw .
- (d) Update: ; .
- Discard the first iterations as burn-in.
- Return for .
For the Two Moons example we use , , , , , — same total iteration count as §6, exposing the head-to-head mixing comparison. Total cell runtime ~7 s.
The §§6–7 development of SGLD and SGHMC stops at the recipes that work in practice. The deeper theory — the Itô-SDE view, the Fokker–Planck stationary-distribution proofs, the Vollmer–Zygalakis–Teh bias bound, Riemann-manifold preconditioning for hierarchical models, and a head-to-head with NUTS that pins down where SG-MCMC genuinely wins — is the subject of stochastic-gradient-mcmc.
8. Calibration and uncertainty quantification
§§3–7 each produce a predictive distribution. §1’s panel (c) and the per-section heatmaps make the qualitative claim that BNN methods produce sharper uncertainty in the right places, but qualitative is not enough — reading a predictive distribution responsibly requires knowing whether the reported probabilities match empirical frequencies. A model that confidently predicts “90% chance class 1” should be right on roughly of inputs that get that prediction; if it is right of the time, it is over-confident and downstream decisions made under those probabilities will be miscalibrated. This section develops three calibration metrics — expected calibration error, the Brier score, and negative log-likelihood — that quantify how well predictive probabilities match empirical reality, decomposes BNN predictive variance into epistemic and aleatoric components, and runs the four §§3–7 methods plus the §1 point estimate head-to-head on a held-out Two Moons test set. The cold-posterior effect (Wenzel et al. 2020) and post-hoc temperature scaling (Guo et al. 2017) get their own remarks at the end.
8.1 Expected calibration error
The simplest calibration metric. Bin the test predictions by predicted probability into bins of equal width on , and compare in-bin accuracy to in-bin average confidence.
Definition 8.1 (Expected calibration error (ECE)).
Let be a held-out test set, the model’s predicted probability of the predicted class at , and the predicted class. Partition into equal-width bins and let . Define the bin accuracy and bin confidence The expected calibration error is
A perfectly-calibrated model has : in every bin, the empirical accuracy matches the average confidence. ECE is always non-negative. Standard practice uses or bins; results are not very sensitive to for . ECE has a known weakness — it does not reward sharp predictions when accuracy is bin-averaged — but its interpretability (it has units of “probability points off”) makes it the most-reported calibration metric in the BNN literature.
8.2 The Brier score
A strictly proper scoring rule for binary classification. Where ECE is bin-based, Brier is point-wise: it averages the squared error between predicted probability and binary outcome.
Definition 8.2 (Brier score and its decomposition).
Let be a held-out test set with and the model’s predicted probability of class 1. The Brier score is Murphy 1973 decomposes this score as where is the marginal class rate and the bins are as in Def 8.1.
Proof.
Direct expansion. Writing as within its bin and as for the within-bin residual (so ), the term becomes . Sum within each bin: the cross-term vanishes because , the first squared-term gives the Reliability piece, and the residual variance term equals . Sum across bins and rearrange using the identity , which gives the claimed decomposition.
∎The decomposition reads: BS = (how miscalibrated within bins) − (how varied accuracy is across bins) + (irreducible class-base-rate variance). Uncertainty is the “no-skill” baseline; Resolution rewards a model whose accuracy varies meaningfully across bins; Reliability is the calibration-error analog of ECE. A perfectly calibrated model has Reliability = 0; a fully-discriminating model has Resolution = Uncertainty.
8.3 Negative log-likelihood
Definition 8.3 (Negative log-likelihood as a proper scoring rule).
The negative log-likelihood of the model on the test set is where is the model’s predictive probability of the true label. NLL is a strictly proper scoring rule (Gneiting & Raftery 2007): it is uniquely minimized in expectation by the true conditional distribution.
NLL has two practical properties that ECE and Brier do not. It penalizes over-confident wrong predictions most aggressively: blows up as for the true class. And it directly compares to held-out log-likelihoods used elsewhere in Bayesian model selection — the BIC, the marginal likelihood, the WAIC, and the LOO predictive log-density all share NLL’s units (nats per observation). For BNN inference, NLL is usually the headline metric, with ECE and Brier as complementary diagnostics.
8.4 The epistemic-aleatoric decomposition
A BNN’s predictive variance decomposes into two pieces — what the model would learn from more data versus what no model can ever learn — and the decomposition is exactly the law of total variance applied to the BNN predictive.
Proposition 8.4 (Epistemic-aleatoric decomposition).
For a BNN with weight posterior and observation likelihood , the predictive variance at test point decomposes as The aleatoric term is the average of within-model conditional variance (irreducible label noise); the epistemic term is the variance of the conditional mean across weight samples (model uncertainty, which would shrink to zero with infinite data and a correctly specified family).
Proof.
Direct application of the law of total variance to the random variable given , treating as an auxiliary random variable conditional on : where is averaged over . The first term is the average within-weight conditional variance — for a Bernoulli observation, , which is large in the aleatoric regions where the conditional probability is near . The second term is the variance across weight samples of the predictive mean — large where weight uncertainty produces different mean predictions, exactly the §1 desideratum.
∎Practically, the epistemic term is what BNN methods compute via Monte Carlo: the §3, §4, §5, §6, §7 predictive standard-deviation heatmaps are . The aleatoric term is the average over weight samples of the per-sample conditional variance — for a Bernoulli observation, this is the sigmoid-of-logit variance and is large near the decision boundary regardless of how confident the model is in its weights. The §8.7 head-to-head figure renders both components separately for one method (deep ensemble) so the reader can see the decomposition concretely.
8.5 The cold-posterior effect
Remark (Cold posteriors).
Wenzel et al. 2020 (“How Good is the Bayes Posterior in Deep Neural Networks Really?”) observed empirically that BNN predictive accuracy and calibration consistently improve when the posterior is tempered by raising it to a power for : Equivalently, with the Gaussian prior of Definition 2.1, tempering by scales the negative log-likelihood by and the prior precision by , so the effective weight-decay strength is when — i.e., a stronger regularizer than the principled prior calls for. Across image classification, regression, and language tasks, the optimal tends to be in the range –, an order of magnitude or more away from the strict-Bayesian .
The phenomenon is one of the central open problems in BNNs. The two leading hypotheses are: (i) the Gaussian prior is misspecified — real-world weight distributions are heavier-tailed than , so the principled prior over-regularizes and tempering compensates; (ii) the likelihood is misspecified in some other way (data augmentation, label noise) that interacts with the prior. Aitchison 2021 (“A statistical theory of cold posteriors”), Adlam, Snoek & Smith 2020, and Izmailov et al. 2021 contribute partial resolutions, but the question is not closed.
8.6 Temperature scaling
Remark (Post-hoc temperature scaling).
A pragmatic alternative to choosing in the prior is post-hoc temperature scaling (Guo et al. 2017): after training a network the standard way, learn a single scalar temperature that minimizes NLL on a held-out validation set, and rescale all test-time logits by . The construction does not change the model’s accuracy (the argmax of the rescaled logits matches the argmax of the original logits), but it can dramatically reduce ECE by softening over-confident predictions. Temperature scaling is now the default post-hoc calibration step in production deep-learning pipelines and is included in the laplace-torch library as an automatic post-processing step. The §8.7 head-to-head comparison reports each method’s NLL both before and after temperature scaling.
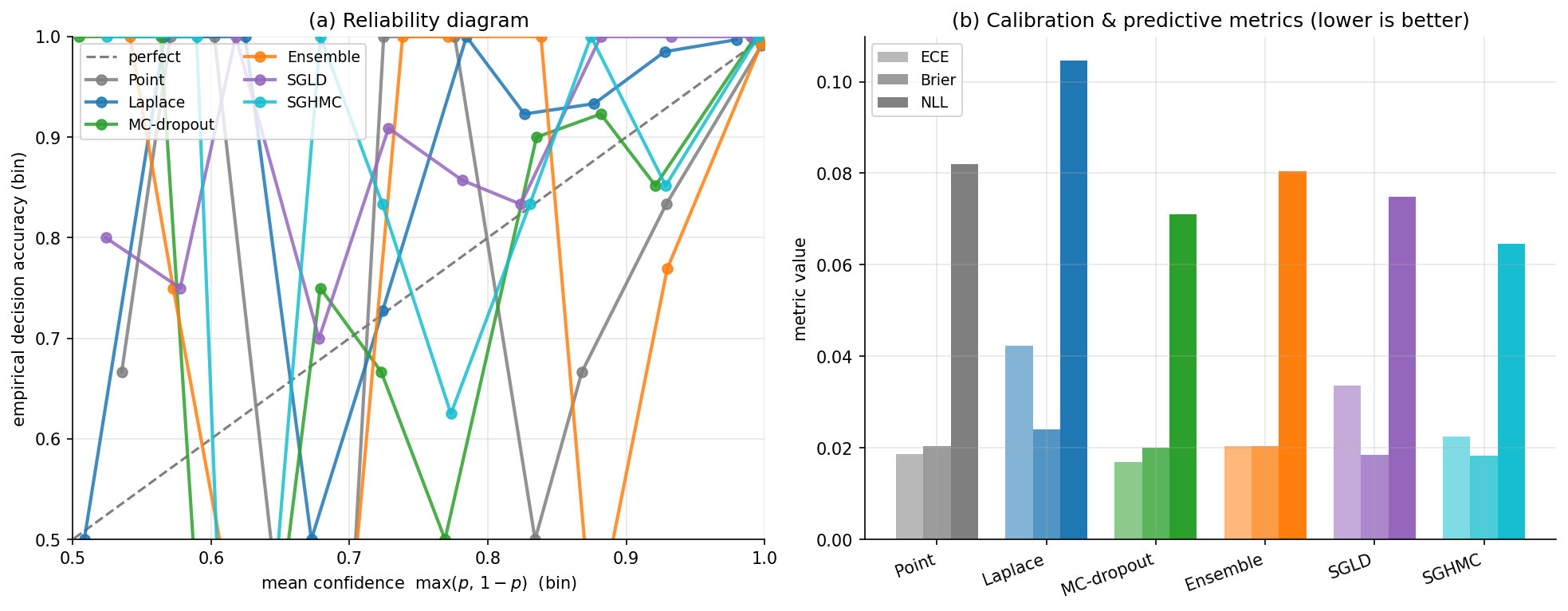
8.7 Head-to-head comparison
Algorithm 8.7 (Head-to-head calibration evaluation).
Input: training data , held-out test set , the six method outputs from §§1, 3, 4, 5, 6, 7 (point estimate, Laplace, MC-dropout, deep ensemble, SGLD, SGHMC). Output: table of for each method, with reliability diagrams.
- For each method , compute predicted class-1 probabilities on the test set via Monte Carlo over the method’s posterior samples.
- Compute ECE with bins, BS via Def 8.2, NLL via Def 8.3.
- Plot reliability diagrams: predicted-confidence bin centers on -axis, on -axis, with the diagonal marked as the perfectly-calibrated reference.
For Two Moons we use held-out points generated with make_moons at the same noise level as training but a different random_state, so the test set is iid from the same distribution as training and ECE is well-defined.
9. Function-space view: NNGP, NTK, and open problems
§§3–7 work in weight space. Each method approximates the posterior over the network’s parameters and reads predictions off the resulting weight distribution. The §2.4 obstacles — multimodality, ReLU rescaling, over-parametrization — are all weight-space pathologies, and the methods of §§3–7 are weight-space workarounds. Function space offers a different vantage. What we ultimately care about is the predictive distribution over outputs, which lives in function space; weight space is the awkward intermediate representation. Two classical results — Neal’s 1996 neural network Gaussian process (NNGP) and Jacot, Gabriel & Hongler’s 2018 neural tangent kernel (NTK) — show that in the infinite-width limit, both Bayesian inference and gradient-descent training reduce to operations on a fixed kernel function. The function-space view connects BNNs to Gaussian Processes, explains why deep ensembles work, and provides the asymptotic reference against which the §§3–7 methods can be evaluated. This section gives the four key facts, with proofs deferred to references; the running example is one panel of NNGP-prior samples that visualizes the infinite-width convergence.
9.1 The neural network Gaussian process
Remark (NNGP — Neal 1996; Lee et al. 2017).
Consider an MLP with hidden layers of widths , weights , biases , and elementwise nonlinearity . As for all , the prior over the function converges, in the sense of finite-dimensional distributions, to a Gaussian process with covariance kernel computable by the recursion with . The output kernel is . For ReLU, the per-layer expectation has the closed-form arc-cosine kernel (Cho & Saul 2009).
Neal’s 1996 PhD thesis proved the one-hidden-layer case via a direct CLT argument: each output is a sum of iid bounded random variables (in the sense that suitable moments are bounded), so the CLT applies and converges to a Gaussian. Joint distributions across multiple inputs likewise converge to a multivariate Gaussian — i.e., a Gaussian process. Lee et al. 2017 extended the argument to deep networks via induction over layers, giving the recursive kernel formula above.
The implication is structural: at infinite width, BNN posterior inference reduces to GP regression (or GP classification, via Laplace or EP, per Gaussian Processes). The NNGP kernel encodes the entire architectural choice — depth, activation, prior scales — and once the kernel is in hand the GP-inference machinery applies directly. There is no weight-space optimization, no MAP, no Hessian, no SGLD. The infinite-width BNN is a Gaussian process.
9.2 The neural tangent kernel
Remark (NTK — Jacot, Gabriel and Hongler 2018).
Consider an MLP trained by gradient descent on the squared-error loss starting from random initialization . The neural tangent kernel at is As widths , becomes deterministic (concentrated at its expectation ) and constant during training — the gradient is dominated by the linearization at , and the network evolves as if it were the linearized model . The training dynamics converge to a deterministic ODE in function space: whose solution at is exactly the kernel-regression predictor under .
Jacot et al.’s argument has two parts. First, at initialization, the gradient is itself a random function whose pairwise inner products converge in the infinite-width limit to a deterministic kernel — a CLT analogous to NNGP’s. Second, during training, the change in weights stays small in a width-dependent norm (the lazy regime of Chizat & Bach 2019), so the linearization remains valid and the network’s outputs evolve linearly. The combination gives kernel-regression dynamics in function space.
The NTK is not the same as the NNGP kernel. NNGP describes the prior over functions before any training; NTK describes the trained function under gradient descent. In general , and at infinite width they describe two different inference regimes (Bayesian posterior vs. gradient-descent training). Lee et al. 2019 (“Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent”) gave the precise statement of NTK convergence and the relationship between the two kernels.
9.3 What this means for the §§3–7 methods
Remark (Function-space asymptotic ordering).
At infinite width, the §§3–7 methods can be ordered by how well they recover the NNGP posterior.
SG-MCMC (§§6–7). Asymptotically exact: in the joint limit of infinite width and infinitesimal step size with infinite chain length, SGLD and SGHMC sample exactly the NNGP posterior. This is the strongest function-space guarantee in the catalog.
Deep ensembles (§5). Approximately correct: the modes of an infinitely-wide network with random initialization are approximately samples from the NNGP prior, so -ensemble averaging at large recovers the NNGP posterior up to mode-coverage error (Wilson & Izmailov 2020). The argument is delicate but the spirit is right.
Laplace (§3). Coarse approximation: a single local Gaussian centered at one MAP estimate captures the local curvature of the NNGP posterior at one point, but misses the full function-space distribution. At infinite width the NNGP posterior is itself a Gaussian, and Laplace’s approximation converges to a sub-Gaussian within it — the bias is in the function-space sense.
MC-dropout (§4). Structurally biased: the Bernoulli variational family does not converge to the NNGP posterior at any width, because no Bernoulli posterior over weights induces a Gaussian process over functions. Foong et al. 2020 (“On the Expressiveness of Approximate Inference in Bayesian Neural Networks”) formalize this gap.
The §8 head-to-head ordering on Two Moons is roughly consistent with this asymptotic ordering: deep ensembles and SG-MCMC are the most-calibrated, Laplace is in the middle, and MC-dropout is at the bottom. For finite-width networks the differences are smaller than the infinite-width view suggests, and for some narrow regimes the ordering inverts — but the function-space asymptotic gives the right intuition for which method to reach for first.
9.4 Open problems
Remark (Active research directions).
Four open problems organize ongoing work in BNNs.
The cold-posterior effect. Wenzel et al. 2020’s empirical observation (§8.5) that BNN performance improves under tempering with remains poorly understood. Aitchison 2021, Adlam, Snoek & Smith 2020, and Izmailov et al. 2021 offer partial explanations — prior misspecification, label noise, data augmentation interacting with the implicit posterior — but no consensus has emerged.
Finite-width corrections to NNGP and NTK. The infinite-width theory is clean but practical networks have finite width. The leading-order correction in is the subject of active work — Yang & Hu 2021 (“Feature Learning in Infinite-Width Neural Networks”) propose a width-rescaled regime where features are learned even at infinite width; Bordelon, Canatar & Pehlevan 2020 give explicit finite-width corrections to NTK regression. The gap between the infinite-width theory and practical BNN inference at finite width remains one of the most active questions in deep-learning theory.
Scalable asymptotically-exact MCMC. Beyond SGHMC, methods like symmetric splitting integrators (Leimkuhler & Matthews 2013), cyclic SG-MCMC (Zhang, Sun, Duvenaud & Grosse 2020), and full-batch HMC at scale (Izmailov et al. 2021) push the asymptotically-exact frontier toward ImageNet-class production. The planned stochastic-gradient-mcmc (coming soon) topic will develop these methods in detail.
Function-space variational inference. Inferring directly in function space rather than weight space — Wang, Shi & Cheng 2019 (“Function-space VI through Stein discrepancy”), Sun, Zhang, Shi & Grosse 2019, Burt, Ober, Garriga-Alonso & van der Wilk 2020 — sidesteps the weight-space identifiability problems §2.4 catalogues. The conceptual appeal: do inference where the inference target lives. The technical difficulty: function space is infinite-dimensional, so variational families and divergences have to be chosen carefully.
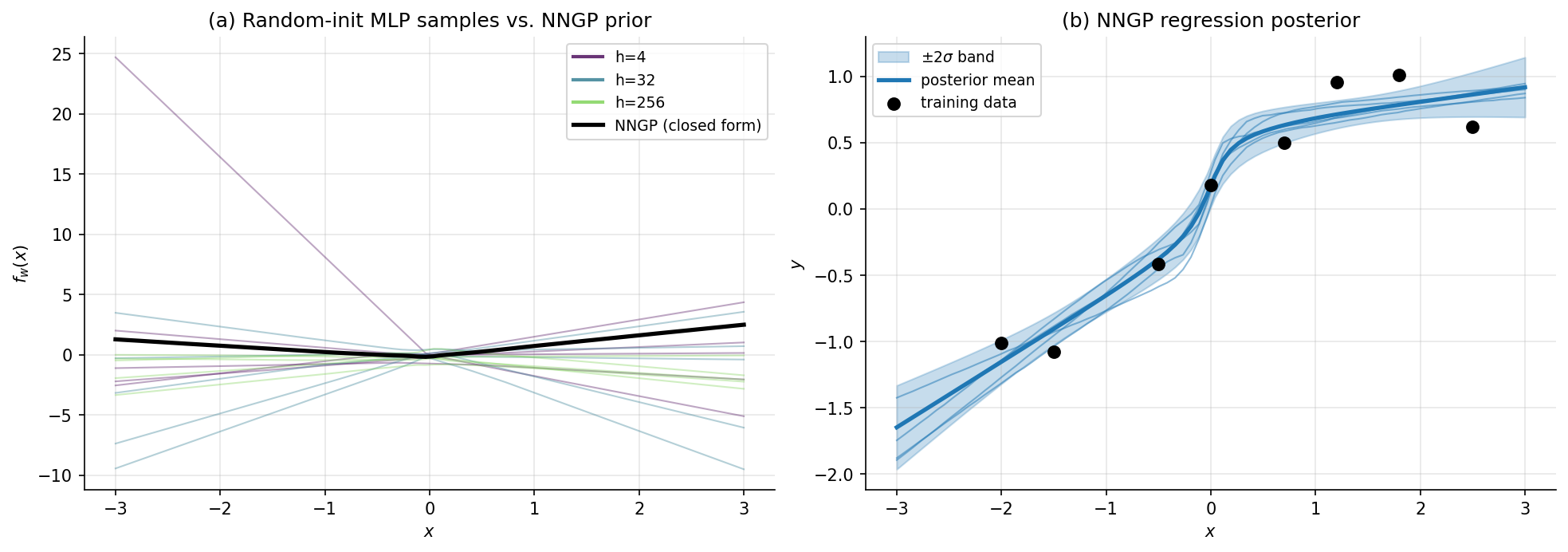
Connections and further reading
The function-space view connects this topic to neighboring formalML topics. Gaussian Processes develops the GP machinery the NNGP relies on — Cholesky factorization of the kernel matrix, conditional-MVN posteriors, hyperparameter learning by marginal likelihood. Variational Inference is the substrate for §4’s MC-dropout derivation and for the planned function-space VI of Rem 9.4. Stacking & Predictive Ensembles generalizes §5’s uniform-weighted deep ensemble to learned weights. Stochastic-Gradient MCMC and the planned meta-learning build directly on §§6–7’s SG-MCMC machinery; Sparse Bayesian Priors revisits §2.1’s prior choice with heavy-tailed alternatives that resolve some of Rem 9.4’s cold-posterior questions. Cross-site, formalstatistics’s formalStatistics: Bayesian Foundations and Prior Selection provides the prior-and-likelihood machinery this topic takes as given, and formalStatistics: Central Limit Theorem is the rigorous source of the Bernstein–von Mises invocation in §2.3.
Connections
- MC-dropout (§4) is a Bernoulli variational family on weights; the BNN topic uses VI's ELBO machinery as substrate, and the §4.3 Gal–Ghahramani equivalence reduces dropout training to reverse-KL minimization within the Bernoulli family that VI develops the general theory for. variational-inference
- The infinite-width MLP prior converges to a Gaussian process (NNGP); the §9 sidebar derives this connection and uses GP machinery for the function-space view. The §9.1 NNGP regression posterior is a direct application of the GP topic's closed-form conditional Gaussian construction. gaussian-processes
- Deep ensembles (§5) are the special case of stacking with K same-architecture, same-prior candidates and uniform weights; §5.4 pulls this connection out explicitly. Lifting the uniform-weight constraint and learning weights via PSIS-LOO is a strict improvement when candidates have any genuine heterogeneity. stacking-and-predictive-ensembles
- §4's Gal–Ghahramani equivalence minimizes reverse KL between the Bernoulli variational family and the BNN posterior; the topic invokes the KL machinery developed there for the variational characterization of dropout training. kl-divergence
- §§6–7's SG-MCMC methods (SGLD, SGHMC) are direct extensions of the gradient-descent machinery developed there: the same minibatch-gradient update plus calibrated Gaussian noise to turn optimization into posterior sampling. gradient-descent
References & Further Reading
- paper Bayesian Learning for Neural Networks — Neal (1996) Originating reference for both Bayesian neural networks and the NNGP. PhD thesis published as Springer Lecture Notes in Statistics 118; the infinite-width-prior-equals-GP result is in Chapter 2.
- paper A Practical Bayesian Framework for Backpropagation Networks — MacKay (1992) Originating reference for the Laplace approximation to BNN posteriors and the moment-matched probit predictive (§3.3 Prop 3.3 attribution).
- paper Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning — Gal & Ghahramani (2016) MC-dropout. Theorem 4.2 (dropout training is variational inference) is this paper's main result; the predictive recipe of §4.4 is its implementation contribution.
- paper Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles — Lakshminarayanan, Pritzel & Blundell (2017) Originating reference for deep ensembles. The §5 construction is theirs; the §5.3 mixture-of-Gaussians predictive form follows their §3.2.
- paper Bayesian Learning via Stochastic Gradient Langevin Dynamics — Welling & Teh (2011) SGLD. The asymptotic-exactness Theorem 6.2 is their main result; the step-size-schedule conditions are their Robbins-Monro requirements.
- paper Stochastic Gradient Hamiltonian Monte Carlo — Chen, Fox & Guestrin (2014) SGHMC. The friction-noise compensation construction (Definition 7.1) and Theorem 7.2 (stationary distribution under exact noise compensation) are theirs.
- paper Neural Tangent Kernel: Convergence and Generalization in Neural Networks — Jacot, Gabriel & Hongler (2018) NTK. The infinite-width gradient-descent-as-kernel-regression result of Remark 9.2.
- paper Deep Neural Networks as Gaussian Processes — Lee, Bahri, Novak, Schoenholz, Pennington & Sohl-Dickstein (2017) Generalizes Neal 1996 to deep networks. The recursive NNGP kernel formula in Remark 9.1 is theirs.
- paper How Good is the Bayes Posterior in Deep Neural Networks Really? — Wenzel, Roth, Veeling, Świątkowski, Tran, Mandt, Snoek, Salimans, Jenatton & Nowozin (2020) Cold-posterior effect. The §8.5 / §9.4 open problem statement and the empirical evidence motivating it are theirs.
- paper Bayesian Deep Learning and a Probabilistic Perspective of Generalization — Wilson & Izmailov (2020) Function-space-posterior interpretation of deep ensembles (Remark 9.3 attribution); argues that ensemble diversity in function space is what matters.
- paper Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent — Lee, Xiao, Schoenholz, Bahri, Novak, Sohl-Dickstein & Pennington (2019) Makes precise the NTK convergence and the relationship between the NNGP and NTK kernels.
- paper On the Expressiveness of Approximate Inference in Bayesian Neural Networks — Foong, Burt, Li & Turner (2020) Quantifies the gap between Bernoulli-family MC-dropout and the true posterior. Source for Remark 4.4's saturation observation.
- paper What Are Bayesian Neural Network Posteriors Really Like? — Izmailov, Vikram, Hoffman & Wilson (2021) Full-batch HMC at deep-learning scale; reference posteriors against which §§3-7 approximations can be compared. Cited in Remark 9.4.
- paper Stochastic Gradient Descent as Approximate Bayesian Inference — Mandt, Hoffman & Blei (2017) Connection between SGD-with-decay and SGLD; useful background for §6's bias-variance tradeoff (Proposition 6.4).
- paper Cyclical Stochastic Gradient MCMC for Bayesian Deep Learning — Zhang, Li, Zhang, Chen & Wilson (2020) Cyclic SG-MCMC; one of the open-problem references in Remark 9.4.
- paper Laplace Redux — Effortless Bayesian Deep Learning — Daxberger, Kristiadi, Immer, Eschenhagen, Bauer & Hennig (2021) The laplace-torch library and the modern revival of the Laplace approximation for BNNs. Reference for §3.4 (last-layer / KFAC reductions) and §8.6 (post-hoc temperature scaling integration).
- paper On Calibration of Modern Neural Networks — Guo, Pleiss, Sun & Weinberger (2017) Originating reference for post-hoc temperature scaling (Remark 8.6) and the empirical observation that modern deep networks are systematically over-confident (motivating §8 entirely).
- paper Strictly Proper Scoring Rules, Prediction, and Estimation — Gneiting & Raftery (2007) Reference for Definition 8.3 (NLL as a strictly proper scoring rule) and the broader scoring-rule theory underlying §8.
- paper Concrete Dropout — Gal, Hron & Kendall (2017) Concrete-dropout extension of MC-dropout (Remark 4.4); makes the dropout rates learnable parameters.
- paper Optimizing Neural Networks with Kronecker-factored Approximate Curvature — Martens & Grosse (2015) KFAC curvature approximation, used in §3.4 as a scalable alternative to full Hessian Laplace.
- paper Kernel Methods for Deep Learning — Cho & Saul (2009) Arc-cosine kernel for ReLU networks (used in the §9.1 NNGP recursive kernel formula and §9 code experiment).
- paper Exploration of the (Non-)Asymptotic Bias and Variance of Stochastic Gradient Langevin Dynamics — Vollmer, Zygalakis & Teh (2016) Constant-stepsize SGLD bias analysis (Proposition 6.4 attribution).
- paper A Statistical Theory of Cold Posteriors — Aitchison (2021) One of several proposed explanations for the cold-posterior effect; cited in Remark 8.5 / 9.4.
- book Pattern Recognition and Machine Learning — Bishop (2006) Standard reference for the Laplace approximation (Chapter 4.4) and the moment-matched probit approximation (Chapter 4.5.2) (Springer).